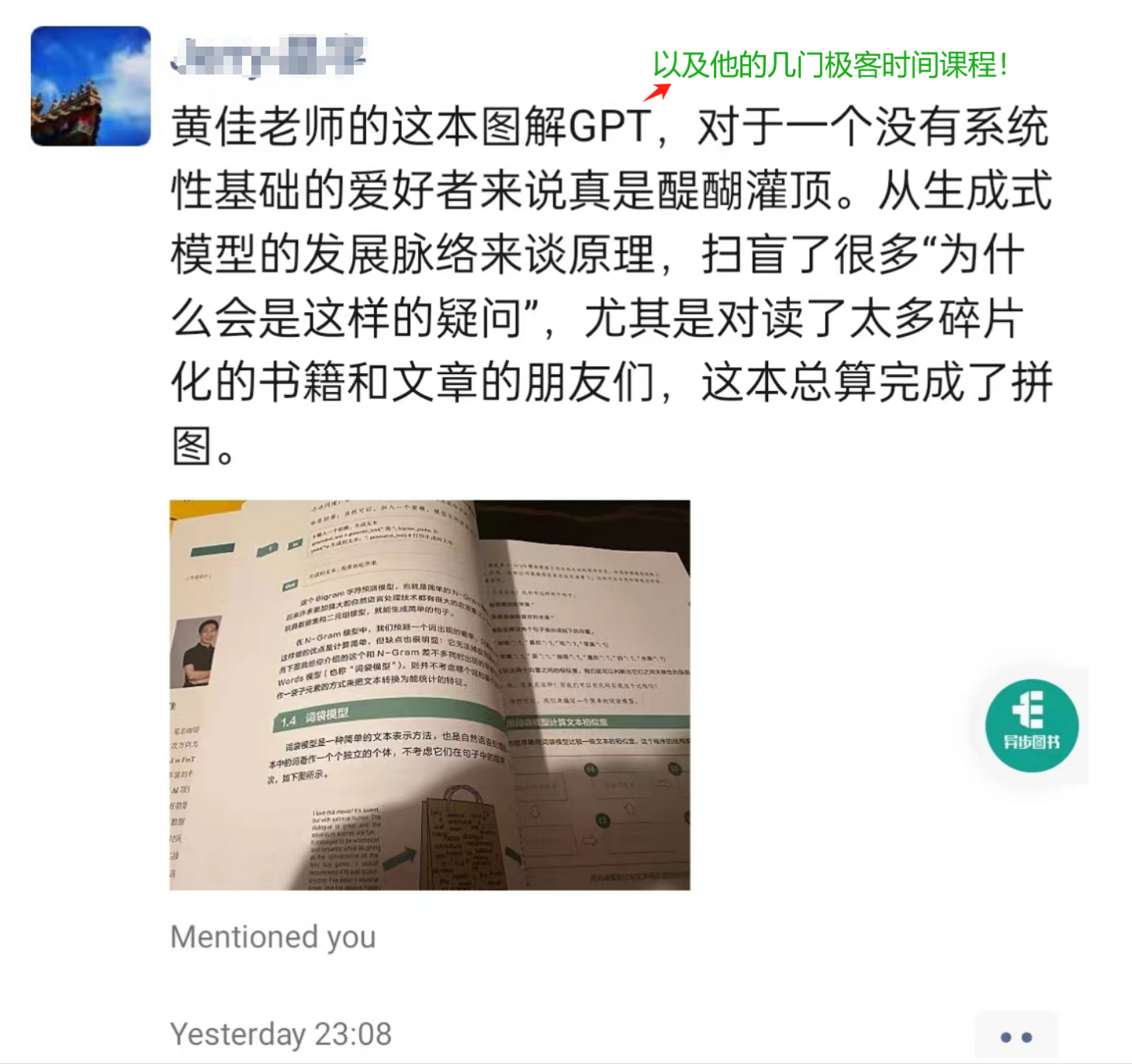
你好,我是黄佳。你可以叫我“佳哥”或者“咖哥”。如果你是极客时间的老朋友,那我们彼此也许已经相当熟悉了。如果你是刚刚来到极客时间这个出色的技术学习平台,我就先介绍一下我自己。
我在新加坡科技研究局做大模型的科研和落地应用的工作。在工作中,我们的使命是将激动人心的科研成果转化为企业的创新动力,为商业世界带来可见的变革和成长。在写作和课程设计中,我的心愿则是通过文字把复杂的技术世界变得温暖,使读者能够轻松掌握深奥的概念,并在求知的旅途中感受到陪伴和指导——揭开技术的神秘面纱的同时,让学习变成一种享受。
目前,我的代表作品是极客时间的课程《LangChain 实战课》《零基础实战机器学习》等,书籍《大模型应用开发:动手做 AI Agent》《GPT 图解:大模型是怎样构建的》《零基础学机器学习》等。非常有幸,这些作品得到了不少朋友的认可,这种认可鼓励着我一次次挑战自我,持续的学习并创作出新的内容。
读者的鼓励永远是我创作的动力
为什么大模型应用开发如此重要
既然你打开了这篇文章,那么,你一定对大模型应用开发充满了兴趣和期待。在开篇词中,我想摈弃一切花俏和冗余的东西,开门见山地说说,什么是大语言模型,什么是大模型应用开发,为什么大模型应用开发如此重要。
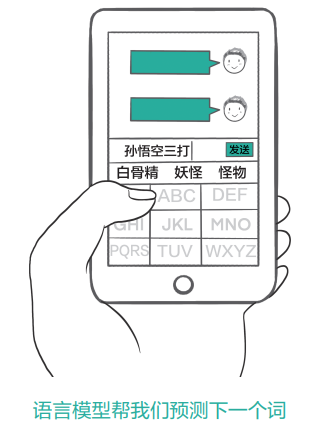
首先,大语言模型是一种将文本映射到文本的函数。给定一个输入文本字符串,大型语言模型会预测接下来最有可能出现的文本。这些模型通过在海量文本数据上进行训练来最小化预测错误。
神奇的事情是,尽管这些模型只是以一种相对简单的方式训练出来的,但它们却能够从海量数据中学习到丰富的语言知识和世界知识。通过对大量不同领域、体裁和语言的文本进行训练,这些模型具备了惊人的泛化能力。它们不仅掌握了语法、句法等基本语言规则,还能够理解语义、上下文、因果关系等深层次概念。这种强大的语言理解和生成能力使得大语言模型能够完成从拼写纠错、语法修正到问答、对话、写作、编程等一系列复杂的任务。
而这些任务,以前是只有我们人类才能够完成的,而且,这些任务的实现往往和复杂推理相关。因此,人们惊讶地发现,大语言模型很可能让我们人类第一次创造出了比自己还要聪明、还要高效的智能体,大语言模型很可能让我们人类第一次摸到了通用人工智能(AGI)的门槛。
上面,就是为什么 ChatGPT 一夜爆红,而且从 2022 年底一直火到了 2024 年的底层逻辑。而且,即使有新的大语言模型(如 Claude3-Opus)的能力超过 GPT-4,GPT-5 也会继续奋起直追,而大语言模型也会一直火下去。

LLM 排行榜
和大语言模型一同登场的,还有其它 AIGC(AI-Generated Content)模型,如图像生成模型 Mid-Journey、DALL-E、Stable Diffusion,音频生成模型 AudioLM 等。它们同样通过在海量数据上进行训练,实现了令人震惊的内容生成能力。这些模型统称为大模型。
与之前的专做人脸识别、专做目标检测、专门学下围棋的 AI 系统不同,大模型展现出了一定程度的通用智能特征,如强大的学习能力、知识迁移能力和随机应变能力,人工智能正在从专用智能(Narrow AI)向通用智能(AGI)迈进。它们能够在没有显式设计和训练的情况下,利用学到的海量知识和经验,去解决全新的复杂问题。随着大模型能力的不断提升以及更多领域大模型的涌现,人类将进入一个全新的智能时代。
在大模型的推动下,人工智能正在加速与各行各业融合,催生出大量创新应用,在教育、金融、医疗、法律、设计等诸多领域大显身手,提升了人类的生产力和创造力,带来了一系列颠覆性变革。
而我所说的大模型应用开发,就是通过提示工程或者微调的方式,发掘利用大模型的能力,让它成为各种创新应用的润滑剂:你可以下载开源模型,部署到本地进行推理,完成任务;你也可以调用商业大模型(如 GPT-4 和 Claude)的 API,构建新的应用程序,或者把大模型给回的结果无缝集成到现有的业务流程中。
大模型应用开发代表了人工智能技术的未来方向,有望彻底改变人类认知和改造世界的方式,不仅能够激活效率层面创新,甚至很有可能会引出崭新的商业模式。那我们作为程序设计人员,当然需要成为最了解大模型的人,成为最了解大模型应用开发的人。
包括你我在内的所有人都在期待更多 AI Killer App 的出现
现在,大模型万众瞩目,每一个人都在期待着 ChatGPT 之后的下一个 AI Killer App 的诞生,而它也很可能随时会诞生。对于大模型这样的新生事物,千行百业都在等待,等着我们这些程序设计师、软件工程师以及系统架构师,协力,来一起加快大模型应用开发的步伐。发掘大模型的巨大潜力、推动人机协同,实现人类和 AI 的共同进化。这是一场前所未有的变革,也是一次伟大的机遇。我们应该以开放和创新的心态拥抱这一切。
所以,大模型应用开发这件正处于萌芽阶段,即将全面落地开花、结果,但是又尚未开花结果的事情,我们不去做,由谁来做?
以上,就是为什么大语言模型应用开发对你、对我、对他,都如此重要的答案。
AI 引发行业爆发的四个阶段
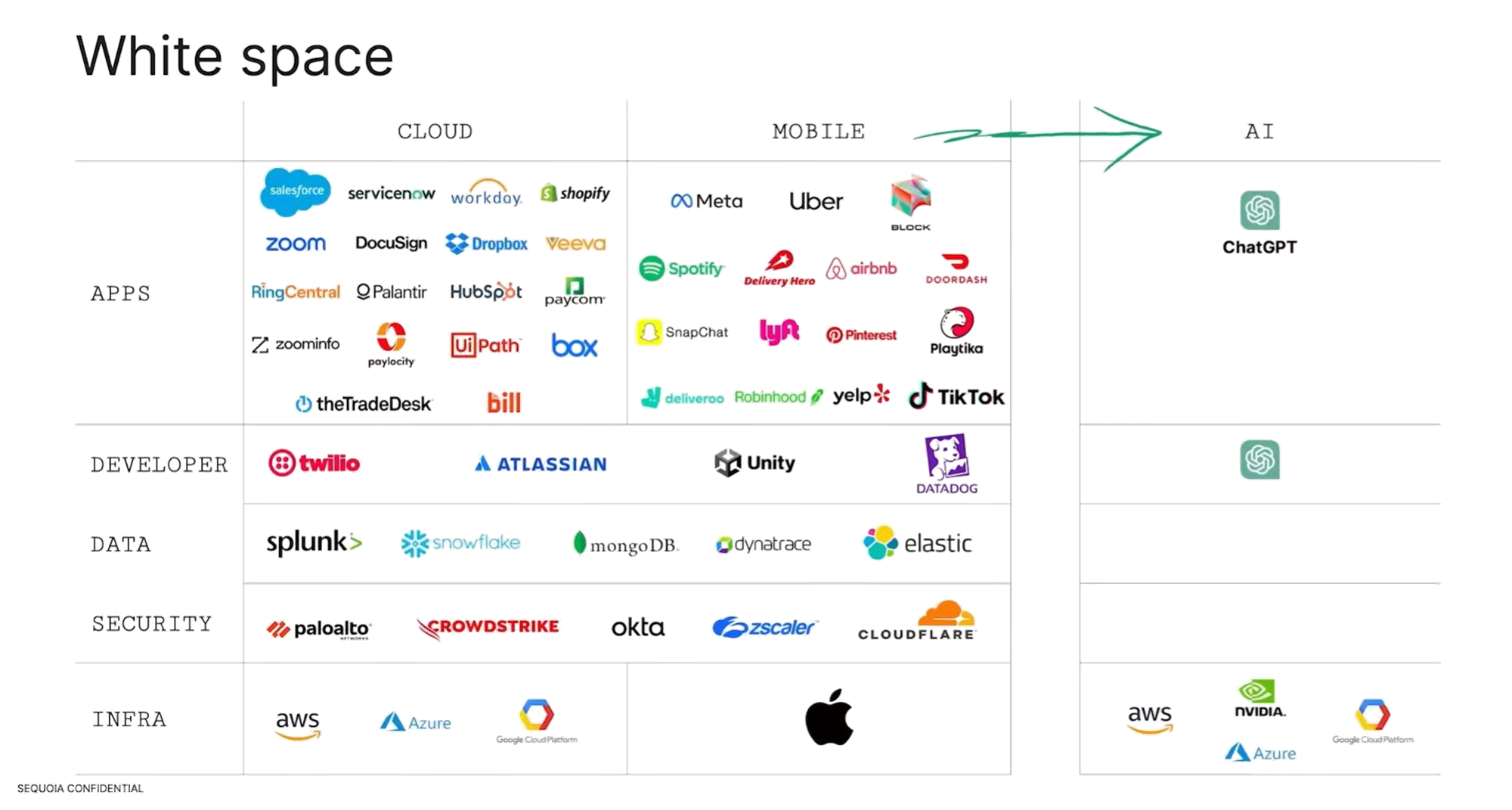
随着人工智能技术的飞速发展,高盛的最新报告为投资者描绘了一幅详尽的投资路线图。这份报告分析了 AI 投资的四个阶段:芯片制造和大模型提供者、基础设施建设、为收入增长赋能、生产率提升。在这四个阶段中,AI 的影响将覆盖从半导体到云服务等多个领域,各行各业都将成为 AI 技术的潜在受益者。
第一阶段是对 AI 芯片的巨量需求让英伟达、AMD 等公司的股价一飞冲天,尽管最近的波动显示出市场对其热度有所降温,但这并不影响英伟达股价自年初以来就实现了巨幅增长。作为大模型提供者的 Google、MicroSoft、Facebook 等巨头和 OpenAI 以及 ANTHROP\C、Mistral AI 等初创公司,无可置疑的都处于风口浪尖。
第二阶段是基础设施建设阶段,参与 AI 基础设施建设的公司,如半导体企业、云服务商、数据中心运营商、硬件设备制造商、安全软件公司和公用事业企业都将受益。
第三阶段则聚焦于那些能够通过 AI 技术增加收入的公司。这一阶段的受益企业包括众多软件和 IT 服务公司,如 Cloudflare、Autodesk、MongoDB 等公司。
第四阶段则包括所有通过 AI 技术提升生产率的公司。在劳动密集型行业,如软件服务、商业和专业服务领域,AI 自动化带来的效率提升潜力最大。
作为一个与各种企业紧密互动的技术人员,我的日常感受也与上面这份商业报告相符,不仅仅是公司内部、外部,都纷纷展开基于大模型的智能文档管理 / 检索系统。就拿我经常访问的 LangChain 网站来说,我就发现基于大语言模型的应用程序早已渗透到了网站功能设计之中,比如下面两张图的绿箭头处,所显示的文档检索功能,都是基于大语言模型所开发的。而 OpenAI 去年 11 月推出的 ChatGPT 企业版,已经被很多很多家财富五百强企业所采用,为企业降本,为员工增效。
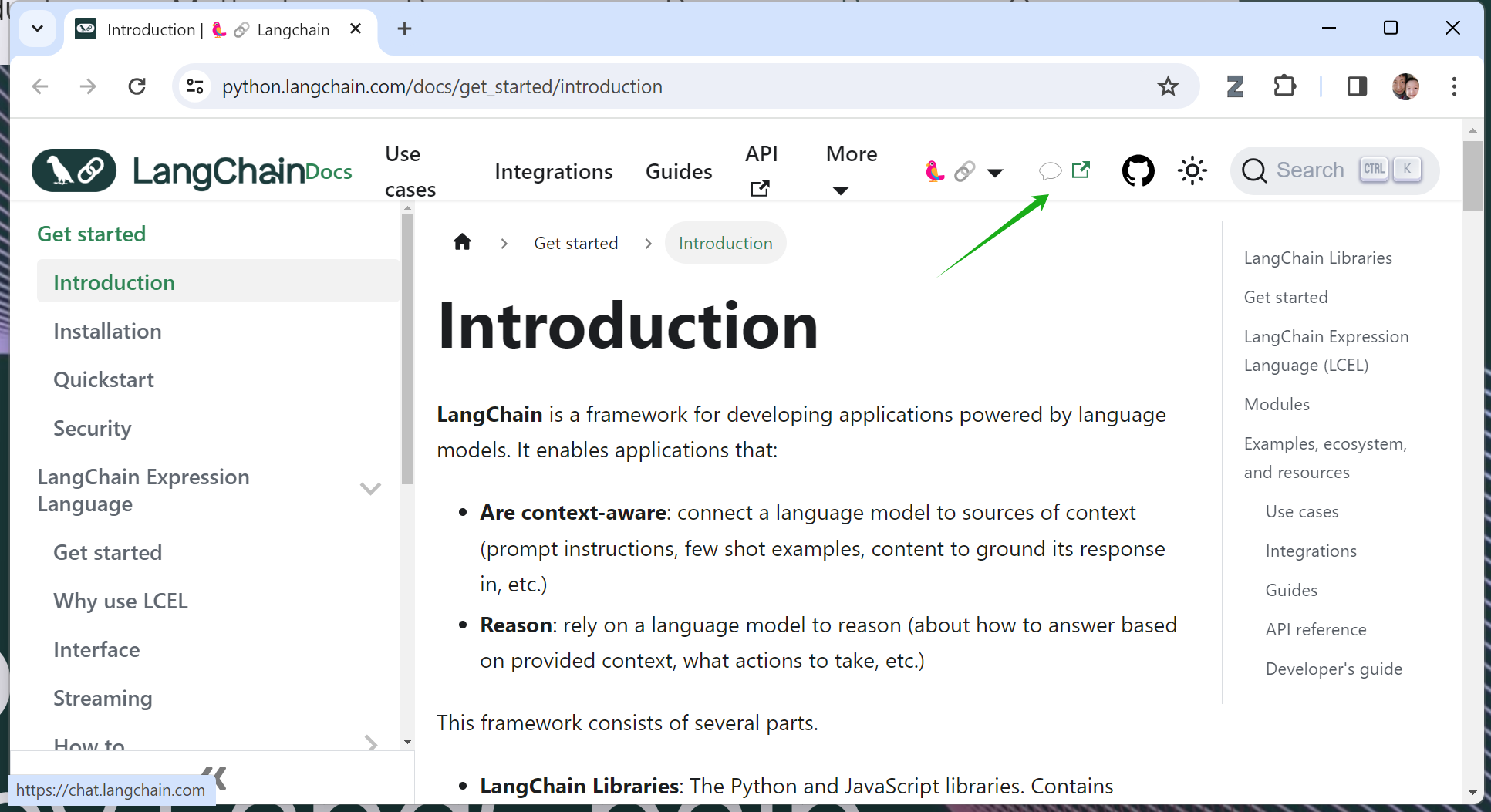
LangChain 网站中的智能检索系统
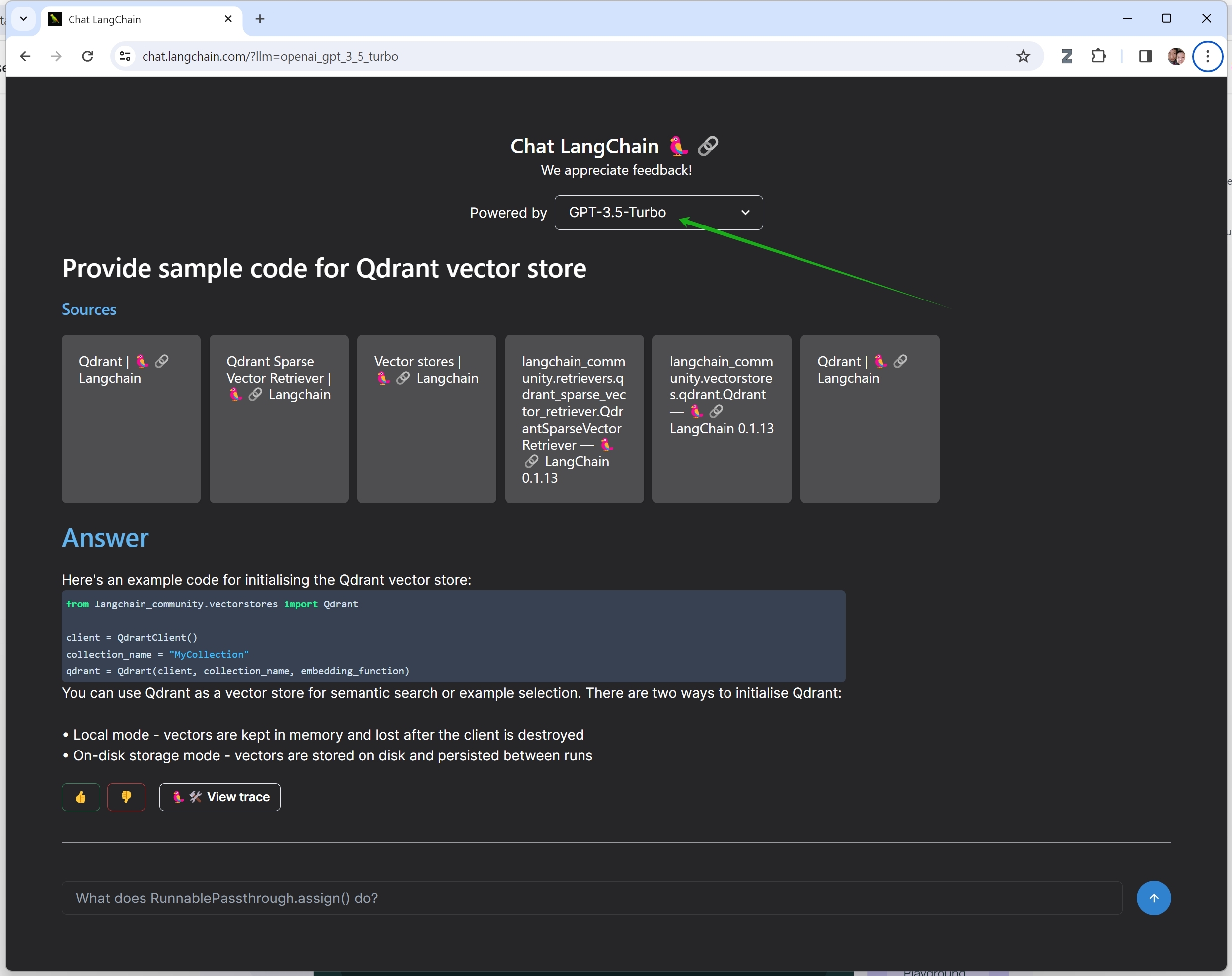
Powered by GPT-3.5
因此,无论是 To B、To C 业务及应用,还是在企业内部降本增效,或者提升个人工作效率,你未来都已经无法离开大语言模型应用开发。
人类将逐渐使用自然语言编程
尽管大语言模型应用开发即将进入每一个程序员的世界,但是作为习惯了 C、C++、Java 的我们来说,有一点我们需要了解并提前适应的是,大语言模型应用开发遵循的是和传统程序设计迥然不同的编程范式。
如何不同?
正如 OpenAI CEO Altman 所说,展望未来,尽管人类依然会进行大量编程工作,但形式将会发生巨大变化,甚至有人可能会完全通过自然语言进行编程。
他和采访者的对话摘录如下:
Fnidman:你认为 5-10 年后人类将进行多少编程?
Altman:很多,但形式会截然不同。也许有些人会完全用自然语言编程。
Fnidman:充全用自然语言?
Altman:对,未来不会有人再通过代码编写程序。这就像现在几乎没有人再对打孔卡进行编程了。
Fridman:我认为你会被一些评论喷,但事实上你说得对,我现在连用 Fortran 语言的程序员都找不到了。
这段对话引人深思。自然语言处理技术的快速发展,其实会为人机交互的方式带来颠覆式的改变。未来人类参与编程的方式将与现在大不相同。传统的编程方式需要掌握专业的编程语言和复杂的语法规则,对大多数人来说存在较高的门槛。但是,自然语言处理的进步,尤其是 GPT 等超强模型的出现,让计算机开始具备理解和生成人类语言的能力。这意味着,未来人们可能只需要用自然语言描述他们想要完成的任务,计算机就能自动生成相应的程序。
这种变革将极大地降低编程的门槛,让更多人能够参与到编程活动中来。无论是专业开发人员,还是不具备太多编程背景的普通用户,都能够用自己熟悉的语言与计算机进行交互,实现自己的创意和想法。这将极大地提高生产力,促进创新,并在各个领域催生出新的应用和服务。这个看法,其实和李彦宏提出的“人人都是程序员”是同一个意思。
当然,大模型不是神仙,它无法猜你的心意,然后给你变出你想要的东西,因此程序员还会继续存在,只是需要适应新的语境,掌握新的编程范式。
我把这个新的编程范式称为“基于自然语言的编程范式”或简称“自然语言编程范式”。
而所谓自然语言编程范式,在现阶段,其实就是做更好的提示工程。因为控制大型语言模型输出的最有效方法是设计优质的文本提示。
常见的提示方式包括:
指令式:清晰明确说明期望的输出形式和内容要点。
补全式:为模型提供充足的背景信息、相关示例或任务目标等上下文语境。
场景式:给模型一个具体的情景,要求模型以相关领域专家的口吻和视角给出回答。
示范式:通过少量示例或列出问题求解或生成输出的完整思路和推理过程,让模型照猫画虎。
而如何做更好的提示工程,我的观点就是不要把大语言模型当成机器,而是要把大语言模型真真正正的当成一个人来看待。
请看这个例子。
import openai
openai.api_key = "your_api_key"
completion = openai.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "你是一位数据分析师,请根据以下步骤撰写一份数据分析报告。"},
{"role": "user", "content": '''背景:电商平台要分析用户购物行为。请完成以下任务:
1.提出2~3个切入点;
2.列出每个切入点要分析的指标
;3.假设你发现了有价值的洞见,提出2~3条可行的建议
;4.综合成一份完整报告。'''
}
],
temperature=0.8
)
print(completion.choices[0].message.content)
上述提示,直接引导 GPT 生成了一份高质量数据报告。这还是在只有提示词,没有数据,凭空想象的前提下。
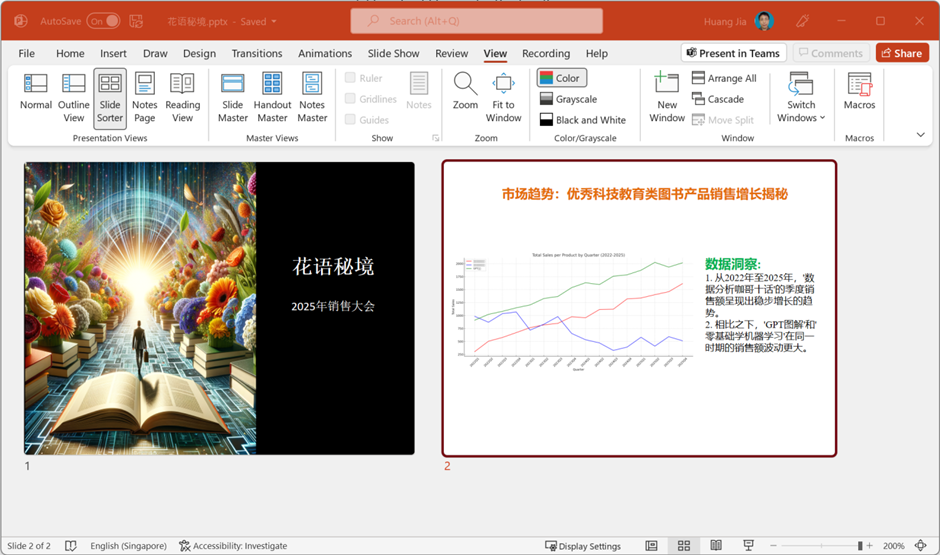
我们当然也可以传入文件给大模型,让它完成实质性的数据分析工作。强大的 OpenAI Asistants 助手,甚至能够从我的一个数据文档出发,经过正确的自然语言提示引导后,一键创建出下面这种质量的 PPT。
这些项目,后续在我们的课程中都会有完整的实现。
具体来说,为了优化提示的效果,我们可以尝试以下技巧。
精准定制:清晰具体地描述你期望得到的输出形式和内容要素,让 AI 的回应更贴合你的需求。
语境导入:为 AI 提供充足的背景信息、相关示例或任务目标等上下文语境,帮助其更好地理解和完成任务。
求助权威:要求 AI 以相关领域专家的口吻和视角,给出高质量、深入全面的专业意见和解答。
梳理逻辑:要求 AI 清楚列出问题求解或生成输出的完整思路和推理过程,展现其思考逻辑。
那么你看看,上述这些提升方法和技巧,哪里像是在编传统程序,是不是像极了在和你的个人助理、员工、客户甚至领导谈话。
这里,我再给出一个通过目前最强大 Claude3-Opus 模型(能力已碾压 GPT-4)用数据库自然语言进行查询的示例代码(完整代码见后续课程说明)。
问题:{query}
"""
response = client.messages.create(
model=MODEL_NAME,
max_tokens=2048,
messages=[{
"role": 'user', "content": prompt
}]
)
return response.content[0].text
# 示例自然语言问题
question = "工程部门员工的姓名和工资是多少?"
# 将问题发送给Claude并获取SQL查询
sql_query = ask_claude(question, schema_str)
print("生成的SQL查询:")
print(sql_query)
# 执行SQL查询并打印结果
print("查询结果:")
results = cursor.execute(sql_query).fetchall()
下面就是模型给出的答案。
数据库模式:
CREATE TABLE EMPLOYEES (
id INTEGER
name TEXT
department TEXT
salary INTEGER
)
生成的SQL查询:
SELECT name, salary
FROM EMPLOYEES
WHERE department = '工程';
查询结果:
('宁宁', 75000)
('海悦', 80000)
大语言模型是妥妥的把自然语言(工程部门员工的姓名和工资是多少?)转换成了一丝不苟的 SQL 查询语句,而且不费吹灰之力,且基本不会错。
夸了这么多,我当然也知道自然语言编程还不完美,它的实现当然还面临诸多挑战。自然语言本身存在歧义性和不确定性,准确地把握用户的意图不容易,生成稳定的结果也不容易,它的推理逻辑和输出内容都不像我们传统程序设计中,一是一、二是二这样清晰明确。此外,安全性、伦理等问题也不容忽视,需要在技术进步的同时,建立起完善的管理和监督机制。
一个用 ChatGPT 进行函数调用的示例
当然,对你来说,也许更重要的问题是?对于习惯了用 Java、C++、Spring、React 等语言、框架和工具进行开发的技术人员来说,怎么进行大语言模型的应用开发?这,正是我们这个专栏带你轻松解决的问题。放心,跟着佳哥学大模型开发,不仅不难,而且还很快乐。
为了让你体会佳哥课程的实战特色,我们直接开始实战。
不过,有了大语言模型。我们就完全没有遵循特定 API 格式的必要了,大语言模型能够自动自发地帮助我们把自然语言“翻译”成 API 能够读懂的程序语言。
程序的完整代码如下:
import openai
import json
import requests
def get_weather(city):
api_key = "213745ddc9d6130ff1335e7b92b93294"
url = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={api_key}&units=metric"
response = requests.get(url)
if response.status_code == 200:
data = response.json()
weather = data["weather"][0]["description"]
temp = data["main"]["temp"]
return json.dumps({"city": city, "weather": weather, "temperature": temp})
else:
return json.dumps({"city": city, "error": "Unable to fetch weather data"})
def run_conversation():
messages = [{"role": "user", "content": "Beijing的气温如何?"}]
functions = [
{
"name": "get_weather",
"description": "Get the current weather in a given city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city name",
}
},
"required": ["city"],
}
}
]
response = openai.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
function_call="auto"
)
response_message = response.choices[0].message
if response_message.function_call:
function_name = response_message.function_call.name
function_args = json.loads(response_message.function_call.arguments)
if function_name == 'get_weather':
function_response = get_weather(city=function_args["city"])
else:
function_response = f"Unknown function: {function_name}"
messages.append(response_message)
messages.append({"role": "function", "name": function_name, "content": function_response})
second_response = openai.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages
)
return second_response.choices[0].message.content
else:
return response_message.content
print(run_conversation())
程序的主要流程如下:
首先定义了一个 get_weather 函数,用于调用 weather API 来获取指定城市的天气信息。
在 run_conversation 函数中,我们首先发送一个包含用户问题(自然语言)和可用函数定义(即函数的元数据)的消息给 OpenAI 的 ChatCompletion 接口。
接着检查模型返回的响应中是否包含 function_call,如果有,则提取出函数名和参数,调用对应的函数(这里只有 get_weather)。
将函数的响应添加到消息列表中,再次发送给模型,请求它根据函数结果生成一个最终的回复(自然语言)。
最后在程序入口调用 run_conversation 函数,打印出整个对话的结果。
你看,其实这是大模型帮你完成从自然语言提问,到自然语言输出的过程,中间大模型做了两次翻译(先是从自然语言到 API 输入,再是从 API 输出到自然语言)。
通过这个例子,你可以了解到如何利用 OpenAI 的 Chat Completion 接口和 Function Calling 功能,将大语言模型与外部 API 进行集成,实现更加智能化的应用。关键在于如何定义函数元数据,以及如何解析模型返回的 function_call 参数,调用实际的函数,并将结果反馈给模型。
模型的回答如下所示:
你可以尝试各种各样的自然语言提问,程序都可以帮你解析成 API 可以理解的机器语言,然后得到 API 返回的结果后,再次经过大语言模型的“二次翻译”,又通过自然语言返回给你。
因此,这是一个从【自然语言输入 ->(1) API 格式输入(机器语言)->(2) API 返回结果(机器格式)->(3) 自然语言输出的】三步骤过程。其中,大语言模型模型在(1)、(3)处发挥作用,而天气 API 则是在(2)处发挥作用。
绝不仅仅是对话助手和函数调用
大语言模型绝不仅仅只是对话助手和函数调用,大语言模型的应用比我们想象的还要广泛得多,涵盖了对话、代码解释、知识检索、函数调用、提示工程、Agent 开发、RAG、微调、多模态、Embedding 等诸多方面。
具体来说:
在对话助手方面,大语言模型不仅可以进行多轮对话,还可以记住上下文,生成连贯、准确的回复。通过提示工程,我们可以让模型更好地理解用户意图,给出更贴切的回答。
在代码解释和知识检索方面,大语言模型可以充当智能程序助手,解释代码逻辑,并根据问题从海量知识库中检索出相关信息。这大大提升了开发者的工作效率。
在函数调用方面,我们可以让大语言模型根据用户指令自动生成函数参数,甚至通过微调使其能够调用自定义函数。这开启了人机协作的新范式。
在多模态和 Embedding 方面,大语言模型不再局限于文本,还可以处理图像、语音等多种形式的数据。Embedding 让我们能够将万事万物统一映射到一个语义空间,发掘事物之间的内在联系。
除此之外,大语言模型在写作辅助、信息抽取、数据增强、知识图谱等领域也有广泛应用。通过微调等技术,我们可以将通用模型快速适配到特定任务,即使缺乏大量标注数据,也能实现良好效果。
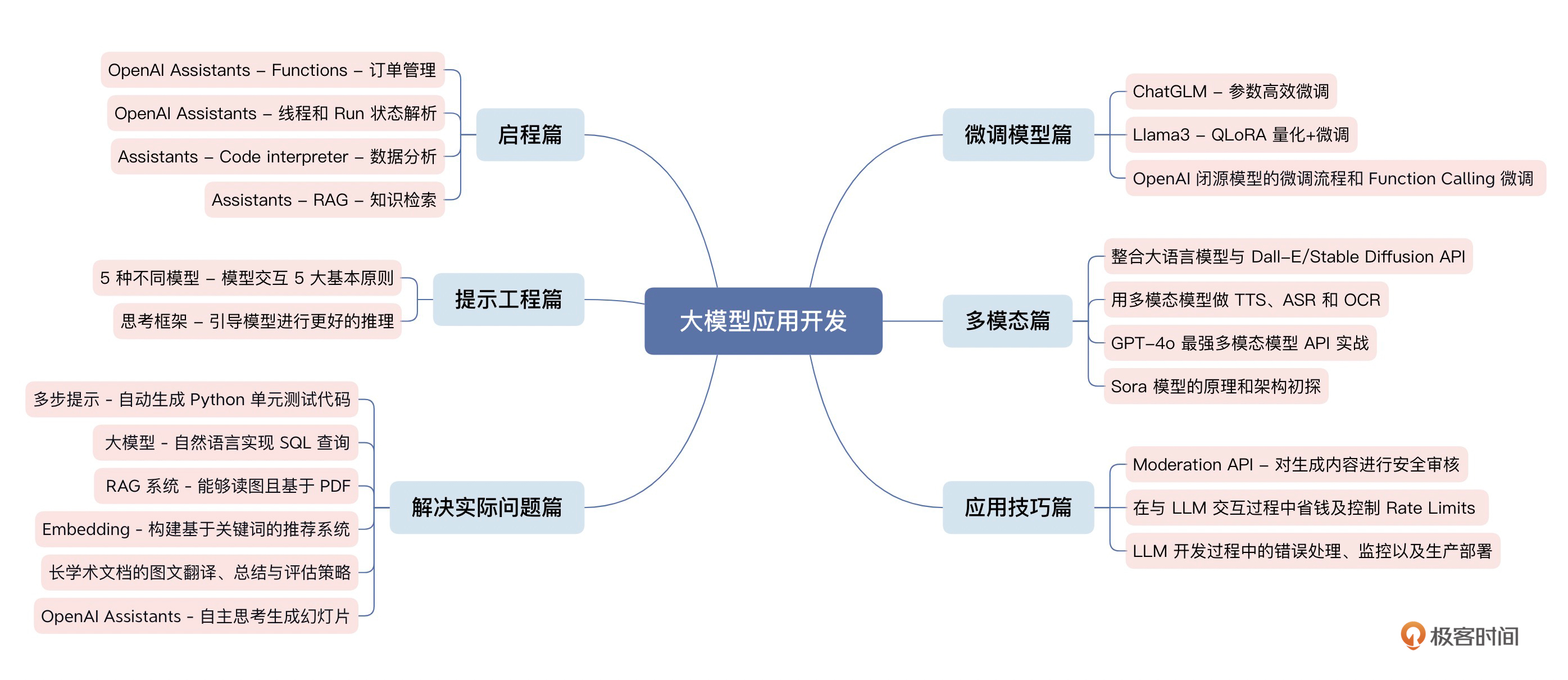
下面,我就给出你我们这门课程的知识图谱。
我们将全面讲解大语言模型技术的方方面面。从 API 的使用到微调的流程,从应用实例到技巧总结,从经典模型到前沿进展,随着课程的进展,你将对大语言模型有一个全面而深入的认识。不仅能快速上手开发实际应用,更能洞悉其内在原理,激发更多创新灵感。
大语言模型代表了人工智能发展的新阶段。它以强大的自然语言处理能力为基础,不断拓展到认知智能的更多领域。对话、检索、创作、决策、规划等一系列能力正在被赋予 AI 智能助理,也就是 Agent,并以更自然、更高效的方式为人类服务。这是每一个开发者都应该紧跟和参与的伟大技术革命,而我希望这门课程可以成为大家进入这一领域的引路之灯。
购买课程后,还可以申请加入我的读者群,一个由极客时间学员组成的非常温暖的以学习为主的群体,我们共同成长! 期待与你共同开启探索大语言模型的奇妙旅程!




 荧光笔
荧光笔 直线
直线 曲线
曲线
