

28|总体回顾:工业级AI大模型系统的庐山真面目
Tyler

你好,我是 Tyler。
前几节课,我们学习了提示语工程和模型工程。你掌握得如何?今天,我将带你整体回顾架构实战篇所学内容,并且为你揭开 AI 大模型系统的面纱。除了回顾总结,我还会带你从真实应用的角度了解如何构建一个 AIGC 系统。在这节课中,我将更多地结合我的亲身经验,为你提供一些在其他地方无法获得的具体例子。
我们首先来探讨离线系统,因为通常在开发一个系统时,都会按照先离线,后在线的顺序进行。
模型工程
设计离线系统的第一步,就是清晰梳理我们系统的数据流程。下面我将带你一步步梳理 AIGC 系统中模型训练的数据链路。
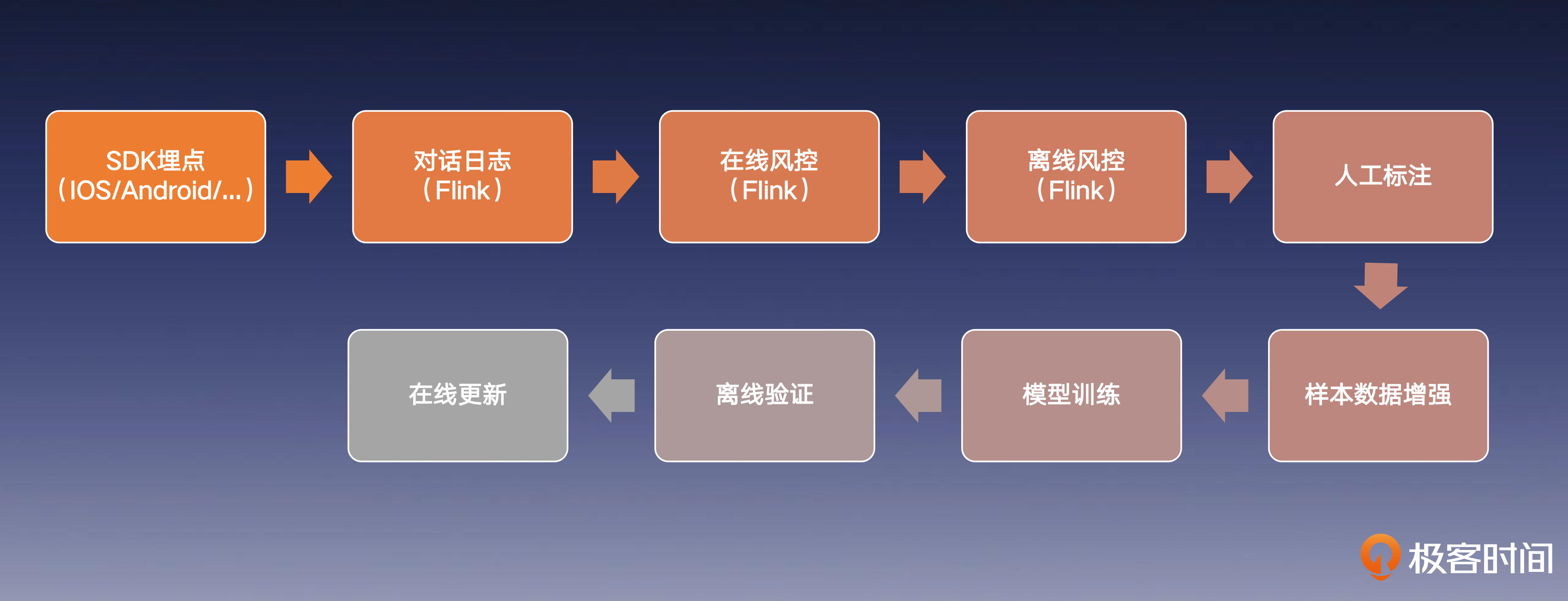
全量模型训练流程
首先是模型训练的数据流程。
在大语言模型对话应用中,我们可以收集到丰富的对话信息,这是宝贵的指令微调语料,AI 系统会将这些对话内容,上报并存储到服务端,来获取足够多的对话数据,供给模型训练使用。
这里需要注意的是,你要重点甄别对抗样本,避免它成为攻击你大语言模型的武器,我们不能假设所有的日志反馈都是安全的,必须进行后续的风控处理,使用专门的分类模型,来识别对抗样本,并将它们从训练数据中剔除。当然这主要是离线风控策略的流程,在线的风控策略关注的主要还是模型越狱和内容安全的风险。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了工业级AI大模型系统的实际应用和关键技术,揭示了其架构实战内容。首先介绍了离线系统的模型工程,包括模型训练的数据流程、样本制备和模型制备,强调了微调提效的方法和模型的离线验证。此外,还介绍了MoE技术用于降低参数量的应用。其次,讨论了提示语引擎的构建,包括知识、工具、示例和会话信息的存储,以及针对用户问题对外部记忆进行排序的过程。整体而言,通过具体例子和技术细节,深入剖析了工业级AI大模型系统的实际应用和关键技术,为读者提供了全面的技术概览。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 大模型系统实战》,新⼈⾸单¥59
《AI 大模型系统实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 周晓英个人浅见:在我工作的领域,工业级 AI 大模型系统与原型验证工具(如 Langchain 和 AutoGPT)之间的区别,主要是工业级AI要通过严密的测试,确保系统提供的内容百分之百准确、合规、没有法律风险,能支撑大量用户并发,在用户体验、响应速度、系统成本中间找到平衡。如果受合规制约,调用的是国产大模型,没有像OpenAI那么完善的生态支持,还要做很多的胶水组件,探索很多细节。by the way 国产大模型的能力正在追上来,比如10月27日发布的智谱Chatglm32023-10-29归属地:北京2
周晓英个人浅见:在我工作的领域,工业级 AI 大模型系统与原型验证工具(如 Langchain 和 AutoGPT)之间的区别,主要是工业级AI要通过严密的测试,确保系统提供的内容百分之百准确、合规、没有法律风险,能支撑大量用户并发,在用户体验、响应速度、系统成本中间找到平衡。如果受合规制约,调用的是国产大模型,没有像OpenAI那么完善的生态支持,还要做很多的胶水组件,探索很多细节。by the way 国产大模型的能力正在追上来,比如10月27日发布的智谱Chatglm32023-10-29归属地:北京2
收起评论