

09|系统构建(一):AI系统的弹药库——离线系统
Tyler

你好,我是 Tyler。
从今天开始的两节课,我们不但会回顾总结前面学到的内容,还会带你完成人工智能服务系统的实际架构。
这是一个很好的问题,其实第 5 节课我们更侧重学习业务建模方法,而学完了特征工程、模型工程和数据算法之后,我会带你从零开始,从真实应用的角度来构建一个 AIRC 的离线和在线系统。这个架构既可以满足搜索、广告、推荐这类经典内容分发场景的需求,也同样能兼容内容生成系统,也就是 AIGC 的需要。
这节课我们先来学习离线系统。离线系统是你的后勤总管,决定了你在线服务的上限。你能想象到的几乎所有对数据和算法的调优,都是在离线系统中完成的,所以离线系统是构建 AI 系统的第一颗扣子。
模型工程
设计一个离线系统的第一步,就是理清我们系统的数据流走向。下面我将带你一步步梳理模型训练的数据链路。
全量模型训练
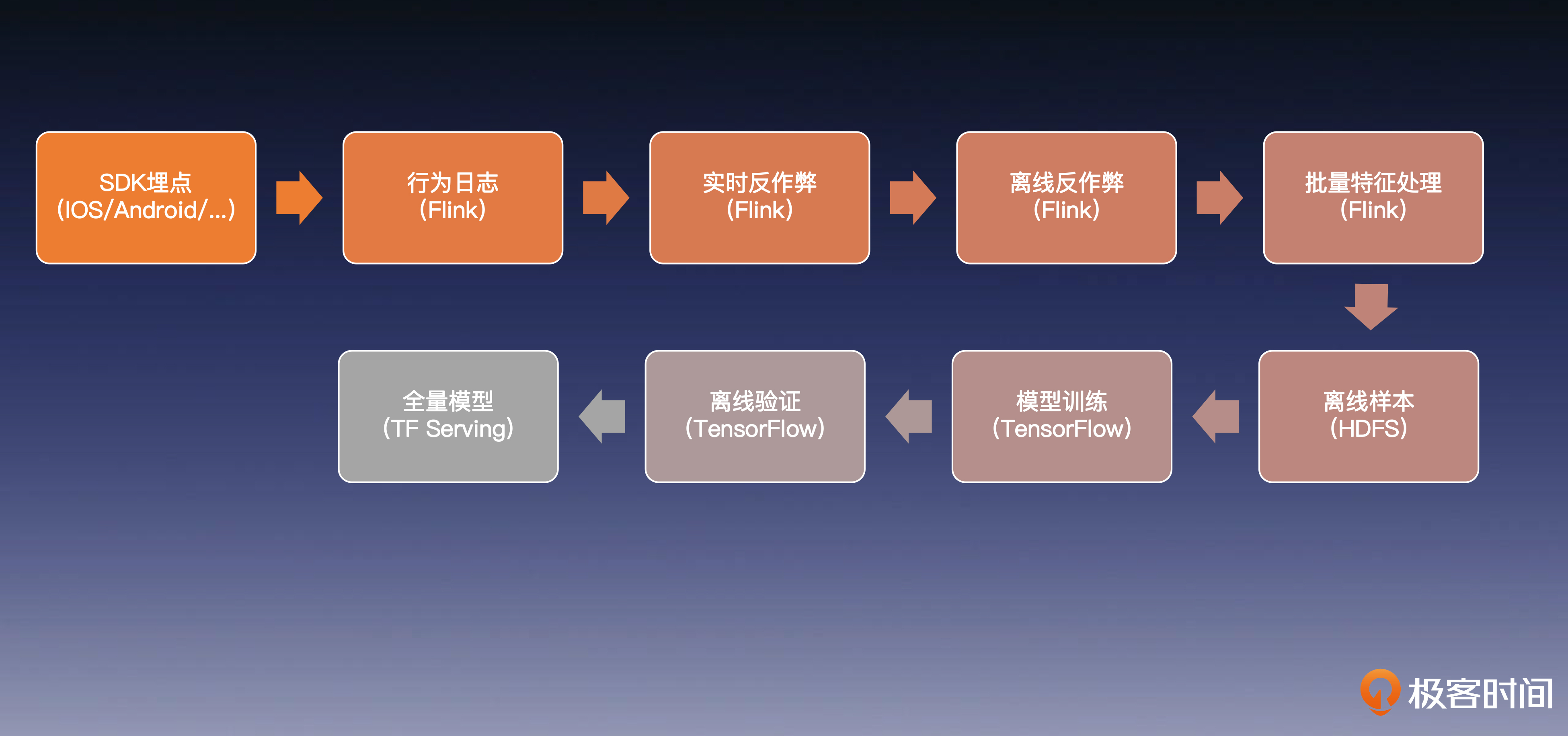
全量模型训练流程
首先是模型训练的数据流程。
因为业务应用(如 APP,网站,客户端等)是用户行为和数据最丰富的地方,所以 AI 系统通常会在用户发生某些行为时,将日志上报到服务端,获取足够多的数据,供给模型训练使用。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了AI系统的离线系统构建,着重介绍了模型工程和存储索引两个关键方面。在模型工程部分,详细讨论了全量模型训练的数据流程,包括日志收集、反作弊处理、样本生成和模型发布等步骤。同时,强调了增量模型训练的流程,并突出了在线模型的实效性和安全性。在存储索引部分,重点介绍了倒排索引服务的重要性,以及如何利用ElasticSearch等工具构建在线的全量倒排索引。此外,还涉及了在线特征的制备流程和知识图谱的生成过程。总的来说,本文为想要了解AI系统架构的读者提供了深入浅出的关键步骤和技术要点,具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《AI 大模型系统实战》,新⼈⾸单¥59
《AI 大模型系统实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(7)
- 最新
- 精选
 一只豆课程日益深入,再次感谢老师~试着回答一下 langchain 中使用的文档片段 Embedding 和 将用户和物品在高维空间的坐标的 Embedding 相比,有很大差别:后者使用真实的业务数据而且嵌入在一整套存储索引系统中,这远远不是文档这种载体能够媲美的。本质来说,是原型系统设计和工业级系统设计的差别吧。
一只豆课程日益深入,再次感谢老师~试着回答一下 langchain 中使用的文档片段 Embedding 和 将用户和物品在高维空间的坐标的 Embedding 相比,有很大差别:后者使用真实的业务数据而且嵌入在一整套存储索引系统中,这远远不是文档这种载体能够媲美的。本质来说,是原型系统设计和工业级系统设计的差别吧。作者回复: 你好,一只豆!再次感谢你的支持!你说的没错,这就是工业级系统和原型系统最大的区别。工业级的系统会对各种载体的“真实数据”进行多个粒度的表征和存储,以达到更好的产业应用效果。这对同学们的知识宽度和深度都有很高的要求,需要耐心的学习。在接下来的课程中,依然期待你的反馈。
2023-08-31归属地:广东2 顾琪瑶唯一能想到的是时效性的问题,假如是时效性的话延迟一天真的会这么重要吗? 有个问题想问下投影模型具体是怎么做的,是否有其他的文章详解呢?比如物品和客户具体是怎么关联起来的等等
顾琪瑶唯一能想到的是时效性的问题,假如是时效性的话延迟一天真的会这么重要吗? 有个问题想问下投影模型具体是怎么做的,是否有其他的文章详解呢?比如物品和客户具体是怎么关联起来的等等作者回复: 你好,顾琪瑶!三级火箭的设计考虑的主要有两个方面,第一是全量模型的训练一般需要很大的数据量(例如:过去一年的抖音视频点赞数据),需要消耗巨大的算力来训练,所以要控制在一周一次。而后两级增量模型的训练则是为了考虑实效性。 关于第二个问题,建议你先吃透前两节课学到的 DeepWalk 和 GraphSage 模型,他们都可以用来实现相关的功能。看过后如果有哪些地方不清楚,欢迎随时提问,我们到时候继续交流。
2023-08-30归属地:上海2 baron推荐系统的三要素是用户、产品、场景; 对用户与产品的embedding其实就是将用户与产品之间的关系在高维空间的表征;而文本的embedding则没有这种三要素的逻辑,是单要素逻辑,是通过模型通过学习大量文本数据种词与词之间的序列关系,而生成的词与词的高维空间表征; 这样的表征应该比用户产品这样的关系数据要更稀疏,维度更高;必然GPT的embedding向量维度到底12288维。
baron推荐系统的三要素是用户、产品、场景; 对用户与产品的embedding其实就是将用户与产品之间的关系在高维空间的表征;而文本的embedding则没有这种三要素的逻辑,是单要素逻辑,是通过模型通过学习大量文本数据种词与词之间的序列关系,而生成的词与词的高维空间表征; 这样的表征应该比用户产品这样的关系数据要更稀疏,维度更高;必然GPT的embedding向量维度到底12288维。编辑回复: 给随堂留言记录的学习态度点赞~
2023-09-02归属地:北京1
 刘峰
刘峰 直接使用增量模型可能会在实效性上有所提升,但存在3个潜在问题。 1. 增量模型可能因为缺少全量数据的综合训练而容易受到噪声影响,导致模型性能下降。 2. 增量模型可能无法涵盖全量数据的多样性,特别是新出现的情况,影响模型的泛化能力。 3. 缺少全量数据的参与可能使得模型无法进行全面的反做弊训练,降低模型的鲁棒性。
直接使用增量模型可能会在实效性上有所提升,但存在3个潜在问题。 1. 增量模型可能因为缺少全量数据的综合训练而容易受到噪声影响,导致模型性能下降。 2. 增量模型可能无法涵盖全量数据的多样性,特别是新出现的情况,影响模型的泛化能力。 3. 缺少全量数据的参与可能使得模型无法进行全面的反做弊训练,降低模型的鲁棒性。作者回复: 你好,林清扬!回答的很好,同时考虑到了时空和反做弊策略对训练数据分布的影响,非常好!
2023-08-30归属地:北京31- InfoQ_6792a017d8d3看到这里已经忍不住分享给朋友,要是23年看了这个课程,23年H2牵头的一个AI应用重要项目,可能效果会好很多
作者回复: 感谢认可,希望课程中的内容可以帮助到每个同学!
2024-02-28归属地:上海  peter是否有安卓手机上可以使用的chatGPT?
peter是否有安卓手机上可以使用的chatGPT?编辑回复: 有的,谷歌搜索就能搜到
2023-08-31归属地:北京 周晓英补充说明: 模型遗忘问题: 在连续的增量训练中,模型可能会遗忘早期学到的知识,尤其是如果新的数据与旧的数据有很大差异时。全量训练可以保证模型能够维持对整个数据分布的理解。 模型评估和验证的困难: 增量训练可能会使模型评估和验证变得更为困难,因为不同时间点的模型可能会有不同的性能表现。全量训练可以为模型提供一个稳定的评估和验证环境。 超参数优化的困难: 在增量训练的过程中,由于数据分布可能会发生变化,原有的超参数可能不再适用,而对超参数的调整和优化变得困难。全量训练提供了一个相对稳定的环境,有助于超参数的选择和优化。2023-10-02归属地:美国2
周晓英补充说明: 模型遗忘问题: 在连续的增量训练中,模型可能会遗忘早期学到的知识,尤其是如果新的数据与旧的数据有很大差异时。全量训练可以保证模型能够维持对整个数据分布的理解。 模型评估和验证的困难: 增量训练可能会使模型评估和验证变得更为困难,因为不同时间点的模型可能会有不同的性能表现。全量训练可以为模型提供一个稳定的评估和验证环境。 超参数优化的困难: 在增量训练的过程中,由于数据分布可能会发生变化,原有的超参数可能不再适用,而对超参数的调整和优化变得困难。全量训练提供了一个相对稳定的环境,有助于超参数的选择和优化。2023-10-02归属地:美国2
收起评论