

02|具身智能:OpenAI真正的野心是什么?

ChatGPT 的发展简史
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

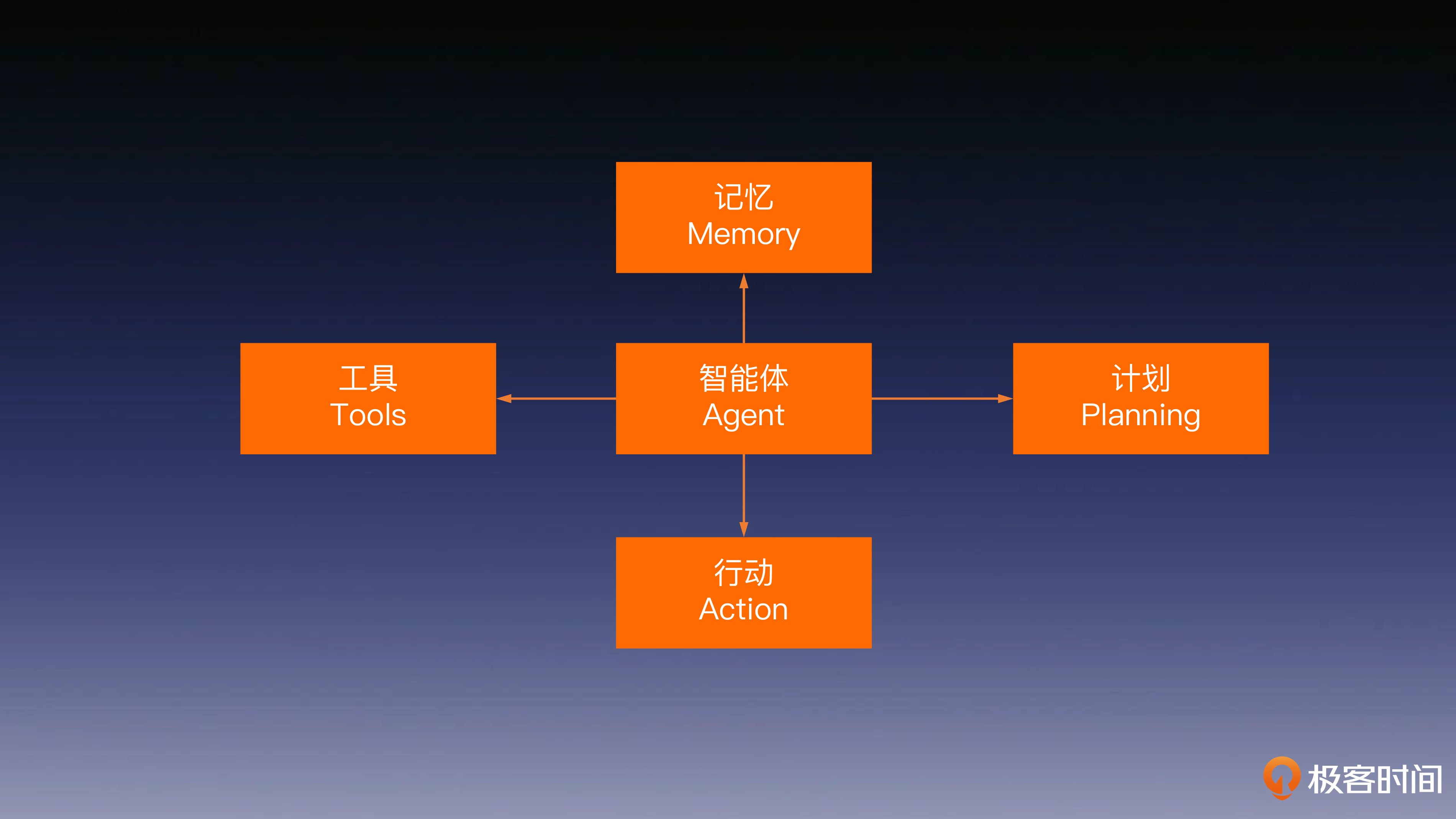
OpenAI的ChatGPT是一种大型语言模型(LLM),代表了未来人工智能的发展方向。文章介绍了ChatGPT的发展历程和未来发展趋势。从第一代大语言模型的诞生到OpenAI采用强化学习技术点亮LLM的智能,再到推出插件、联网功能、函数功能和代码编辑器,ChatGPT的发展一步步展现出其学习使用工具的能力。文章还提到了让LLM“思考”的方法,以及智能体的结构和关键技术要点。通过对任务规划、记忆唤醒和工具使用的讨论,展示了ChatGPT具备的自主决策、记忆和工具使用能力。这些能力使得ChatGPT能够自动化完成许多脑力工作,展现了其具身智能的潜力。文章以此展望了ChatGPT未来的发展方向,指出其不仅仅是一个能说会道的聊天机器人,而是具备与环境交互感知、自主规划、决策、行动能力的通用人工智能。 ChatGPT的发展历程和未来发展趋势展现了其学习使用工具的能力,以及具备自主决策、记忆和工具使用能力,展示了其具身智能的潜力。
《AI 大模型系统实战》,新⼈⾸单¥59

全部留言(10)
- 最新
- 精选
 neohope大模型已经从“萌宠时代”,正式迈入了蹒跚学步的“婴儿时代”。 这个婴儿虽然短期记性不算好,但学习能力和长期记忆能力却无与伦比,潜力无限。 当大模型可以理解工具,使用工具,甚至制造工具、创造工具时,硅基生物时代也就开始降临了。 期待。
neohope大模型已经从“萌宠时代”,正式迈入了蹒跚学步的“婴儿时代”。 这个婴儿虽然短期记性不算好,但学习能力和长期记忆能力却无与伦比,潜力无限。 当大模型可以理解工具,使用工具,甚至制造工具、创造工具时,硅基生物时代也就开始降临了。 期待。作者回复: 你好,neohope!总结的非常好,在接下来的课程中也期待你的反馈。
2023-08-14归属地:上海3 FruitDealer老师,想请教一下向量化存储的技术细节,就是在LLM学习如何使用工具那一小节内容中提到的AI 系统对API 进行向量化操作并存储的时候,存储这些知识的结构是怎样的,是利用专家知识设计一个框架然后不断填入的模式还是自动进行知识抽取存储的呢?如果是后者的话,在这个过程中可能会出现知识体系不断扩展,杂乱无章的问题吧,AI系统是如何控制的呢?感谢老师不吝赐教
FruitDealer老师,想请教一下向量化存储的技术细节,就是在LLM学习如何使用工具那一小节内容中提到的AI 系统对API 进行向量化操作并存储的时候,存储这些知识的结构是怎样的,是利用专家知识设计一个框架然后不断填入的模式还是自动进行知识抽取存储的呢?如果是后者的话,在这个过程中可能会出现知识体系不断扩展,杂乱无章的问题吧,AI系统是如何控制的呢?感谢老师不吝赐教作者回复: 你好,FruitDealer! 这是一个很好的问题,我会尽量用你问题中的措辞来作答,以便让你更好地理解。 在 LLM 系统中添加新的 API 工具时,我们都会将其添加到 API Database 中。这个数据库的键(Key)是 API 的语义表征向量,而值(Value)则是 API 的调用代码。 你所说的抽取出来的知识主要体现在查询键(Key)上面,它来自于 API 代码示例本身(包括名称、功能、版本、参数等)和一些辅助文档(如有)中对 API 的描述信息。针对不同的内容知识抽取方法不尽相同,比如对于 API 的名称可以直接使用 Embedding 进行语义化的表达,而 API 文档中的大段描述则需要经过主题抽取,或者在切片后作为多个 Key 分别存储。 总的来说,我们会根据 API 的所有相关信息抽取出一组语义 Key,形成了对于它的倒排索引。这样,在出现相关语义请求的提示时,我们就可以根据这些 Embedding 来检索得到与之相关的 API 代码。
2023-08-29归属地:四川22 蚂蚁吹雪《AI简史:从工具到上帝》
蚂蚁吹雪《AI简史:从工具到上帝》作者回复: 你好,蚂蚁吹雪!能总结出这个题目说明你真的理解了本节课的内容,👍🏻
2023-08-16归属地:北京2 MOSS思考题解答:目前是刚开始接触大模型的小白,我觉得在教会 LLM 制定计划,反思计划以及使用工具中肯定是教会LLM指定计划更困难,首先反思计划我们可以通过多次的COT来达到最终效果,工具是有它的使用手册或者说明书的,把说明书塞给模型,模型只要按部就班执行就可以了,相反给LLM指定计划涉及到问题的分解,相当于把大象塞进冰箱分几步一样,我们要的答案可能是打开冰箱->塞入大象->关闭冰箱,而大模型收到一定的约束他回给你返回冰箱不能赛大象的答复,这里面涉及到了感性和理性的区别了。
MOSS思考题解答:目前是刚开始接触大模型的小白,我觉得在教会 LLM 制定计划,反思计划以及使用工具中肯定是教会LLM指定计划更困难,首先反思计划我们可以通过多次的COT来达到最终效果,工具是有它的使用手册或者说明书的,把说明书塞给模型,模型只要按部就班执行就可以了,相反给LLM指定计划涉及到问题的分解,相当于把大象塞进冰箱分几步一样,我们要的答案可能是打开冰箱->塞入大象->关闭冰箱,而大模型收到一定的约束他回给你返回冰箱不能赛大象的答复,这里面涉及到了感性和理性的区别了。作者回复: 你好,MOSS。确实,在让大模型生成具有长距离前后逻辑依赖或因果关系的内容(如计划)时,会面临更大的挑战。问题回答得很好,你的名字也很棒!
2024-01-31归属地:上海 l_j_dota_1111老师你好,在LLM使用api那一节课里,既然所有的api都已经放入向量数据库了,为何还要拿api训练模型呢,直接把向量数据库搜寻的结果和prompt一起传给大模型不就行了吗
l_j_dota_1111老师你好,在LLM使用api那一节课里,既然所有的api都已经放入向量数据库了,为何还要拿api训练模型呢,直接把向量数据库搜寻的结果和prompt一起传给大模型不就行了吗作者回复: 同学你好,这是一个很好的问题,因为这个过程包含两个步骤。第一步是告诉大模型你的任务是什么,同时指定它可以使用的 API 工具。在这个过程中,你需要列出哪些 API 工具是可用的;第二步大模型则需要根据它掌握的知识,来组合使用这些 API 工具,以完成你的任务。如果它在训练数据中从未见过这些 API,很难高效地理解并组合使用它们。
2023-11-30归属地:天津 寻老师,上节课的留言不是说这节课会回答吗
寻老师,上节课的留言不是说这节课会回答吗作者回复: 你好,寻!为了保证其他同学可以独立思考,所以我们控制了答案公布的节奏。但还是很乐意将答案回复给你,具体如下: 不可控场景:每个数字应用都是一个智能体,首先服务人类,之后随着时间拉长开始互相对话建立共识,最后架空人类。 技术路径和成本:需要对全社会的工作进行数字化改造,并对每个数字应用进行基于AI大模型的智能化改造,目前社会的算力和发电总量还不能支撑,不过长远看是有可能的。就算现在对大模型技术的使用都会有风控策略的参与,但是难免有“坏人”利用大模型技术搞“Fight Club”。
2023-08-23归属地:浙江 一只豆非常感谢老师开设这门课程!!要想做出产品,工业级的LLM系统搭建知识太必要了。 这堂课里面 用人类的三种记忆来类比 Embedding Prompt 外部向量数据库 也非常捅破窗户纸的感觉。。。哈哈 最后有个小问题,在Gorilla那个图里面,首先是 curation 了 1645 个 API call 在 Dataset 里面,然后后面那一步,是提供了 1645*10 个 指令和 API 的对。所以就是每个 API 都用 10 个指令的例子来教会 LLM。是吗?
一只豆非常感谢老师开设这门课程!!要想做出产品,工业级的LLM系统搭建知识太必要了。 这堂课里面 用人类的三种记忆来类比 Embedding Prompt 外部向量数据库 也非常捅破窗户纸的感觉。。。哈哈 最后有个小问题,在Gorilla那个图里面,首先是 curation 了 1645 个 API call 在 Dataset 里面,然后后面那一步,是提供了 1645*10 个 指令和 API 的对。所以就是每个 API 都用 10 个指令的例子来教会 LLM。是吗?作者回复: 你好,一只豆! 感谢你的认可,你说的没错,Gorilla 确实通过 Self-Instruct 针对每个 API 生成了 10 个指令来微调 LLM。
2023-08-21归属地:广东 周晓英我们可以通过比较人类和大型AI模型在执行这些任务时所面临的挑战来进行分析。 1. 制定计划 (Planning): 人类: 人类能够理解长期和短期目标,并能基于他们的理解和经验来制定计划。 他们能够预见可能的结果并调整计划以适应不同的情况。 大模型: 大模型很难理解或预见长期的结果,它们通常只能在给定的参数和数据范围内制定简单的计划。 它们缺乏对不确定性和复杂性的真正理解,这使得制定有效的计划成为一个挑战。 2. 反思计划 (Reflecting on Plans): 人类: 人类能够反思他们的决策,学习自己的错误,并在未来的计划中应用这些学到的经验。 大模型: 大模型缺乏自我意识和评估能力,它们无法在没有外部输入或额外训练的情况下从错误中学习。 缺乏基于以往经验的自适应能力,不能像人类那样通过反思来改进未来的计划。 3. 使用工具 (Utilizing Tools): 人类: 人类能够理解工具的用途,学习如何使用它们,并在需要时应用它们来解决问题。 大模型: 大模型可以被编程来操作特定的工具,但它们缺乏对工具使用的真正理解和判断。 需要人类编程者为它们创建明确的指令和参数,以使用这些工具。 综合分析: 从上述分析中可以看出,反思计划可能是最困难的任务,因为它需要一种自我意识和评估能力,这是目前大型AI模型所缺乏的。接下来是制定计划,由于大模型缺乏真正的理解和长期预见性,使得计划制定成为挑战。相对来说,使用工具可能是最容易的任务,因为它主要依赖于外部的编程和指令,而不是模型自身的理解和判断。2023-10-02归属地:美国6
周晓英我们可以通过比较人类和大型AI模型在执行这些任务时所面临的挑战来进行分析。 1. 制定计划 (Planning): 人类: 人类能够理解长期和短期目标,并能基于他们的理解和经验来制定计划。 他们能够预见可能的结果并调整计划以适应不同的情况。 大模型: 大模型很难理解或预见长期的结果,它们通常只能在给定的参数和数据范围内制定简单的计划。 它们缺乏对不确定性和复杂性的真正理解,这使得制定有效的计划成为一个挑战。 2. 反思计划 (Reflecting on Plans): 人类: 人类能够反思他们的决策,学习自己的错误,并在未来的计划中应用这些学到的经验。 大模型: 大模型缺乏自我意识和评估能力,它们无法在没有外部输入或额外训练的情况下从错误中学习。 缺乏基于以往经验的自适应能力,不能像人类那样通过反思来改进未来的计划。 3. 使用工具 (Utilizing Tools): 人类: 人类能够理解工具的用途,学习如何使用它们,并在需要时应用它们来解决问题。 大模型: 大模型可以被编程来操作特定的工具,但它们缺乏对工具使用的真正理解和判断。 需要人类编程者为它们创建明确的指令和参数,以使用这些工具。 综合分析: 从上述分析中可以看出,反思计划可能是最困难的任务,因为它需要一种自我意识和评估能力,这是目前大型AI模型所缺乏的。接下来是制定计划,由于大模型缺乏真正的理解和长期预见性,使得计划制定成为挑战。相对来说,使用工具可能是最容易的任务,因为它主要依赖于外部的编程和指令,而不是模型自身的理解和判断。2023-10-02归属地:美国6 K反思计划。 分析过程: 1)制定计划方面,存在大量的可参考套路,如把大象放进冰箱,可分为三步,提取模式即可; 2)使用工具方面,场景较为明确,特定的工具解决特定场景的问题,选择场景工具即可; 3)但反思计划,则涉及问题解决的目标是什么,如何调整决策过程以达到目标,难度较大。2024-01-01归属地:浙江
K反思计划。 分析过程: 1)制定计划方面,存在大量的可参考套路,如把大象放进冰箱,可分为三步,提取模式即可; 2)使用工具方面,场景较为明确,特定的工具解决特定场景的问题,选择场景工具即可; 3)但反思计划,则涉及问题解决的目标是什么,如何调整决策过程以达到目标,难度较大。2024-01-01归属地:浙江 Eric老师好,这里有一点小疑问,这里LLM使用API,是LLM生成调用路径,有应用来完成工具调用,还是LLM本身去创造runtime去调用呢?2023-12-25归属地:四川
Eric老师好,这里有一点小疑问,这里LLM使用API,是LLM生成调用路径,有应用来完成工具调用,还是LLM本身去创造runtime去调用呢?2023-12-25归属地:四川