

12 | 计算梯度:网络的前向与反向传播
方远
你好,我是方远。
在上节课,我们一同学习了损失函数的概念以及一些常用的损失函数。你还记得我们当时说的么:模型有了损失函数,才能够进行学习。那么问题来了,模型是如何通过损失函数进行学习的呢?
在接下来的两节课中,我们将会学习前馈网络、导数与链式法则、反向传播、优化方法等内容,掌握了这些内容,我们就可以将模型学习的过程串起来作为一个整体,彻底搞清楚怎样通过损失函数训练模型。
下面我们先来看看最简单的前馈网络。
前馈网络
前馈网络,也称为前馈神经网络。顾名思义,是一种“往前走”的神经网络。它是最简单的神经网络,其典型特征是一个单向的多层结构。简化的结构如下图:
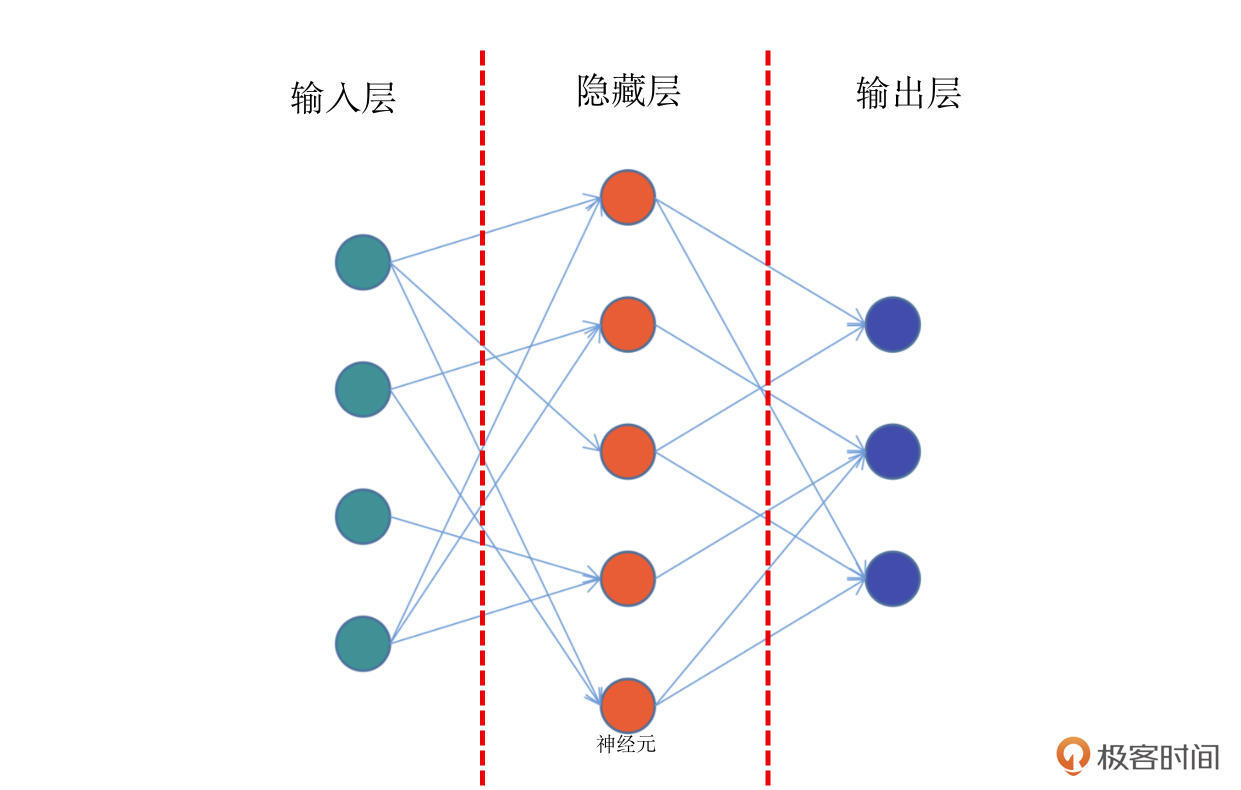
结合上面的示意图,我带你具体看看前馈网络的结构。这个图中,你会看到最左侧的绿色的一个个神经元,它们相当于第 0 层,一般适用于接收输入数据的层,所以我们把它们叫做输入层。
比如我们要训练一个 y=f(x) 函数的神经网络,x 作为一个向量,就需要通过这个绿色的输入层进入模型。那么在这个网络中,输入层有 5 个神经元,这意味着它可以接收一个 5 维长度的向量。
结合图解,我们继续往下看,网络的中间有一层红色的神经元,它们相当于模型的“内部”,一般来说对外不可见,或者使用者并不关心的非结果部分,我们称之为隐藏层。在实际的网络模型中,隐藏层会有非常多的层数,它们是网络最为关键的内部核心,也是模型能够学习知识的关键部分。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了神经网络的前向传播和反向传播过程,以及相关的数学概念。首先,文章详细解释了导数、偏导数和梯度的概念,以及它们在神经网络中的应用。导数被解释为函数值的变化率,偏导数则是在一个变量变化时其他变量保持不变的导数,而梯度则是由所有偏导数组成的向量,代表了函数值增长最快的方向。这些数学概念对于理解神经网络的反向传播过程至关重要。接着,文章介绍了链式法则的应用,以及其在计算复合函数导数时的重要性。随后,文章详细解释了反向传播算法的原理,包括前向传播、计算误差并传播以及迭代的过程。最后,文章强调了梯度下降在反向传播中的重要性,以及深度学习中模型如何学习的关键环节。通过本文的总结,读者可以快速了解神经网络的前向传播和反向传播过程,以及相关的数学概念,为进一步深入学习打下基础。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《PyTorch 深度学习实战》,新⼈⾸单¥59
《PyTorch 深度学习实战》,新⼈⾸单¥59
立即购买

登录 后留言
全部留言(11)
- 最新
- 精选
- vcjmhg不全是基于反向传播的,正常来说训练权重的方法有两种: 第一种是基于数值微分(如梯度下降算法),这种方式的优点就是实现简单便于编写代码不容易出错,但缺点在于时间复杂高,计算比较耗时 第二种是基于反向传播,它优点是效率高计算速度快,但缺点在于实现起来比较复杂,容易出错。 因此在实际工程应用中,会比较数值微分和反向传播的结果(两者的的结果应该非常接近),以确定我们书写的反向传播逻辑的正确性,这样的操作也被称为梯度确认。
作者回复: 你好,vcjmhg,感谢你的留言。👍🏻👍🏻👍🏻,每次都非常正确,厉害^^。
2021-11-05328  官个人觉得不全是,比如在验证集和测试集测试模型不存在训练的过程,应该也就不存在反向传播吧?
官个人觉得不全是,比如在验证集和测试集测试模型不存在训练的过程,应该也就不存在反向传播吧?作者回复: 你好,官。谢谢你的留言。你说的是正确的,只有在训练时才会有反向传播。 除此之外,主流的深度学习模型是基于反向传播和梯度下降的,但是一些非梯度下降的二阶优化算法也是存在的,比如拟牛顿法等。不过计算代价非常大,用的就比较少了。
2021-11-059 Chloe赞这个总结“模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习。”
Chloe赞这个总结“模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习。”作者回复: ^^
2022-01-302 马成关于梯度计算,有个困惑: 如果采用GD算法,一次性把整个测试集都参与计算,loss函数是一个关于参数的多元函数,那么: 1)数据集可以流式加载,不断更新这个loss函数,其实不会消耗多大内存,就可以得到最终的内涵了全部数据集的loss函数; 2)有了loss函数之后,只需要求导一次,理论上以后每次迭代计算梯度的时候,直接基于loss函数计算就行,不需要重新计算一遍整个数据集; 所以总体上来看,GD应该是非常快的呀,为什么说他一次性加载太多数据,占用太多内存,每次梯度计算都重来一遍呢?
马成关于梯度计算,有个困惑: 如果采用GD算法,一次性把整个测试集都参与计算,loss函数是一个关于参数的多元函数,那么: 1)数据集可以流式加载,不断更新这个loss函数,其实不会消耗多大内存,就可以得到最终的内涵了全部数据集的loss函数; 2)有了loss函数之后,只需要求导一次,理论上以后每次迭代计算梯度的时候,直接基于loss函数计算就行,不需要重新计算一遍整个数据集; 所以总体上来看,GD应该是非常快的呀,为什么说他一次性加载太多数据,占用太多内存,每次梯度计算都重来一遍呢?作者回复: 你好。 在实际应用中,GD仍然可能存在以2个问题: 1. 数据集过大:如果数据集过大,那么即使采用流式加载的方式,仍然需要占用大量内存。 2. 计算复杂度高:对于一些复杂的loss函数,计算梯度可能非常耗时。例如,如果loss函数是深度神经网络的损失函数,那么计算梯度可能需要进行大量的矩阵运算。 所以一般还是采用sgd相关的方法。
2023-11-01归属地:上海
 piboye这个前馈网络就是MLP 吧?
piboye这个前馈网络就是MLP 吧?作者回复: 对,是的,就是MLP
2023-06-29归属地:广东 小平的IO这个图的输入层是4维的吧
小平的IO这个图的输入层是4维的吧作者回复: 你好,感谢你的留言。 对 batch, height, width, channel
2022-08-17归属地:北京 北方剑圣链式法则部分似乎有个公式每显示出来,损失函数H的表示那里2022-02-231
北方剑圣链式法则部分似乎有个公式每显示出来,损失函数H的表示那里2022-02-231- Geek_9f1b33不太理解,深度学习不都是反向传播吗? 通过误差反向传播迭代更新2021-12-051
 ifelse
ifelse 学习打卡2023-11-30归属地:浙江
学习打卡2023-11-30归属地:浙江 John(易筋)方老师强调的要点摘录: 模型就是通过不断地减小损失函数值的方式来进行学习的。让损失函数最小化,通常就要采用梯度下降的方式,即:每一次给模型的权重进行更新的时候,都要按照梯度的反方向进行。 模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习。2022-08-05归属地:广东
John(易筋)方老师强调的要点摘录: 模型就是通过不断地减小损失函数值的方式来进行学习的。让损失函数最小化,通常就要采用梯度下降的方式,即:每一次给模型的权重进行更新的时候,都要按照梯度的反方向进行。 模型通过梯度下降的方式,在梯度方向的反方向上不断减小损失函数值,从而进行学习。2022-08-05归属地:广东
收起评论