

10 | 数据服务难道就是对外提供个API吗?

该思维导图由 AI 生成,仅供参考
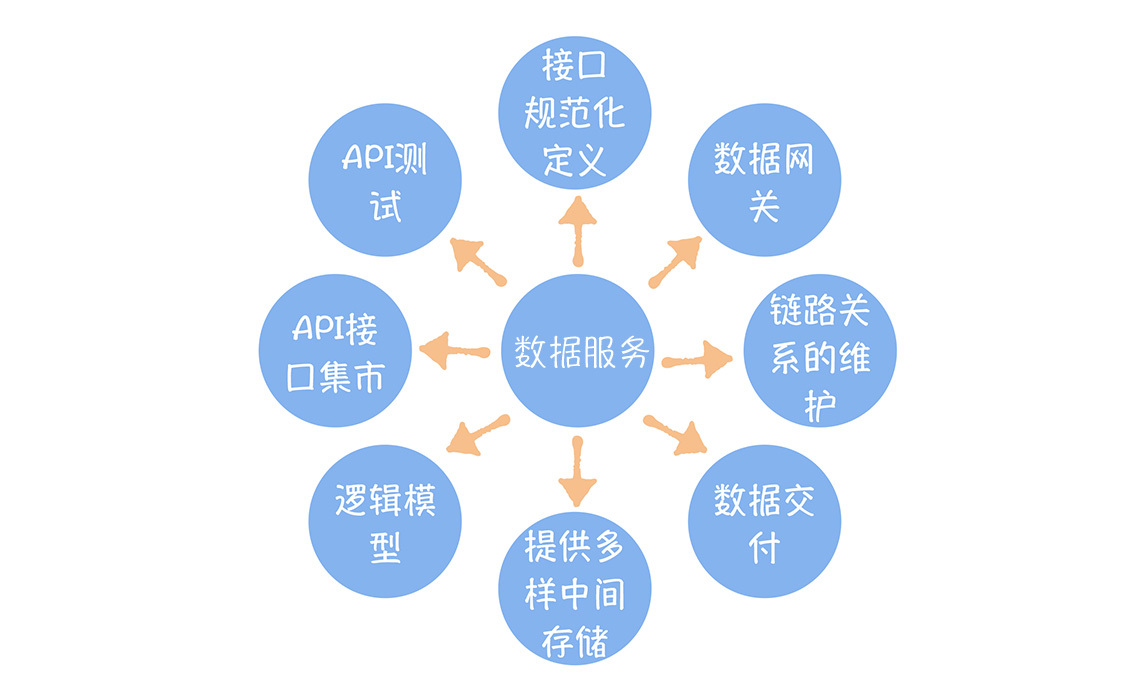
数据服务应该具备的八大功能
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

数据服务在数据建设中扮演着重要角色,不仅仅是简单的API提供,而是涉及复杂的产品功能设计和系统架构设计。本文介绍了数据服务的八大功能,包括接口规范化定义、数据网关、全链路打通、推和拉的数据交付方式、利用中间存储加速数据查询、逻辑模型实现数据复用、构建API集市实现接口复用。通过生动的菜鸟驿站取快递的比喻,读者可以形象地理解数据服务的功能。数据服务需要具备认证、权限、限流、监控等功能,同时维护数据模型到数据应用的链路关系,实现数据的推送和拉取,加速数据查询,实现数据复用和接口复用。这些功能对于设计数据服务或选择商业化产品都有很大帮助。通过本文,读者可以深入了解数据服务的重要性和复杂性,为数据建设提供了有益的指导。 文章介绍了数据服务的八大功能,包括接口规范化定义、数据网关、全链路打通、推和拉的数据交付方式、利用中间存储加速数据查询、逻辑模型实现数据复用、构建API集市实现接口复用。同时,通过云原生、逻辑模型和数据自动导出三个关键设计,展示了网易在实现数据服务时的系统架构设计。云原生的高可用性和弹性伸缩特性,逻辑模型的数据动态生成,以及数据自动导出的实时数据查询,为读者提供了架构选型方面的参考。数据服务化对于加速数据交付流程,以及数据交付后的运维管理效率有重要作用,也是数据中台关键的组成部分。
《数据中台实战课》,新⼈⾸单¥59

全部留言(35)
- 最新
- 精选
 你好老师,逻辑模型映射物理模型,对于一对多的情况,会不会这多个物理模型是来源于多个存储(比如gp、mysql、hbase),如果是的话,是怎么实现的?
你好老师,逻辑模型映射物理模型,对于一对多的情况,会不会这多个物理模型是来源于多个存储(比如gp、mysql、hbase),如果是的话,是怎么实现的?作者回复: 你好,问的问题挺好的。 一对多的话,一个逻辑模型对应多个物理模型,有可能存在分散在不同的数据源的情况,比如一个是MySQL的表,一个是HBase的表,这个时候,我们就得实现跨数据源的查询,当然,是有限制的,比如只能基于主键做Join,你在构建逻辑模型的时候。 数据服务,接受到请求后,会根据逻辑模型和物理模型的映射关系,把逻辑模型拆分成多个物理查询请求,然后对返回结果进行聚合。这里面必须要限制查询的条数。
2020-05-02210- zhuxueyu要让数据服务成为数据中台的唯一出口,个人觉得要从三点收口: 1、数据中台的数据能基本覆盖业务的数据需求; 2、业务通过数据服务获取数据更便捷 3、公司层面统一数据出口 - 数据中台
作者回复: 总结的不错~
2020-05-177  无语飞涵老师留的问题我觉得是需要上升到整个组织架构和流程管理,如,每个业务部门提出的需求,需要经过组织中负责企业级数据的部门团队或者评审会,确认该需求是否是属于数据应用类,必须通过数据中台来实现。
无语飞涵老师留的问题我觉得是需要上升到整个组织架构和流程管理,如,每个业务部门提出的需求,需要经过组织中负责企业级数据的部门团队或者评审会,确认该需求是否是属于数据应用类,必须通过数据中台来实现。作者回复: 我觉得,有一个点,你说的很好,技术并不能解决所有的问题,很多问题需要管理机制来配合完成,但是技术本身可以降低管理的复杂性,增强管理的可落地性。 感谢你的留言~
2020-05-1825 Bill👍 到目前为止,几乎和我设想以及实践方式一致。 数据服务这块儿其实可以更简单 - 被动获取:通过1个API解决所有数据请求,只变响应结构即可 - 主动推送:按需按时推送到使用方,做数据增量/全量同步即可。
Bill👍 到目前为止,几乎和我设想以及实践方式一致。 数据服务这块儿其实可以更简单 - 被动获取:通过1个API解决所有数据请求,只变响应结构即可 - 主动推送:按需按时推送到使用方,做数据增量/全量同步即可。作者回复: 感谢你的认可,看来你对这个问题也有深入的思考。数据服务,最早我们其实只提供了API的方式,但是其实发现很难满足业务的全部要求,比如实时数据推送的这个场景,你靠API就搞不定。所以我们又做了送货上门的推的服务。 感谢你的阅读,下一次留言区再会~
2020-04-2435 风轻云淡老师,你之前说数据中台的核心是共享、服务和连接,连接怎么理解?
风轻云淡老师,你之前说数据中台的核心是共享、服务和连接,连接怎么理解?作者回复: 其实,这门课,我并没有涉及到OneID的概念,比如都是一个用户,他在不同的app之间,是否可以唯一的标识,这个就是把不同业务系统的相同实体用唯一的ID打通,可以横向关联分析,这就是连接的内涵。另外一个用户,即使在同一个App内,登录前,登陆后,能不能标识成一个人,也属于OneID的概念。 连接、服务、共享,是中台思想的核,不仅仅是在数据中台,同样对应于其他中台。 感谢你的提问,祝好~
2020-07-184 特种流氓实时部分如何融合到数据到数据中台里面来 与离线模型一起统一对外提供服务
特种流氓实时部分如何融合到数据到数据中台里面来 与离线模型一起统一对外提供服务作者回复: 今年之前,网易的离线和实时数据架构,还是采用的Lamda架构,即实时采用kafka+flink的方式,离线采用spark+hdfs的方式,从ods原始数据开始,kafka会归档一份数据到hdfs,然后分别计算,在数据应用场景上,T+1的数据用离线计算的,T+0的数据用实时链路的。历史数据以离线计算为准。 今年,我们引入的iceburg,正在研发批流一体的实时数据中台架构,iceburg可以实现upsert功能,可以实时更新,避免merge操作。用iceburg统一离线和实时的存储,同时在计算引擎上,主要使用flink,然后辅助用Spark进行校验。目前整套数据湖的方案还在研发中,当然Iceburg也存在一些挑战,比如怎么和现有的impala mpp集成,怎么基于iceburg文件粒度的元数据统计优化计算引擎性能,都是我们目前正在推进的工作。 感谢你的阅读~祝好~
2020-05-074- Sandflass老师,请问一下对于实时的数据服务,比如您提到的实时直播场景,您只提到了最后的数据服务通过kafka推送,但是中间的数据源实时接入、数据实时加工应该采用何种技术方案呢?应该是有异于离线计算的方案吧?我们公司一些业务对于数据实时服务要求比较高,计算量并不大,这种场景应如何做技术选型呢?
作者回复: 你好,数据服务,只负责数据的交付,数据的接入和加工,不是数据服务负责的范畴,是数据集成和数据开发中心负责的范畴。 实时数据集成,对于关系数据库,可以基于MySQL的二进制日志binlog,实时同步到kafka,然后基于flink对数据进行清洗加工,然后推送给最终的kafka数据,在实时直播场景下,常见的也有写入到redis,然后应用系统通过数据服务,高频率刷新读redis。 感谢你的提问~
2020-05-0224 - 你好老师,数仓统计好的表在hive中,然后落地到hbase才能对外提供api,这个场景应该有吧。我想问的是怎么落地到hbase呢?(数据量大的话还得提前预分区hbase) ,两个库之间衔接问题。
作者回复: 我们是基于数据传输这个工具,把数据从Hive抽取到HBase中的,数据传输工具是基于Spark实现的。
2020-05-143  ZSW老师,你好,对于实时数据和离线数据怎么结合这一部分有点疑问,现在离线和实时先分别计算,计算之后,数据是合并到一起呢?我大概想到2两种思路: 1、从物理存储上就合并在一起,离线数据统计结果写入A表,实时统计结果追加到A表?如果这种方式有什么好的实现方案吗? 2、物理存储层面分别存储, 如果分别存储,那如果一个查询查的时间跨度是“从历史数据查到今天的实时数据”,是不是在逻辑层分别取出来之后,再进行合并?
ZSW老师,你好,对于实时数据和离线数据怎么结合这一部分有点疑问,现在离线和实时先分别计算,计算之后,数据是合并到一起呢?我大概想到2两种思路: 1、从物理存储上就合并在一起,离线数据统计结果写入A表,实时统计结果追加到A表?如果这种方式有什么好的实现方案吗? 2、物理存储层面分别存储, 如果分别存储,那如果一个查询查的时间跨度是“从历史数据查到今天的实时数据”,是不是在逻辑层分别取出来之后,再进行合并?作者回复: 你的问题涉及到批流一体了。批计算和流计算,有两种架构,一种是lamda架构,一种是kappa架构。 lamda架构目前在实际企业中落地最多。一般当天数据用实时,过往数据用离线。 kappa架构应该是未来一个趋势,现在数据湖概念比较火热,可以基于iceburg实现批流一体的存储层统一。
2020-05-312 Weehua感谢郭老师的分享。我提2个问题: 1. 数据中台的数据,大部分应该还是离线为主,这些T+1时效性的数据,可以用在核心的业务流程中吗? 2. 实时数据,数据中台和业务中台怎么划清责任边界呢?
Weehua感谢郭老师的分享。我提2个问题: 1. 数据中台的数据,大部分应该还是离线为主,这些T+1时效性的数据,可以用在核心的业务流程中吗? 2. 实时数据,数据中台和业务中台怎么划清责任边界呢?作者回复: HI, 你好,WeehuaZheng, 第一个问题: 实时数据中台一定是数据中台发展的下一站,解决了离线数据的共享和复用,实时数据的复用和共享将会是下一个阶段关注的重点。一般在使用过程中,T+1的统计数据使用离线数据,当天的数据使用实时数据。 第二个问题: 实时数据中台与离线数据中台,在方法论上也是相似的,实时数据中台同样也需要通过数据服务接口的方式对外暴漏服务。业务中台与数据中台的责任边界,数据中台负责统计分析型数据的展现。在大数据量下,业务系统去做实时数据的分析是非常耗资源的,而且还面临指标统计口径问题,所以统一由数据中台对接。 感谢你的提问,欢迎你在留言区与我交流~
2020-05-2322

