

01 | 前因后果:为什么说数据中台是大数据的下一站?

该思维导图由 AI 生成,仅供参考
启蒙时代:数据仓库的出现
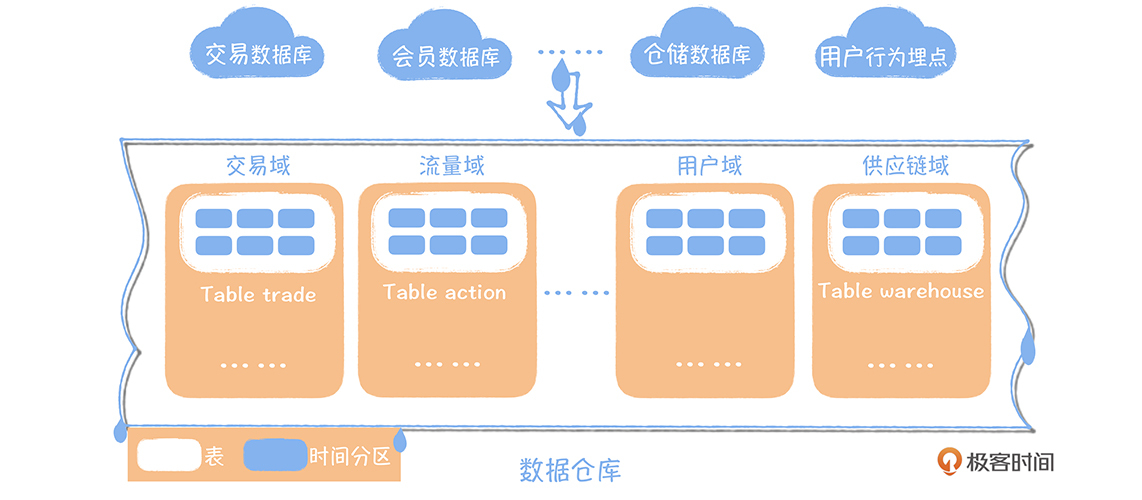
技术革命:从 Hadoop 到数据湖
数据工厂时代:大数据平台兴起
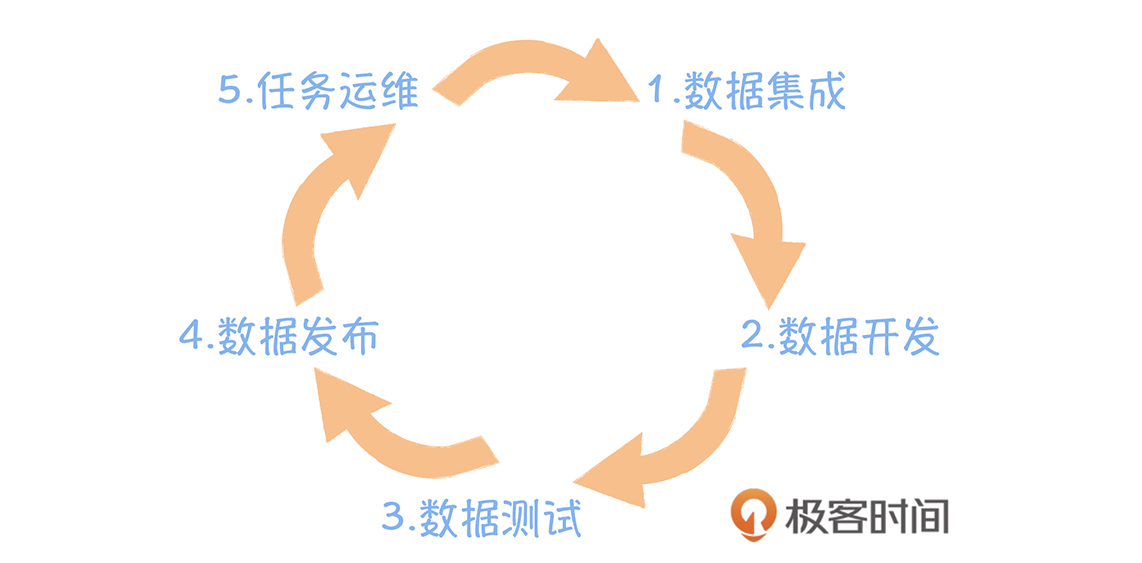
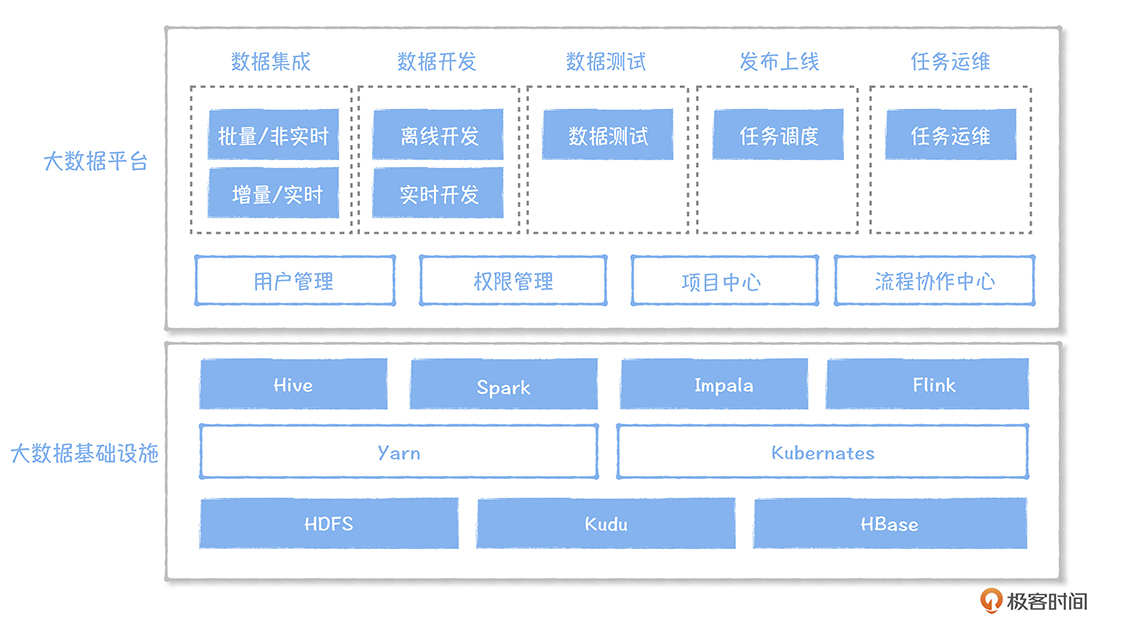
数据价值时代:数据中台崛起
课堂总结

思考时间
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

数据中台作为大数据发展的下一站,是传统数据仓库、数据湖和大数据平台发展历程的延伸和升级。传统数据仓库在90年代诞生,解决了企业数据转化为知识的需求,但随着互联网时代的到来,数据规模和类型的变化使得传统数据仓库无法满足需求。Hadoop的出现为大数据技术普及奠定了基础,而数据湖的概念则标志着Hadoop商用化的开始。数据湖将数据作为企业核心资产,但Hadoop商用化进程受到技术门槛的限制。因此,数据中台作为大数据的下一站,将成为传统企业数字化转型的首选,其发展历程将延续并升级传统数据仓库、数据湖和大数据平台的技术特点,以满足不断变化的商业需求。 数据中台构建于数据湖之上,具备数据湖异构数据统一计算、存储的能力,同时让数据湖中杂乱的数据通过规范化的方式管理起来。数据中台需要依赖大数据平台,大数据平台完成了数据研发的全流程覆盖,数据中台增加了数据治理和数据服务化的内容。数据中台借鉴了传统数据仓库面向主题域的数据组织模式,基于维度建模的理论,构建统一的数据公共层。总的来说,数据中台吸收了传统数据仓库、数据湖、大数据平台的优势,同时又解决了数据共享的难题,通过数据应用,实现数据价值的落地。 在数据中台的发展过程中,大数据平台的兴起为数据研发提供了全流程覆盖的支持,数据中台则增加了数据治理和数据服务化的内容,使得数据能够在一个设备流水线上快速地完成加工。数据中台的核心在于避免数据的重复计算,通过数据服务化提高数据的共享能力,赋能数据应用,从而实现数据价值的落地。数据中台的出现解决了数据无法共享的难题,为企业数字化转型提供了更加高效和可靠的数据支持。 通过数据中台的发展历程,我们可以清晰地看到数据中台诞生的前期、中期和后期的大事件,这有助于更清晰地掌握数据中台的背景和发展脉络。最后,对于数据中台的下一站,我们可以进行发散性的思考,探讨数据中台的未来发展方向,以期为大数据技术的进一步发展提供新的思路和方向。
2020-03-3049人觉得很赞给文章提建议
《数据中台实战课》,新⼈⾸单¥59

全部留言(68)
- 最新
- 精选
 西蒙置顶数据中台的下一站是AI中台。
西蒙置顶数据中台的下一站是AI中台。作者回复: 机器学习是数据中台之上一个重要的应用领域。不是有句话是这么说的,数据和特征决定了机器学习的上限,算法和模型只是在无限的逼近这个上限。 我来谈谈数据中台的下一站到底是什么吧 目前数据中台的主要应用领域还是数据智能领域,所以我们就先不延申到机器学习,深度学习,安全、推荐等领域。 1. 实时数据中台,实现批流一体。 2. 云上数据中台,全面拥抱K8S,实现在线、离线混合部署,进一步提高资源利用率。 3. 智能元数据管理+增强分析,降低数据分析的门槛,进一步释放数据智能 4. 自动化代码构建,通过拖拉拽,自动化生成ETL代码的构建,进一步释放数据研发的效能,甚至让我们的非技术人员都可以完成简单的数据加工。 5. 数据产品的时代,面向各种行业的数据产品全面涌现,并且和中台系统联动,比如基于指标的可分析维度,自动进行指标的业务诊断等等。 我会在我们专栏结束的最后一篇,为大家在详细的展开这些,这里先抛砖引玉,提供给大家思考。
2020-03-31547 李跃爱学习老师讲得非常透彻,值回票价了 1. 传统数据仓库,第一次明确了数据分析的应用场景应该用单独的解决方案去实现,不再依赖于业务的数据库。在模型设计上,提出了数据仓库模型设计的方法论,为后来数据分析的大规模应用奠定了基础。 2. 互联网产品的新特性:数据多、数据类型异构。 3. Google论文指导下的开源项目Hadoop采用分布式、弱化数据格式,来应当面临的问题。 4. 数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。 5. 大数据平台是面向数据研发场景的,覆盖数据研发的完整链路的数据工作台 6. 数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用
李跃爱学习老师讲得非常透彻,值回票价了 1. 传统数据仓库,第一次明确了数据分析的应用场景应该用单独的解决方案去实现,不再依赖于业务的数据库。在模型设计上,提出了数据仓库模型设计的方法论,为后来数据分析的大规模应用奠定了基础。 2. 互联网产品的新特性:数据多、数据类型异构。 3. Google论文指导下的开源项目Hadoop采用分布式、弱化数据格式,来应当面临的问题。 4. 数据湖(Data Lake)是一个以原始格式存储数据的存储库或系统。 5. 大数据平台是面向数据研发场景的,覆盖数据研发的完整链路的数据工作台 6. 数据中台的核心,是避免数据的重复计算,通过数据服务化,提高数据的共享能力,赋能数据应用作者回复: 谢谢,前三篇主要还是从理论上来帮大家对齐概念,精华在实现篇中,有走过的坑,和避坑秘诀,继续看呦~ 欢迎多讨论。
2020-03-3024
 Stefan
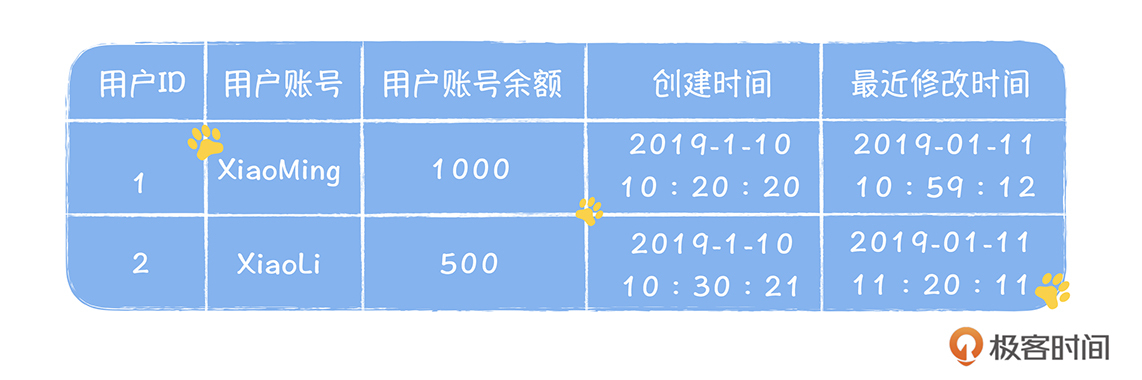
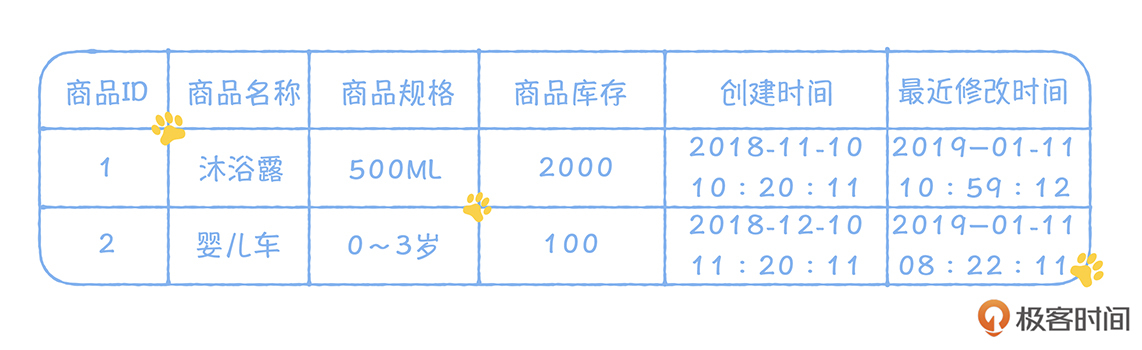
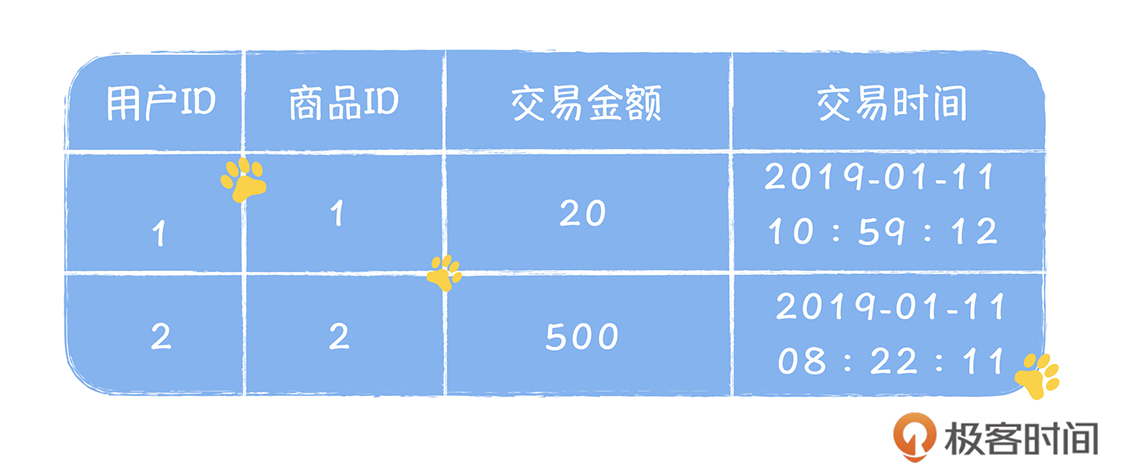
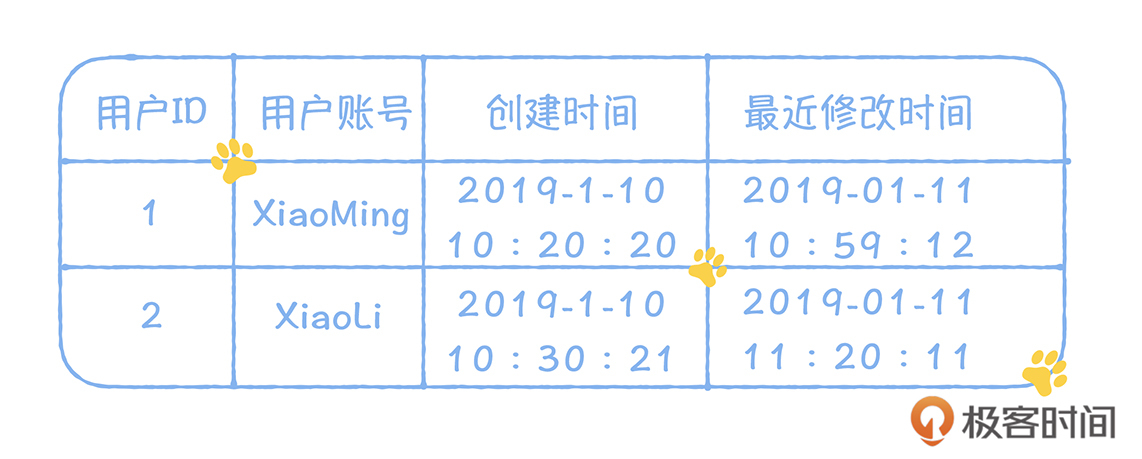
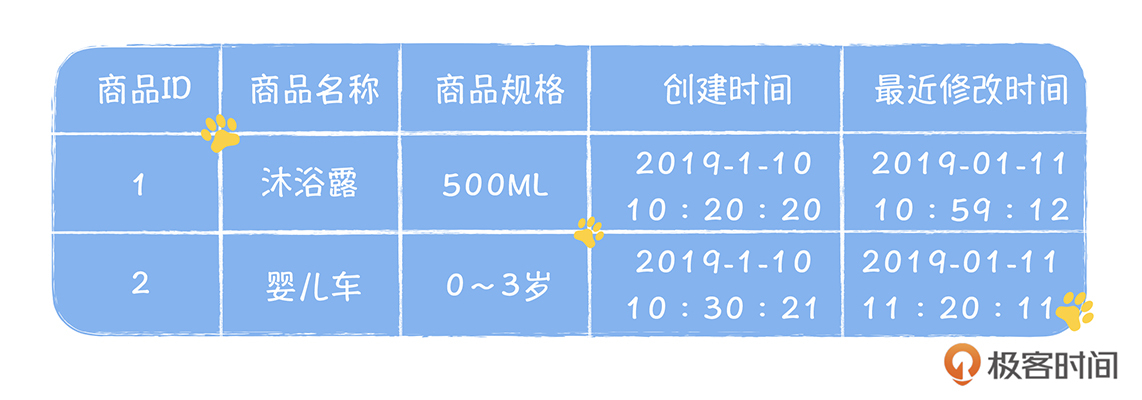
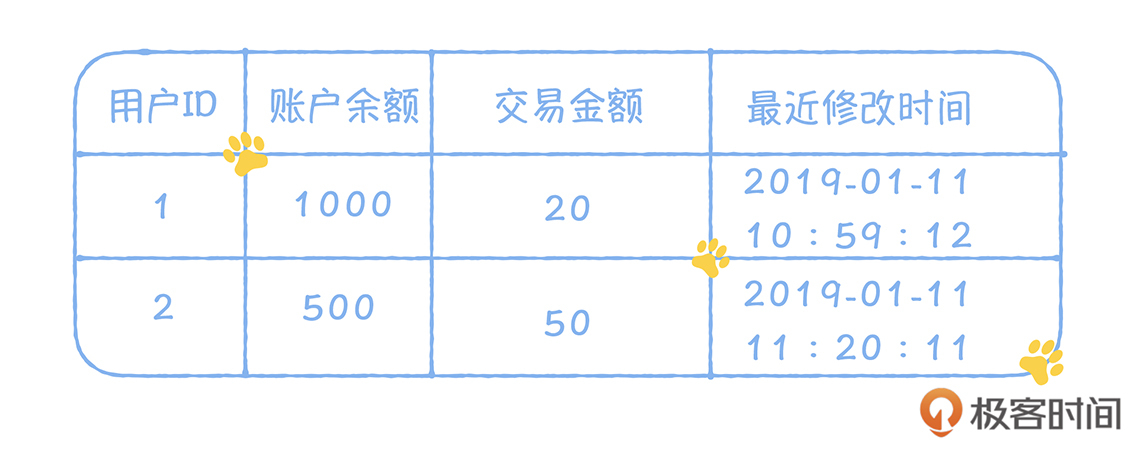
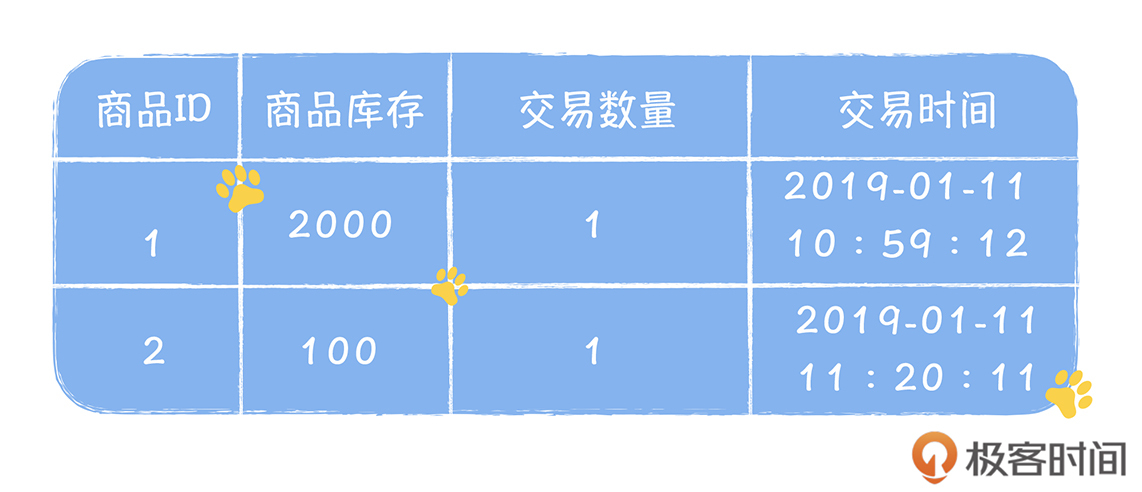
Stefan 老师,金博尔的建模设计方法的例子里面没有提到商品交易的信息,只有用户余额和库存事实表,这是为什么呢?
老师,金博尔的建模设计方法的例子里面没有提到商品交易的信息,只有用户余额和库存事实表,这是为什么呢?作者回复: 在kimball建模中,只有事实和维度, 交易过程中涉及账户余额和库存,这都属于事实,而维度就是商品。因为从分析的角度,我们只关心事实在不同维度下的结果。而在商品交易中,我们需要分析的交易金额和账户余额,这都呈现在用户账户余额事实表中,只要在这个表中再关联商品的维度,就可以按照商品来分析,一个商品的交易金额。 比如,我们的余额事实表中,再增加一列代表商品的ID,每一个交易,都占用一行,代表交易完成后,用户余额和交易金额的数据。这样你就能实现从商品维度来分析交易金额的需求了。
2020-03-31418 闻人正卿郭老师您好,看了您的三篇文章受益匪浅,迫不及待地想看后面的文章。 我认为数据中台目前能看到的未来趋势有3点:流批统一、可视化建模与SQL建模、上云。 1)可视化建模与SQL建模,不管是在建设数据中台或者数据平台,这种做法都是一种抽象、流程化的体现,能大大降低数据开发的成本而且清晰。不过这其中的复杂度确实挺高,自己深有体会。 2)流批一体。降低大数据架构的整体运维成本 3)上云。节约成本,提高资源利用率 在这里有几个问题想请教您: 1.当数据中台发展到一定的程度时,数据中台或者数据平台会不会成为云上的基础服务?对于中小型企业而言,建设一套这样的平台成本太大,但是通过云服务提供平台基础设施与计算能力,企业就能把资源集中于对企业内部数据价值的挖掘上面? 2.如果上面这个问题说的是对的,那么到时候企业对于数据工程师的能力要求会侧重于哪里?是数据分析与数据挖掘的能力吗?还是说数据平台的建设与维护的能力也是很必要的一个技能? 3.我认为特征工程、ai都是数据中心比较上层的应用,通过特征工程与ai计算出来的模型,反馈作用于下层的ETL数据处理形成闭环,这样的做法是可行的吗?
闻人正卿郭老师您好,看了您的三篇文章受益匪浅,迫不及待地想看后面的文章。 我认为数据中台目前能看到的未来趋势有3点:流批统一、可视化建模与SQL建模、上云。 1)可视化建模与SQL建模,不管是在建设数据中台或者数据平台,这种做法都是一种抽象、流程化的体现,能大大降低数据开发的成本而且清晰。不过这其中的复杂度确实挺高,自己深有体会。 2)流批一体。降低大数据架构的整体运维成本 3)上云。节约成本,提高资源利用率 在这里有几个问题想请教您: 1.当数据中台发展到一定的程度时,数据中台或者数据平台会不会成为云上的基础服务?对于中小型企业而言,建设一套这样的平台成本太大,但是通过云服务提供平台基础设施与计算能力,企业就能把资源集中于对企业内部数据价值的挖掘上面? 2.如果上面这个问题说的是对的,那么到时候企业对于数据工程师的能力要求会侧重于哪里?是数据分析与数据挖掘的能力吗?还是说数据平台的建设与维护的能力也是很必要的一个技能? 3.我认为特征工程、ai都是数据中心比较上层的应用,通过特征工程与ai计算出来的模型,反馈作用于下层的ETL数据处理形成闭环,这样的做法是可行的吗?作者回复: 关于几个问题,谈谈我的看法: 1. 云上数据中台,我认为这一定是个趋势,所以我在数据中台下一站中,特意提到了云上数据中台的建设,目前数据中台是基于Hadoop体系的数据湖构建的,Hadoop是基于Yarn实现资源的调度,这与在线业务系统基于Kubernates实现的云原生是两套,我认为,后续在线和离线会统一,kubernates会成为事实的统一云,然后大数据基于kubernates实现资源调度,事实上,Spark新版本已经实现了。 但是话又要说回来,到底是公有云还是私有云,我倒是持不同的意见。因为数据中台中的数据,往往很多涉及企业的核心机密,比如一些毛利、营业额、供应商对于企业来说,都是核心资产,企业愿不愿意,敢不敢,把数据放在公有云上,这个在国内还不好说。我见到的很多情况,数据都是要求私有化部署的。 2. 未来,不管是私有化部署的云,还是公有云,我认为企业都不会关注在数据平台的建设和维护能力上,因为这部分容易被标准化,而且可能后续价格会很低廉,完全没必要企业自己去搞。我觉得后续企业,还是会更强调数据的应用能力,数据如何深入业务,解决业务的问题。 3. 首先机器学习是数据中台的一个上层应用场景,至于你提到的通过模型反馈于下层的ETL数据处理,这个究竟是怎么方式的反馈? 如果是从模型设计的角度,肯定是可以的,因为机器学习相当于需求方,数据模型的设计肯定要以满足需求方为目标的。 但是你说如何基于上层模型,自动构建下层的ETL任务,这个目前还不成熟,比较可行的方式是通过可视化的方式,降低开发的工作量。
2020-04-01213 leslie还是追溯本源吧:OLAP其实是在OLTP之后出现的,Big Data的概念又是再次之后,中台体现分析时还有共享,hadoop的资源损耗国内DB界一直饱有争议。举个例子:不同类型数据系统之间其实都是明显的有相互学习和继承的影子。 脑洞不用打开:中台体现的数据的集中、大数据体现的分散且快;那么下一步将是再次的分散。这就如同人的行走:不可能全是之路,曾经看到过一本资料中提出岛与海的概念-它的上一页就是Data laker。 中台的方式方法正在摸索和打造:不过和老师的DataSystem在中间件存储的选择上会不同;这就仿佛SRE和DevOps都是效率,可是何种是正解;每个企业应当都有自己的答案。为了中台而中台就失去了其原本的意义。 谢谢分享。
leslie还是追溯本源吧:OLAP其实是在OLTP之后出现的,Big Data的概念又是再次之后,中台体现分析时还有共享,hadoop的资源损耗国内DB界一直饱有争议。举个例子:不同类型数据系统之间其实都是明显的有相互学习和继承的影子。 脑洞不用打开:中台体现的数据的集中、大数据体现的分散且快;那么下一步将是再次的分散。这就如同人的行走:不可能全是之路,曾经看到过一本资料中提出岛与海的概念-它的上一页就是Data laker。 中台的方式方法正在摸索和打造:不过和老师的DataSystem在中间件存储的选择上会不同;这就仿佛SRE和DevOps都是效率,可是何种是正解;每个企业应当都有自己的答案。为了中台而中台就失去了其原本的意义。 谢谢分享。作者回复: “为了中台而中台就失去了其原本的意义” 这句话说的好,数据中台要从解决问题的角度入手,不能解决问题,其实建中台意义不大。
2020-03-319- Geek_97e448请教老师,是否能再解释一下:弱化数据格式,数据被集成到 Hadoop 之后,可以不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可以按照不同的模型读取,满足异构数据灵活分析的需求。
作者回复: 你好, 我们就拿Hive来举例吧。Hive 可以支持location到一个目录。也就是说,数据可以先存储在HDFS的一个目录下,然后再建立Hive表。这样其实Schema和底层的数据实际是分离的。然后我们在用Hive读这个数据的时候,其实是根据hive中定义的表结构去读的,如果有一部分的数据字段hive中没有定义,那其实是读不出来的。 通过Hive的例子,你明白了嘛?可以具体再用hive 实践一下。 感谢你的阅读~
2020-04-2828  吴建中数据中台下一站,取决于数据中台本身存在什么瓶颈,缺陷,制约了快速响应需求。非常赞同老师的总结:流批统一,云上大数据平台,可视化开发,可视化的AI平台,但是感觉没有质的变化,只是在术上的变化,不像大数据技术出现对数据分析的冲击大。
吴建中数据中台下一站,取决于数据中台本身存在什么瓶颈,缺陷,制约了快速响应需求。非常赞同老师的总结:流批统一,云上大数据平台,可视化开发,可视化的AI平台,但是感觉没有质的变化,只是在术上的变化,不像大数据技术出现对数据分析的冲击大。作者回复: 不管是实时数据中台还是自动化ETL,都可以说是数据中台的进一步发展。 但是说到质的变化,我想增强分析和智能元数据管理或许是一个,只是目前的时机还不够成熟。试想一下,如果以后,可以实现智能的分析,你问它,为什么销售额下降了,它可以直接告诉你原因,这个是不是足够牛逼?
2020-04-0128 邢爱明请教老师一个问题,传统企业是数据容量和类型是比较固定的,以前也有了数据仓库的应用,在什么场景下需要演建设数据中台? 如果要建,是否必须基于hadoop类的大数据平台?
邢爱明请教老师一个问题,传统企业是数据容量和类型是比较固定的,以前也有了数据仓库的应用,在什么场景下需要演建设数据中台? 如果要建,是否必须基于hadoop类的大数据平台?作者回复: 数据中台一定是构建在数据湖之上的,这是与传统数据仓库,基于Oracle去构建,有本质的区别的。 原先数据仓库只能支持一些简单的报表,对数据的加工和处理能力都非常的有限,根本就没有办法支撑大规模的数据应用场景。如果你想实现数字化转型,真正让数据能够走入业务,让我们的业务人员每天看数据工作,那你就要构建数据中台了。 比如我们有一个零售的客户,他们构建了数据中台,然后在上面做了门店管家,数据应用,现在他们全国2W多家门店,每天都有大量的店员在看,有哪些商品卖的好,哪些卖的不好,哪些商品库存比较大,客户比较偏好买哪些商品,然后就会有针对性的推荐商品,或者调整商品的摆位。大幅度提高了门店的营业收入,这就是一个典型的数据中台的应用。
2020-03-3047 西西弗与卡夫卡数据中台试图解决数据共享的问题,特别企业内部。再下一步,脑洞一下,我觉得数据要成为能在全社会共享的资源,像水和电那样,无处不在,按需索取。成为一种推动社会发展的信息能源。不妨叫数据能源?
西西弗与卡夫卡数据中台试图解决数据共享的问题,特别企业内部。再下一步,脑洞一下,我觉得数据要成为能在全社会共享的资源,像水和电那样,无处不在,按需索取。成为一种推动社会发展的信息能源。不妨叫数据能源?作者回复: 想法太超前,数据是企业的核心资产,微信可能共享数据给其他企业嘛?
2020-03-3087 王芳数据中台的下一站是数据应用平价、爆发式的增长。数据中台仿佛是进化版的BI,传统BI采用传统的数仓设计方法,现在中台的数仓设计更加强调快速响应业务变化,数据研发更快速实现,更强调带来业务价值。 关于数据湖,有个疑问:数据湖与ods层数据具体区别啥啥?
王芳数据中台的下一站是数据应用平价、爆发式的增长。数据中台仿佛是进化版的BI,传统BI采用传统的数仓设计方法,现在中台的数仓设计更加强调快速响应业务变化,数据研发更快速实现,更强调带来业务价值。 关于数据湖,有个疑问:数据湖与ods层数据具体区别啥啥?作者回复: 数据中台的下一站,我认为确实是数据产品的全面爆发。 至于“数据湖和ODS层数据具体区别?”这个问题, 数据湖与ODS层数据并没有什么关系,数据湖中,不仅有ODS数据,还有DWD,DWS,DM,ADS数据。数据湖是指数据不管存储格式,都统一存储在一起,然后根据数据格式,读取数据,例如Hadoop你可以看成是一个数据湖的实现。 至于ODS,它是数据分层的原始数据层,他和其他层数据一样,可以存储在HDFS构建的数据湖中。 感谢你的阅读,期待与你在留言区再次相遇~
2020-04-176

