

07 | 同事老打脸说数据有问题,该怎么彻底解决?

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

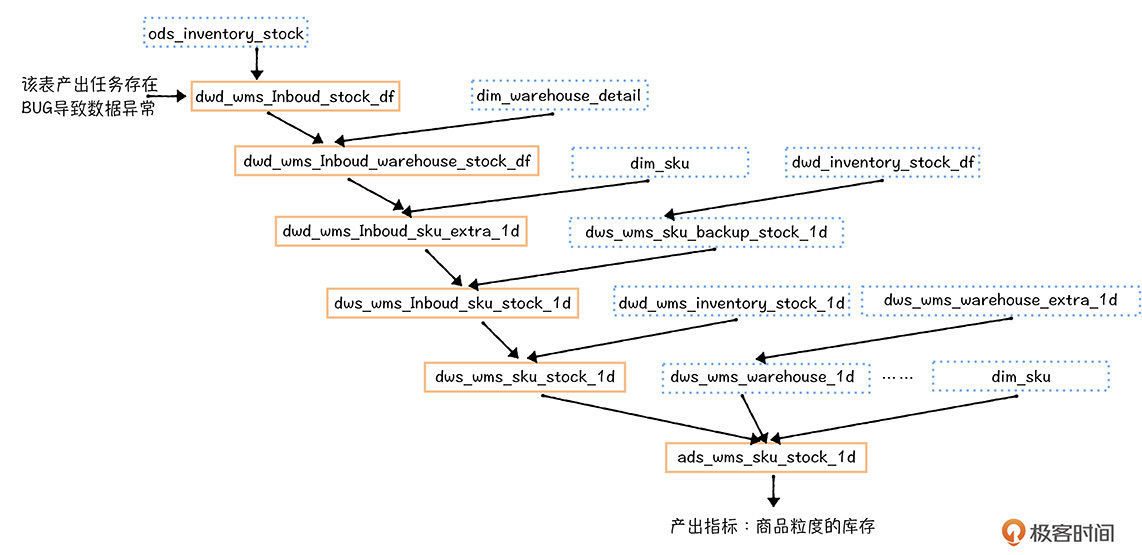
本文介绍了数据质量问题在企业中的重要性以及解决数据质量问题的方法。通过一个实际案例,描述了数据异常对业务运营的影响,并分析了数据质量问题的根源,包括业务源系统变更、数据开发任务变更、物理资源不足和基础设施不稳定等方面。作者提出了提高数据质量的方法,包括添加稽核校验任务,设计一些校验逻辑,确保数据的完整性、一致性和准确性等。文章强调了“早发现,早恢复”的重要性,提出了一套数据质量建设的方法,为读者提供了解决数据质量问题的思路和方法。 文章还介绍了如何衡量数据质量,包括核心任务产出完成率、表级别的质量分数、需要立即介入的报警次数和数据产品SLA等指标。此外,文章还提到了数据质量中心的核心功能,包括稽核校验和基于数据血缘的全链路数据质量监控。 总的来说,本文通过实际案例生动形象地展示了数据质量问题对业务的影响,同时提出了解决问题的方法,对于企业数据管理和数据质量保障具有一定的指导意义。
《数据中台实战课》,新⼈⾸单¥59

全部留言(35)
- 最新
- 精选
 吴科🍀数据部门作为下游系统,上游业务系统变更,往往不能第一时间通知,第二天跑批是才发现,早晨五点起来处理太平常不过了。 资源抢占也时常发生,分析师临时加了一个任务跑全量的数据,还加到了资源主列队中,第二天所有跑批都延迟了。 数据部门,要规范各种数据相关的变更才能解决。实际中,我们数据部门都是弱势的。 😂
吴科🍀数据部门作为下游系统,上游业务系统变更,往往不能第一时间通知,第二天跑批是才发现,早晨五点起来处理太平常不过了。 资源抢占也时常发生,分析师临时加了一个任务跑全量的数据,还加到了资源主列队中,第二天所有跑批都延迟了。 数据部门,要规范各种数据相关的变更才能解决。实际中,我们数据部门都是弱势的。 😂作者回复: 你说的都是大实话。 我真心觉得数据开发真是苦逼的职位,白天忙需求,晚上接报警,因为指标业务口径不一致、数据质量问题天天被人怼,处于弱势地位,工具产品也不到位,所以需要数据中台来拯救他们。 感谢你的阅读,期待与你在留言区再次相遇~
2020-04-17525 君为DQC 全链路监控功能不错,还需要在各个节点上增加执行时间和时长,监控各节点执行时长也很重要。 节日促销异常问题:可以将监控的所有指标作为数据,通过机器学习训练出稽核规则模型,这样每天每次任务跑完的指标,由稽核规则模型判别这次任务是否为异常。
君为DQC 全链路监控功能不错,还需要在各个节点上增加执行时间和时长,监控各节点执行时长也很重要。 节日促销异常问题:可以将监控的所有指标作为数据,通过机器学习训练出稽核规则模型,这样每天每次任务跑完的指标,由稽核规则模型判别这次任务是否为异常。作者回复: 赞, 确实基于AI去判断稽核失败到底是正常失败还是异常失败,是一条可行的路,至少可以降低人接入的频率。Good! 感谢你的阅读,期待与你再次相遇~
2020-04-1711- 叫我小名有这样一个场景,上游业务系统变更(表结构变更等),怎么自动通知到数据人员这边
作者回复: 你好,我来介绍一下我们这边的方案。 你说的这是一个很典型的协作问题导致的数据质量问题,而且在一般的数据团队中还很常见。 我们所有数据库的变更都是经过工单系统提交,由DBA审核后,自动执行的。我们在工单系统中增加了一个环节,就是如果涉及到表结构变更,会根据数据血缘,找到它影响到数据中台原始数据的表的负责人,并在负责人确认以后,才能继续执行下去,这样就保证了业务系统数据库变更能够通知到数据负责人了。 这里,依赖全链路数据血缘,这里不仅仅是数据中台内的大数据加工的血缘,还要包括数据导入和导出任务的血缘,所以你才能建立业务系统源数据库源表到数据中台某张hive表的血缘关系。这个可以通过数据传输中心中,把血缘关系传递给元数据中心实现。 感谢你的阅读~
2020-04-234  leslie数据规则,各自为战。最近刚碰到数据问题,历史遗留下来的数据库设计造成的坑;虽然之前指定了一堆相应的规则,可是提交层还是出了不少隐患。 提交到平台其实是一个不错的方式与方法:多方面皆有隐患,今天的课程倒是引发了一些思路和操作方式。 现在来回答今天的问题:误判的原因是源自对于某些表的数据量或者说设计上做复杂了,过于精细有时反而会细致过度;例如我们经常会看到云数据库的分析报告,正确率是站在365天的基础上而非每年的数个双11类似场景的,这其实就是需要对于项目的理解,数据的设计越复杂在特殊场景的适用性越难准确;这其实是一个蛮纠结的事情。 谢谢老师今天的分享,期待后续的分享。
leslie数据规则,各自为战。最近刚碰到数据问题,历史遗留下来的数据库设计造成的坑;虽然之前指定了一堆相应的规则,可是提交层还是出了不少隐患。 提交到平台其实是一个不错的方式与方法:多方面皆有隐患,今天的课程倒是引发了一些思路和操作方式。 现在来回答今天的问题:误判的原因是源自对于某些表的数据量或者说设计上做复杂了,过于精细有时反而会细致过度;例如我们经常会看到云数据库的分析报告,正确率是站在365天的基础上而非每年的数个双11类似场景的,这其实就是需要对于项目的理解,数据的设计越复杂在特殊场景的适用性越难准确;这其实是一个蛮纠结的事情。 谢谢老师今天的分享,期待后续的分享。作者回复: 感谢你的肯定和鼓励,看到能够引发你的一些思考,我真的觉得这篇文章还是很有意义的。 再来谈谈我在课后留的这个问题。其实稽核监控的规则设定,都是根据日常流量的正常波动范围来设定的,如果遇到大规模的引流或者重大促销,必然会不适用,所以如果不调整,大促期间,稽核监控基本全部会触发报警,也失去了早发现早恢复的用途。 所以一般在大促期间,我们一般会根据历史大促的经验,预留一些Buffer,来调整稽核监控。 感谢你的阅读,期待与你再次相遇~
2020-04-174 Weehuaazkaban.flow.1.days.ago,看到这个参数,请问郭老师,你们网易的任务调度系统是用azkaban吗?还是在此基础上做了二次开发?我们团队2018-2019就是用azkaban做调度的,为了方便设置前后依赖,我们采用了flow依赖,每一层是一个flow,比如ods_flow,dwd_flow,但这样会存在木桶原理,每个flow的结束时间就是最长的那个任务,当有几千个任务的时候,任务运行非常不稳定,每天凌晨人肉值班,非常辛苦。
Weehuaazkaban.flow.1.days.ago,看到这个参数,请问郭老师,你们网易的任务调度系统是用azkaban吗?还是在此基础上做了二次开发?我们团队2018-2019就是用azkaban做调度的,为了方便设置前后依赖,我们采用了flow依赖,每一层是一个flow,比如ods_flow,dwd_flow,但这样会存在木桶原理,每个flow的结束时间就是最长的那个任务,当有几千个任务的时候,任务运行非常不稳定,每天凌晨人肉值班,非常辛苦。作者回复: HI, 你好,WeehuaZheng, 我们的调度系统是基于开源的azkaban 进行的二次开发,至于你提到的flow之间的依赖,我们支持跨flow的job之间的依赖设置,这个属于自研的feature,基本原理是在job运行前,会周期性的检查前置依赖节点运行状态,只有依赖job 运行完成后,才能被执行。这个可以避免你说的flow级别的依赖木桶效应。 感谢你的提问,欢迎你有任何数据建设中的问题,在留言区与我们分享~祝好~
2020-05-223 外星人额外起任务做数据校验和资源额外使用,怎么做衡量啊?
外星人额外起任务做数据校验和资源额外使用,怎么做衡量啊?作者回复: 你好,数据质量的稽核监控,本质上也是提交了一个数据校对任务到yarn上执行,必然会涉及到计算资源的消耗。所以并不是每个表都需要稽核监控,只有核心链路的表才需要稽核监控。 那问题来了,什么是核心链路的表,这个主要取决于应用,只有影响到下游核心应用的表,才是核心表,这些表需要添加稽核监控。比如,老板每天都要看的KPI报表,上游产出链路的所有的表,都需要添加稽核监控~ 感谢你的提问,你的问题挺好的,相信很多人都有这样的困惑~祝好~
2020-05-213 你好老师,对于DQC中的规则控制里的强弱规则,是怎么控制调度流程继续或者终止的呢?怎么实现的。。。谢谢老师
你好老师,对于DQC中的规则控制里的强弱规则,是怎么控制调度流程继续或者终止的呢?怎么实现的。。。谢谢老师作者回复: 你好,通过azkaban中任务执行的后置检查条件执行的,在任务执行后,会自动开始执行稽核校验任务,如果任务失败的话,调度系统会根据任务的执行结果,中断任务流的执行。 感谢你的提问,期待下次与你再会~
2020-04-273 keke给这种大促活动单独设定一套稽查规则,随时切换~
keke给这种大促活动单独设定一套稽查规则,随时切换~作者回复: 你好,你说的确实是一种可行的方法,不过,一般可以通过横向对比数据之间的一致性趋势来进行数据的初步判断。 感谢你的留言~祝好~
2020-05-202- zhuxueyu来自传统企业的科技公司的大数据部门。 公司数据质量问题的根因更多是: 1、业务终端人员操作不规范,导致数据错误、数据不一致等 2、某一类系统设计欠缺,导致缺少核心字段等 诸如上面两种根因,单纯是从数据层面建立全链路监控,只能监测到数据的表象问题。但整个过程最令人头疼往往是要解决上游终端/系统的规范性操作、合理设计等问题
作者回复: 你好, 这部分还是要从流程规范的层面来推动业务系统的改造。 举个例子来说吧,对于日志格式的规范,要与业务系统定义好日志的格式,我们有一个日志管理平台,可以定义日志格式,然后监测不符合规范的日志,出现问题,第一时间发现,推动业务系统改造。
2020-05-1432 - JohnT3e关于全链路监控深有体会。如果问题不早发现,而最终由业务反馈的话,可能会面临整个数据流程的数据回滚和重新加工,进而引发连锁反应,导致更多任务超时或者错误。
作者回复: 看来你也遇到了,哈哈。希望07数据质量的介绍对你有所帮助,能够解决你当前面临的问题~
2020-04-172

