

基于DDD的微服务设计实例代码详解

该思维导图由 AI 生成,仅供参考
项目回顾
请假微服务采用的 DDD 设计思想
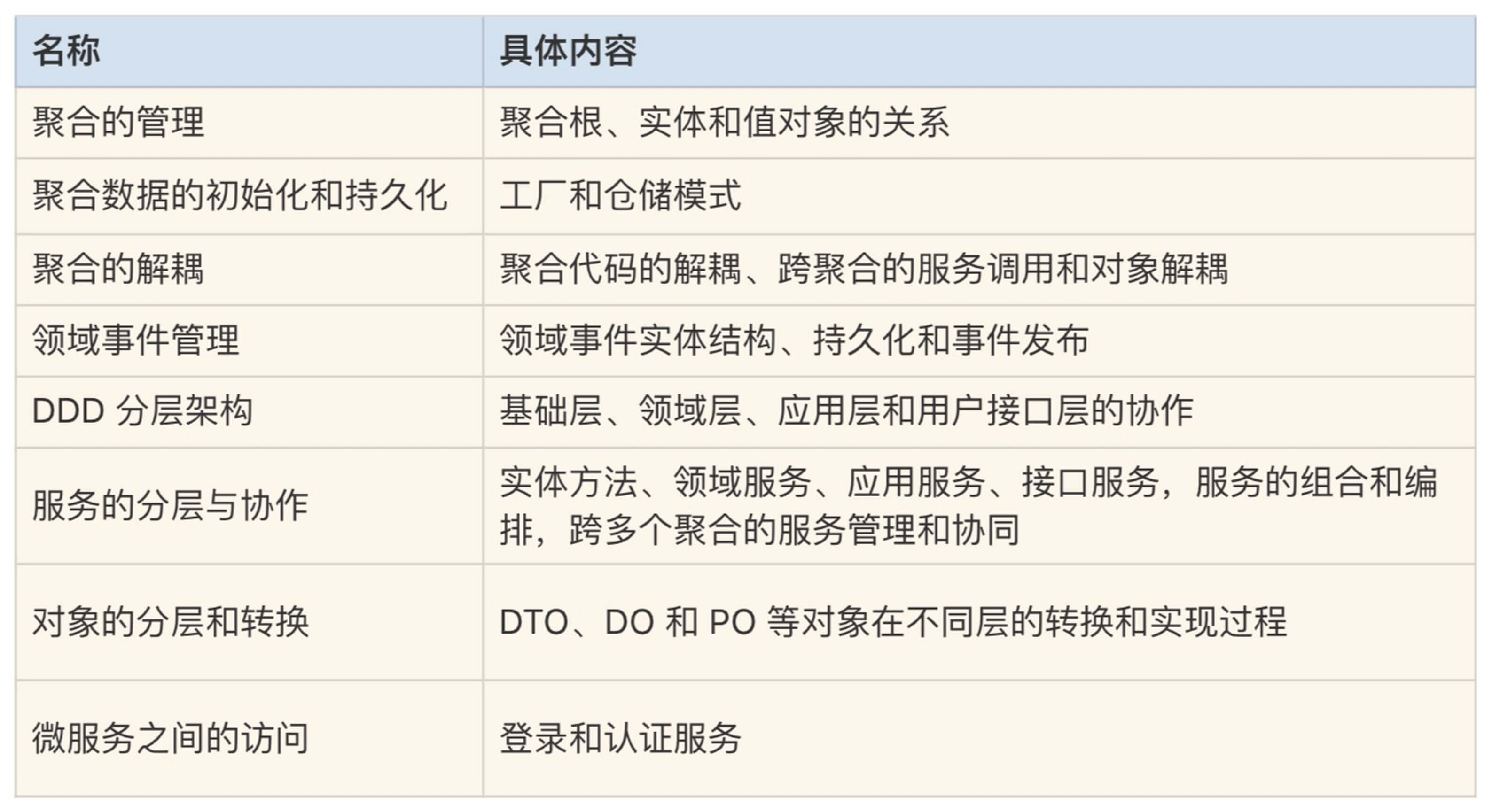
聚合中的对象
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了基于领域驱动设计(DDD)的微服务设计实例代码。通过在线请假考勤项目为例,围绕请假微服务展开,详细介绍了聚合中的对象、实体、值对象以及领域服务的设计思想和方法。文章通过代码示例阐述了聚合根、实体和值对象之间的关系,以及领域服务的开发注意事项。此外,还介绍了领域事件的产生和管理,以及领域事件的执行逻辑、数据持久化和仓储模式。另外,文章还介绍了工厂模式在领域驱动设计中的应用。在微服务演进和聚合重组时,文章详细介绍了微服务聚合拆分时的代码演进,以及服务接口的提供。总的来说,本文通过实例代码详解了微服务中采用的DDD设计思想和方法,为读者提供了深入理解微服务设计的实践知识。文章还强调了微服务设计和开发要做到未雨绸缪,解耦是关键,以及微服务内各层的解耦。通过本文,读者可以逐步引入适合自己的DDD方法和技术,建立适合自己的DDD开发模式和方法体系。
《DDD 实战课》,新⼈⾸单¥59

全部留言(143)
- 最新
- 精选
 冬青置顶偶是编辑,这篇加餐比较长~作者会抽周末的时间把音频讲解为大家补上。感谢等待!2020-01-02128
冬青置顶偶是编辑,这篇加餐比较长~作者会抽周末的时间把音频讲解为大家补上。感谢等待!2020-01-02128 Din老师,您好!请教一个关于repository使用的问题 在DDD的原则里,repository操作的都是聚合根,repository的作用就是把内存中的聚合根持久化,或者把持久化的数据还原为内存中的聚合根。repository中一般也只有getById,save,remove几个方法。 例如取消订单的场景,我其实只需要更新order的状态等少数几个字段,但是如果调用repository的save方法,就会把订单其他字段以及订单明细数据都更新一次,这样就会造成性能影响,以及数据冲突的问题。 针对这个问题,我想到两种解决方案: 1. 在repository增加只更新部分字段的方法,例如只更新订单状态和取消时间 saveOrderCancelInfo(),但这样会对repository有一定的污染,并且感觉saveOrderCancelInfo掺杂了业务逻辑 2. 在repository的save方法中,通过技术手段,找出聚合根对象被修改的数据,然后只对这些数据字段做更改。 老师,您有什么建议呢?
Din老师,您好!请教一个关于repository使用的问题 在DDD的原则里,repository操作的都是聚合根,repository的作用就是把内存中的聚合根持久化,或者把持久化的数据还原为内存中的聚合根。repository中一般也只有getById,save,remove几个方法。 例如取消订单的场景,我其实只需要更新order的状态等少数几个字段,但是如果调用repository的save方法,就会把订单其他字段以及订单明细数据都更新一次,这样就会造成性能影响,以及数据冲突的问题。 针对这个问题,我想到两种解决方案: 1. 在repository增加只更新部分字段的方法,例如只更新订单状态和取消时间 saveOrderCancelInfo(),但这样会对repository有一定的污染,并且感觉saveOrderCancelInfo掺杂了业务逻辑 2. 在repository的save方法中,通过技术手段,找出聚合根对象被修改的数据,然后只对这些数据字段做更改。 老师,您有什么建议呢?作者回复: 你这个问题很好!记得去年thoughtworks的梅雪松老师提过一个方案,你可以通过以下链接看一下https://zhuanlan.zhihu.com/p/87074950。 方案的核心是Aggregate<T>容器,T是聚合根的类型。Repository以Aggregate<T>为核心,当Repository查询或保存聚合时,返回的不是聚合本身,而是聚合容器Aggregate<T>。Aggregate<T>保留了聚合的历史快照,因此在Repository保存聚合时,就可以与快照进行对比,找到需要修改的实体和字段,然后完成持久化工作。
2020-11-20718 杨杰欧老师,有个关于充血模型的问题跟您探讨一下。 我研究DDD也有一段时间了,在某几个项目里面也推动团队采用DDD的设计思想,实体采用了充血模型(entity和po分开),在项目真正运行的过程中发现了几个问题: 1、由于我们的项目规模比较大,数据结构比较复杂,变动也比较频繁。每次有数据结构调整的时候改动的工作量比较大,导致团队成员比较抵触。 2、实体是充血模型的话,可以看成实体本身是有状态的。但是在一些逻辑比较复杂的场景下感觉操作起来会有点儿复杂。 最终实际的结果就是,整个团队这个充血模型用的有点儿不伦不类了。我的想法是这样的:按照DDD的设计思想,我个人觉得关键点是领域的边界,至于要不要用充血模型感觉不是那么重要(尤其是在团队整体的思想和能力达不到这么高的要求下),不知道您在实际的工作中是怎么平衡这个的。
杨杰欧老师,有个关于充血模型的问题跟您探讨一下。 我研究DDD也有一段时间了,在某几个项目里面也推动团队采用DDD的设计思想,实体采用了充血模型(entity和po分开),在项目真正运行的过程中发现了几个问题: 1、由于我们的项目规模比较大,数据结构比较复杂,变动也比较频繁。每次有数据结构调整的时候改动的工作量比较大,导致团队成员比较抵触。 2、实体是充血模型的话,可以看成实体本身是有状态的。但是在一些逻辑比较复杂的场景下感觉操作起来会有点儿复杂。 最终实际的结果就是,整个团队这个充血模型用的有点儿不伦不类了。我的想法是这样的:按照DDD的设计思想,我个人觉得关键点是领域的边界,至于要不要用充血模型感觉不是那么重要(尤其是在团队整体的思想和能力达不到这么高的要求下),不知道您在实际的工作中是怎么平衡这个的。作者回复: 如果实在团队不好处理,那你先以聚合为单位划好边界,在聚合内可以抛弃聚合根之类的这些概念,聚合内都是领域服务,毕竟微服务的演进是以聚合为单位演进的,聚合内高内聚,聚合之间松耦合。其它的DDD的一些设计要求尽量要遵循。
2020-03-2711 CN....老师好,浏览代码有两点疑惑 1,我们通常会认为加了事务注解就尽量避免除数据库外的其他调用,但是代码中在领域服务中的方法中发送mq,而且是在有事务注解的方法中,这里是基于什么考虑 2,消费mq的逻辑应该属于那一层 谢谢
CN....老师好,浏览代码有两点疑惑 1,我们通常会认为加了事务注解就尽量避免除数据库外的其他调用,但是代码中在领域服务中的方法中发送mq,而且是在有事务注解的方法中,这里是基于什么考虑 2,消费mq的逻辑应该属于那一层 谢谢作者回复: 1、这个主要是考虑业务数据,事件数据持久化和发送消息队列同时能够成功,避免出现数据不一致的情况。当然也可以只在业务数据和事件数据持久化增加事务,如果消息队列发送不成功,还可以从事件表中获取数据再次发送。 2、消息订阅方一般在应用层监听和接受事件数据。
2020-01-0637 盲僧太棒了,这个案例太精彩
盲僧太棒了,这个案例太精彩作者回复: 😄
2020-01-036 Jupiter受益匪浅啊,感谢欧老师的课,理论和实践并存,而且值得多刷几遍去深刻理解DDD的思想。我现在的项目中能感觉有一点DDD的影子,但是我打算在我Master的作业上用一下DDD去构建一个推荐系统应用,可能会因为用DDD而用DDD,但是因为是课程设计,所以想多实践一下。有一个小问题是关于DDD里面的对象的,在前面的课程中,您提到有VO, 我现在在开发的时候 前端传给后端的对象 我使用DTO, 但是后端返回给前端的对象,我直接VO,没有中间DTO转化成VO的操作,请问这样也是可以的吧?谢谢老师。期待老师还有新的专栏分享。
Jupiter受益匪浅啊,感谢欧老师的课,理论和实践并存,而且值得多刷几遍去深刻理解DDD的思想。我现在的项目中能感觉有一点DDD的影子,但是我打算在我Master的作业上用一下DDD去构建一个推荐系统应用,可能会因为用DDD而用DDD,但是因为是课程设计,所以想多实践一下。有一个小问题是关于DDD里面的对象的,在前面的课程中,您提到有VO, 我现在在开发的时候 前端传给后端的对象 我使用DTO, 但是后端返回给前端的对象,我直接VO,没有中间DTO转化成VO的操作,请问这样也是可以的吧?谢谢老师。期待老师还有新的专栏分享。作者回复: VO实际上是前端应用的对象,跟后端微服务关系不大,如果DTO与VO之间是一对一关系的话,DTO实际上就是VO的一种数据形式,就不需要再进行转换了。 其实引入PO、DO、DTO、VO这几个对象主要是为了各层解耦,保证领域模型和逻辑的稳定。如果各层对象是一一对应的话,我们没必要增加转换的过程,毕竟对象之间的转换会影响应用性能。
2020-09-125 川川老师你好 我看你在文章有个疑惑的点,我看你在文章里面提到“应避免不同聚合的实体对象,在不同聚合的领域服务中引用,这是因为一旦聚合拆分和重组,这些跨聚合的对象将会失效” 但是我看Approver实体的fromPerson方法就是用person聚合的尸体作为参数传递,这个是不是有违背原则呢。
川川老师你好 我看你在文章有个疑惑的点,我看你在文章里面提到“应避免不同聚合的实体对象,在不同聚合的领域服务中引用,这是因为一旦聚合拆分和重组,这些跨聚合的对象将会失效” 但是我看Approver实体的fromPerson方法就是用person聚合的尸体作为参数传递,这个是不是有违背原则呢。作者回复: 你说的这种情况我当时考虑到了,也确实跟原则有冲突。 从代码完整性来讲,如果person聚合和leave聚合被拆分在不同的微服务中,那么从person聚合返回的数据应该是DTO类型的。在leave微服务中我们需要将这个person微服务返回的DTO的数据转换成DO对象,其实在转换时,我们是可以直接将person DTO组装成Approver这个DO对象的,这个转换的过程稍微有点复杂。由于当前person聚合和leave聚合是在同一个微服务中,为了避免带来误解,所以在代码里面并没有体现这种解耦处理方式。
2020-08-284 涛涛老师您好,有两个疑问? 1.applicationService,domianService并没有实现接口,是故意这样设计的吗? 2.订单父单和子单设计成一个聚合好,还是2个聚合好?
涛涛老师您好,有两个疑问? 1.applicationService,domianService并没有实现接口,是故意这样设计的吗? 2.订单父单和子单设计成一个聚合好,还是2个聚合好?作者回复: 1、在应用层和领域层之间业务逻辑和依赖相对固定,为了避免开发的复杂度,因此没有采用面向接口的编程方式。但是面向前端和基础资源时,由于外部变化相对较大,为了适配和解耦,因此采用了面向接口的方式。 2、你说的父单和子单,是不是指订单和订单明细?一般来说订单和订单明细是在一个聚合里面的。
2020-06-2924- Geek_778d19聚合根与领域服务在职责上有些重叠了,在实现的时候如何选择?
作者回复: 理论上,聚合根方法和领域服务都可以组合多个实体对象完成复杂的领域逻辑。但为了避免聚合根的业务逻辑过于复杂,避免聚合根类代码量过于庞大,我个人建议聚合根除了承担它的聚合管理职能外,只作为实体实现与聚合根自身行为相关的业务逻辑。而将跨多个实体的复杂领域逻辑放在领域服务中实现。简单聚合的跨实体领域逻辑,可以考虑在聚合根方法中实现。
2020-05-064  阿玛铭欧老师的回马枪猝不及防
阿玛铭欧老师的回马枪猝不及防作者回复: 😄,舍不得跟大家告别。
2020-01-024

