

07 | DDD分层架构:有效降低层与层之间的依赖

该思维导图由 AI 生成,仅供参考
什么是 DDD 分层架构?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

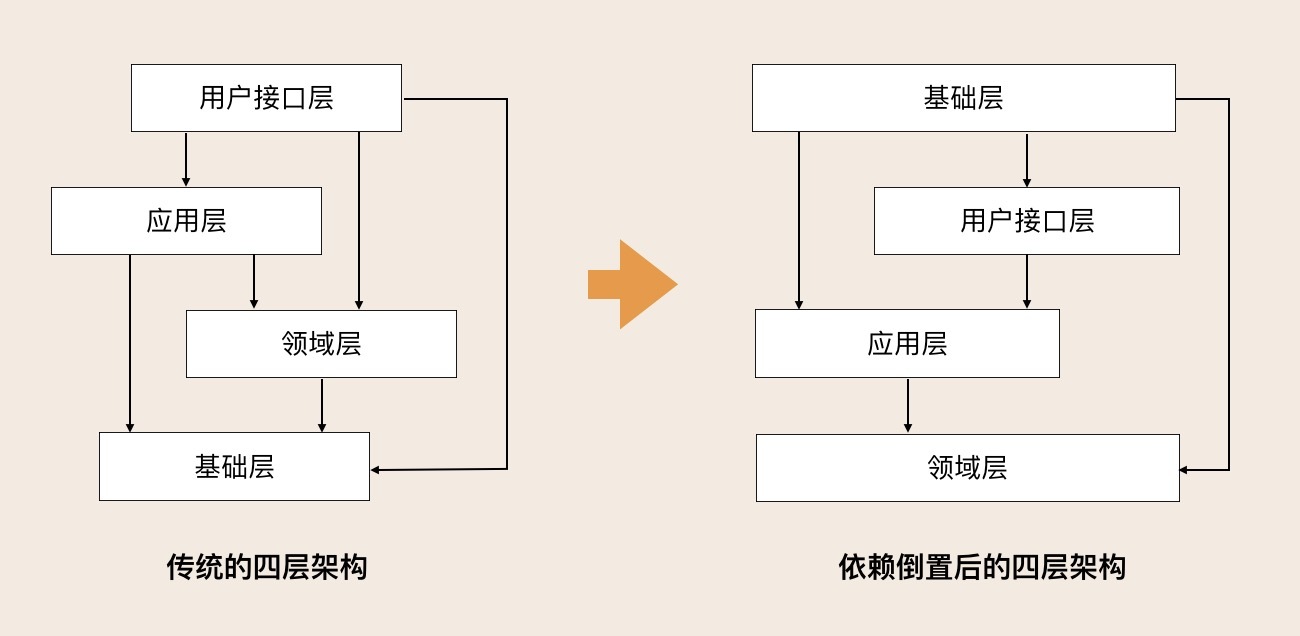
DDD分层架构是一种旨在实现“高内聚低耦合”的架构设计,包括用户接口层、应用层、领域层和基础层。该架构模式通过明确的职责和依赖关系,有效降低各层之间的依赖关系,实现清晰的架构边界,促进架构演进和业务逻辑的清晰表达。在微服务架构的演进过程中,聚合被视为基础单元,可以独立重组或拆分,促进领域模型和微服务架构的演进。另外,DDD分层架构的优势在于降低层与层之间的依赖,使程序结构更加清晰,升级和维护更加容易。在传统三层架构向DDD分层架构的演进过程中,业务逻辑层和数据访问层发生了重大变化,引入了DTO、拆分业务逻辑层的服务到应用层和领域层,以及采用仓储设计模式等。DDD分层架构体现了领域驱动设计思想的演进,为微服务设计带来新的感觉。通过该架构,读者可以深入了解微服务设计和架构演进的需求,以及领域模型的概念,为其架构设计提供新的思路。
《DDD 实战课》,新⼈⾸单¥59

全部留言(142)
- 最新
- 精选
 平平淡淡财是真老师你好,问一个对象命名的问题,例如:VO、DO、DTO、PO、POJO、Entity、model这些使用场景和代表的含义是什么?帖子上看的解释各不相同,很不确定。我的理解是这样的:VO=值对象、DO=PO=POJO=Entity=就是基础的实体对象,DTO=数据传输对象,model=前后端传输的数据模型。 请老师指点一下
平平淡淡财是真老师你好,问一个对象命名的问题,例如:VO、DO、DTO、PO、POJO、Entity、model这些使用场景和代表的含义是什么?帖子上看的解释各不相同,很不确定。我的理解是这样的:VO=值对象、DO=PO=POJO=Entity=就是基础的实体对象,DTO=数据传输对象,model=前后端传输的数据模型。 请老师指点一下作者回复: 在传统的三层架构里面可能没有这么多的对象。而在DDD中增加这些对象主要是为了实现各层以及领域模型中DO对象与前端VO或传输对象DTO和后端数据库PO的解耦。 DDD中主要有一下几类对象。 数据持久化对象 (Persistent Object, PO),与数据库结构一一映射,它是数据持久化过程中的数据载体。 领域对象( Domain Object, DO),微服务运行时核心业务对象的载体, DO 一般包括实体或值对象。 数据传输对象( Data Transfer Object, DTO),用于前端应用与微服务应用层或者微服务之间的数据组装和传输,是应用之间数据传输的载体。 视图对象(View Object, VO),用于封装展示层指定页面或组件的数据。 微服务基础层的主要数据对象是PO。在设计时,我们需要先建立DO和PO的映射关系。大多数情况下DO和PO是一一对应的。但也有DO和PO多对多的情况。在DO和PO数据转换时,需要进行数据重组。对于DO对象较多复杂的数据转换操作,你可以在聚合用工厂模式来实现。 当DO数据需要持久化时,先将DO转换为PO对象,由仓储实现服务完成数据库持久化操作。 当DO需要构建和数据初始化时,仓储实现服务先从数据库获取PO对象,将PO转换为DO后,完成DO数据构建和初始化。 领域层主要是DO对象。DO是实体和值对象的数据和业务行为载体,承载着基础的核心业务逻辑,多个依赖紧密的DO对象构成聚合。领域层DO对象在持久化时需要转换为PO对象。 应用层主要对象有DO对象,但也可能会有DTO对象。应用层在进行不同聚合的领域服务编排时,一般建议采用聚合根ID的引用方式,应尽量避免不同聚合之间的DO对象直接引用,避免聚合之间产生依赖。 在涉及跨微服务的应用服务调用时,在调用其他微服务的应用服务前,DO会被转换为DTO,完成跨微服务的DTO数据组装,因此会有DTO对象。 在前端调用后端应用服务时,用户接口层先完成DTO到DO的转换,然后DO作为应用服务的参数,传导到领域层完成业务逻辑处理。 用户接口层主要完成DO和DTO的互转,完成微服务与前端应用数据交互和转换。 facade接口服务在完成后端应用服务封装后,会对多个DO对象进行组装,转换为DTO对象,向前端应用完成数据转换和传输。 facade接口服务在接收到前端应用传入的DTO后,完成DTO向多个DO对象的转换,调用后端应用服务完成业务逻辑处理。 前端应用主要是VO对象。展现层使用VO进行界面展示,通过用户接口层与应用层采用DTO对象进行数据交互。
2020-10-295146 Jerry.hu老师能否结合一个实战的小项目进行讲解和梳理、同时可以将其项目贡享在git上 让大家结合实战 感觉效果会更好
Jerry.hu老师能否结合一个实战的小项目进行讲解和梳理、同时可以将其项目贡享在git上 让大家结合实战 感觉效果会更好作者回复: 等我有时间的时候准备一下哈。现在的代码都是到类和方法级。
2019-10-28743 FlyFish老师好,可以具体讲讲domain层的service和application层service的区别吗,什么东西该房domian,什么该放application的service,然后application层app和aplication层的service具体又该如何界定,现在有点云里雾里,有点傻傻分不清楚
FlyFish老师好,可以具体讲讲domain层的service和application层service的区别吗,什么东西该房domian,什么该放application的service,然后application层app和aplication层的service具体又该如何界定,现在有点云里雾里,有点傻傻分不清楚作者回复: 我们先从底下往上逐层讲,单个实体自身的方法就是实体本身的业务行为。多个实体可组成更复杂的业务动作,这个是领域服务,实体的方法和领域服务共同构成领域模型的基础业务能力,这个能力是原子的基础的,不太考虑外界的用户行为和流程。而应用服务是对这些基础的能力进行组合和编排,它组合和编排的服务可以是跨聚合的领域服务,主要体现组合后的业务能力,更面向前端的用户操作,属于比较粗粒度的服务,通过编排可以更灵活应对外部需求变化。
2019-12-06232 How2Go已经结束的课程,老师还会回复吗? ---------- 老师,这一节读了几遍,还没有太理解应用服务层。根据课程所说,我的理解是应用服务层会编排领域服务的执行,组织领域服务返回的结果。 但又不是API Gateway -- API Gateway 在基础层。 那么, 这个应用服务层, 是否就是BFF?
How2Go已经结束的课程,老师还会回复吗? ---------- 老师,这一节读了几遍,还没有太理解应用服务层。根据课程所说,我的理解是应用服务层会编排领域服务的执行,组织领域服务返回的结果。 但又不是API Gateway -- API Gateway 在基础层。 那么, 这个应用服务层, 是否就是BFF?作者回复: 应用层连接用户接口层和领域层,它是很薄的一层,主要职能是协调领域层多个聚合完成服务的组合和编排。 应用层之下是领域层,领域层是由多个业务职责单一的聚合构成,实现核心的领域逻辑。应用层负责协调领域层多个聚合的领域服务或领域对象,面向用例和业务流程完成服务的组合和编排。所以理论上应用层不应该实现领域模型的领域逻辑。这也是应用层为什么会很薄的原因。 应用层之上是用户接口层,在应用层完成领域层服务组合和编排后,应用服务被用户接口层Facade服务封装,完成接口和数据适配后,以粗粒度的服务通过API网关面向前端应用发布。 此外,应用层也是微服务之间服务调用的通道,微服务在应用层可以调用其他微服务的应用服务,完成微服务之间的服务组合和编排。 在应用层主要有应用服务、事件订阅和发布等相关代码逻辑。 其中,应用服务主要负责服务的组合、编排和转发,处理业务用例的执行顺序以及结果的拼装。在应用服务中还可以进行安全认证、权限校验、事务控制、领域事件发布或订阅等。 BFF是位于微服务之上,它的主要职责是负责微服务之间的服务协调和编排。而应用服务主要处理微服务内的服务组合和编排,它可以组合和编排领域服务。 在小型项目里,应用服务也可以编排其他微服务的应用服务,我们就没必要增加一层BFF的逻辑了。 在设计时我们应尽可能地将可复用的服务能力往下层沉淀,在实现能力复用的同时,还可以避免跨中心的服务调用。 BFF像齿轮一样,来适配前端应用与微服务之间的步调。通过BFF微服务中的façade接口服务向上适配不同的前端应用,通过协调不同微服务向下实现企业级业务能力的组合、编排和协同。 BFF微服务可根据需求和流程变化,与前端应用版本协同发布,避免微服务为适配不同前端需求的变化,而频繁地修改和发布版本,从而保证微服务版本和核心领域逻辑的稳定。
2020-06-29520 约书亚请问,最后图中MapperXML是什么?是mybatis那种做对象和数据库字段映射的xml文件么?如果是,那其中包含了与业务逻辑无关的数据库具体实现,放在领域层是否不太合适?
约书亚请问,最后图中MapperXML是什么?是mybatis那种做对象和数据库字段映射的xml文件么?如果是,那其中包含了与业务逻辑无关的数据库具体实现,放在领域层是否不太合适?作者回复: 是Mybatis的映射文件。 关于仓储,我是这么考虑的。仓储本身是属于基础层,但是考虑到一个聚合对应一个仓储,为了以后聚合代码整体迁移的方便,我在微服务代码目录设计时,在聚合目录下增加了一个Repository的仓储目录,跟仓储相关的代码都在这个目录下。 这个目录下的代码与聚合的其它业务代码是分开的。如果未来换数据库的话,只需要将Repository目录下的代码替换就可以了。而如果聚合需要整体迁移到其它微服务中去,仓储的代码也会一并迁移。
2019-10-29619 祥敏您好,根据三层架构和DDD四层架构映射这张图,以SSM框架组合谈谈我的理解和问题: 1.三层架构的业务接口层、业务逻辑层、数据访问层,对应实际开发的controller、service和dao三层; 2.图中三层架构中业务逻辑层的VO对应为四层架构中用户接口层的DTO,我的理解是VO原本就在三层架构的用户接口层,在三层架构中也会用DTO竖向穿透三层简化开发。图中的DTO划分为用户接口层,实际只是VO。 3.业务逻辑层中的service拆分为四层架构中的application service和domain service两层,如果以常见的CRUD开发来讲,domain service和applicatioin service是否在简单场景中就重叠了? 4.三层开发中的仓储的依赖倒置已经实现了,mybatis层仓储接口被service层调用,mapper xml作为仓储的接口实现。如果采用DDD四层划分,mapper xml会被划分到基础层。repository aop这里的界面截指的是什么,是指ORM框架内部的bean与关系数据库实体之间的关系映射吗? 5.聚合跟关注实体的持久化:聚合根、实体采用充血模型开发,CRUD中的CUD都会在聚合根、实体中实现,domain service 实现查询功能以及调用充血模型中的CUD方法,这样理解对吗?
祥敏您好,根据三层架构和DDD四层架构映射这张图,以SSM框架组合谈谈我的理解和问题: 1.三层架构的业务接口层、业务逻辑层、数据访问层,对应实际开发的controller、service和dao三层; 2.图中三层架构中业务逻辑层的VO对应为四层架构中用户接口层的DTO,我的理解是VO原本就在三层架构的用户接口层,在三层架构中也会用DTO竖向穿透三层简化开发。图中的DTO划分为用户接口层,实际只是VO。 3.业务逻辑层中的service拆分为四层架构中的application service和domain service两层,如果以常见的CRUD开发来讲,domain service和applicatioin service是否在简单场景中就重叠了? 4.三层开发中的仓储的依赖倒置已经实现了,mybatis层仓储接口被service层调用,mapper xml作为仓储的接口实现。如果采用DDD四层划分,mapper xml会被划分到基础层。repository aop这里的界面截指的是什么,是指ORM框架内部的bean与关系数据库实体之间的关系映射吗? 5.聚合跟关注实体的持久化:聚合根、实体采用充血模型开发,CRUD中的CUD都会在聚合根、实体中实现,domain service 实现查询功能以及调用充血模型中的CUD方法,这样理解对吗?作者回复: 第一,可以这么理解。 第二,从本质来讲,DTO与VO都是对象。但是在DDD中将值传递的界限划分更细,比如DTO、DO、VO、PO,分别对应不同阶段的事务处理。DTO通常面向接口层,与VO相比可能会有前端应用/接口请求方要求的一些个性化的属性或值的映射等。 第三,简单部分可能会有重叠,但是基于不对外暴露领域层逻辑的目的,会将实体方法封装成领域服务,领域服务再封装为应用服务,然后对外暴露。 第四,这层本身是公共类,表示部分持久化的功能被提取为公共的面向切面聚合方法来实现 第五,是这样的。实体值对象的数据逻辑通过聚合根来管理,多实体的业务行为通过领域服务来组合。
2019-11-06315 Jerry银银请教老师:解耦各层对基础层依赖,采用依赖倒置的方式?这有点抽象,不知道是通过什么的一种方法?
Jerry银银请教老师:解耦各层对基础层依赖,采用依赖倒置的方式?这有点抽象,不知道是通过什么的一种方法?作者回复: 给你看一个非常简单的例子,有Person聚合根,Person聚合包括仓储接口和仓储实现。 通过增加仓储服务,使得应用逻辑和数据库逻辑的依赖关系剥离,当换数据库的时候,只需要将仓储实现替换就可以了,这样不会对核心的业务逻辑产生影响。 /** * Person聚合根 */ public class Person{ private String id; private String name; private int age; private boolean gender; /** * 其它方法 */ } /** * Person仓储接口 */ public interface PersonRepositoryInterface { void save(Person person); void delete(String id); } /** *Person仓储实现 */ @Repository public class PersonRepositoryImp implements PersonRepositoryInterface { private PersonMapper mapper; public void save( Person person) { mapper.create(person); } public void delete((String id) { mapper.delete(id); } } 在应用逻辑中直接用仓储的接口就可以了,数据库相关的逻辑在PersonMapper里面实现。 PersonRepositoryInterface personRepos; personRepos.save(person)
2019-12-17413- Geek_d94e60老师您好,请教个问题,微服务拆分后,原来参数类或公共类业务数据 ,每个微服务都会用到,目前有两种方式处理 一,单独抽取一个公共服务,其它微服务都通过接口访问公共类或参数类数据 二,每个微服务都存放该类数据,但只能通过其中一个服务来维护,其它微服务走同步的方式保证数据的一致性 您比较推荐哪种呢?或者是否有其它的思路?
作者回复: 你说的这个情况,我在第20讲的时候会讲到。 提前剧透一下哈。 跨库关联查询是分布式数据库的一个短板,会影响查询性能。在领域建模时,很多实体会分散到不同微服务中,但很多时候会因为业务需求,它们之间需要关联查询。 关联查询的业务场景包括两类:第一类是基于某一维度或某一主题域的数据查询,如基于客户全业务视图的数据查询,这种查询会跨多个业务线的微服务。第二类是表与表之间的关联查询,比如机构表与业务表的联表查询,但机构表和业务表分散在不同的微服务。那如何解决这两类关联查询呢? 对于第一类场景,由于数据分散在不同微服务里,我们无法跨多个微服务来统计这些数据。你可以建立面向主题的分布式数据库,它的数据来源于不同业务的微服务。采用数据库日志捕获技术,从各业务端微服务将数据准实时汇集到主题数据库。在数据汇集时,提前做好数据关联(如将多表数据合并为一个宽表)或者建立数据模型。面向主题数据库建设查询微服务。这样一次查询你就可以获取客户所有维度的业务数据了。你还可以根据主题或场景设计合适的分库主键,提高查询效率。 对于第二类场景,对于不在同一个数据库的表与表的关联查询场景。你可以采用小表广播。在业务库中增加一张冗余的代码副表。当主表数据发生变化时,可以通过消息发布和订阅的领域事件驱动模式,异步刷新所有副表数据。这样既可解决表与表的关联查询,还可以提高数据的查询效率。
2019-11-241012  密码123456感觉用户接口层,存在感好低。仅仅存在调用应用层。 为什么还要存在这个层级?是因为,需要限制用户接口的访问?
密码123456感觉用户接口层,存在感好低。仅仅存在调用应用层。 为什么还要存在这个层级?是因为,需要限制用户接口的访问?作者回复: 用户接口层也很重要啊,主要前后端调用的适配。如果你的微服务要面向很多的应用或渠道提供服务,而每个渠道的入参和出参都不一样,你不太可能开发出太多的应用服务,这样Facade接口就起很好的作用了,包括DO和DTO对象的组装和转换等。
2019-10-2849- Jerry银银领域层之间能直接通信吗? 还是说要交给应用层?
作者回复: 领域层交互会增加聚合之间的耦合,不利于以后微服务的再次拆分和演进,聚合之间的交互建议通过应用服务来总体协调。
2019-12-1627

