

13 | 代码模型(上):如何使用DDD设计微服务代码模型?

该思维导图由 AI 生成,仅供参考
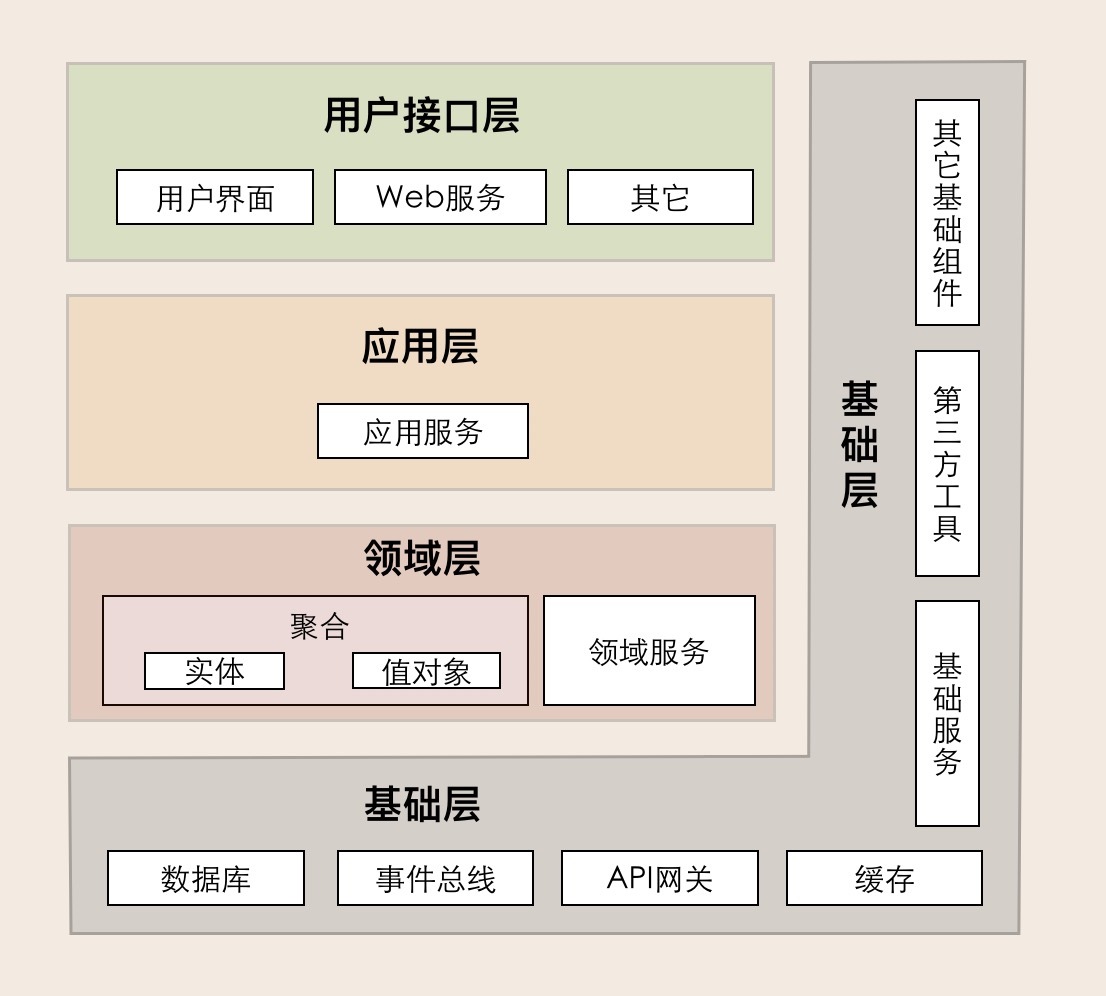
DDD 分层架构与微服务代码模型
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何使用领域驱动设计(DDD)分层架构模型来设计微服务代码模型。作者首先回顾了DDD分层架构模型,包括用户接口层、应用层、领域层和基础层的职责边界。然后,作者提出了微服务代码模型的设计,将一级目录结构分为用户接口层、应用层、领域层和基础层,分别存放与前端交互、应用服务组合和编排、领域核心业务逻辑以及基础资源服务相关的代码。这样的设计可以让项目团队成员更好地理解代码,实现团队协作,避免不必要的代码混淆,并在微服务架构演进时轻松完成代码重构。整体而言,本文通过结合DDD分层架构模型,为读者提供了一种设计微服务代码模型的思路和方法。 文章提到了根据DDD分层架构模型建立标准的微服务代码模型,各代码对象各据其位、各司其职,共同协作完成微服务的业务逻辑。此外,强调了聚合之间的代码边界要清晰,并提出了代码分层的概念,强调应用层和领域层的职责划分。最后,文章提出了思考题,对比了DDD分层架构和三层架构的代码结构的差异,引发读者思考和交流。 总的来说,本文通过详细介绍了微服务代码模型的设计和DDD分层架构模型的应用,为读者提供了丰富的技术内容和实践经验。
《DDD 实战课》,新⼈⾸单¥59

全部留言(97)
- 最新
- 精选
 陈 争不知道我这样理解的对不对 比如执行一个创建用户的命令, 1.用户接口层: 1.1)Assembler->将CustomerDTO转换为CustomerEntity 1.2)Dto->接收请求传入的数据CustomerDTO 1.3)Facade->调用应用层创建用户方法 2.应用层 2.1)Event->发布用户创建事件给其它微服务 2.2)Service: 内部服务->创建用户 外部服务->创建日志 3. 领域层 3.1)Aggregate->进入用户聚合目录下(如:CustomerAggregate) 3.2)Entity->用户聚合跟 3.3)Event->创建用户事件 3.4)Service->具体的创建用户逻辑,比如用户是否重复校验,分配初始密码等 3.5)Repository->将用户信息保存到数据库
陈 争不知道我这样理解的对不对 比如执行一个创建用户的命令, 1.用户接口层: 1.1)Assembler->将CustomerDTO转换为CustomerEntity 1.2)Dto->接收请求传入的数据CustomerDTO 1.3)Facade->调用应用层创建用户方法 2.应用层 2.1)Event->发布用户创建事件给其它微服务 2.2)Service: 内部服务->创建用户 外部服务->创建日志 3. 领域层 3.1)Aggregate->进入用户聚合目录下(如:CustomerAggregate) 3.2)Entity->用户聚合跟 3.3)Event->创建用户事件 3.4)Service->具体的创建用户逻辑,比如用户是否重复校验,分配初始密码等 3.5)Repository->将用户信息保存到数据库作者回复: 是的,就是这样的。理解的很到位。
2019-11-131593 HuAng老师,这种代码分层的优势在哪里?不知道你还看不看留言。
HuAng老师,这种代码分层的优势在哪里?不知道你还看不看留言。作者回复: 分层架构大多是通过前端或后端适配,逐层控制外部变化向领域层传导,从而降低外部变化对领域模型的影响。比如在前端应用中可以消化掉页面逻辑和页面流程类需求;在用户接口层可以完成前端应用接口和数据适配,避免将接口和数据适配类需求传导到应用层;在应用层通过服务组合和编排,可以避免用例或服务组合类需求向领域层传导;在基础设施层通过依赖倒置设计,可以隔离技术组件变化对领域逻辑的影响。 这样由外向里逐层消化和隔离外部变化对领域模型的影响,从而可以最大限度保持领域模型原子性和长期稳定。 一个稳定的领域模型可以给我们带来非常多的好处。 首先,领域模型的构建过程是项目团队通用语言建立的过程,领域模型就是团队的通用语言,它会贯穿项目的所有过程。 其次,领域模型的业务逻辑大多是可复用的原子逻辑,不易受外部变化的影响。将这些核心逻辑沉淀到领域层,让核心逻辑更聚焦,核心代码更内聚。然后在应用层通过应用服务对领域层服务完成组合和编排,可以大量复用领域层的核心业务逻辑代码,从而提升代码复用率。 第三,领域模型的核心代码可交由专门的资深开发人员维护,从而提升代码质量,也能够保证应用关键核心业务逻辑的长期稳定运行。 第四,领域模型内聚合边界更加清晰,可方便微服务以聚合为单位的功能和代码的拆分和重组,让微服务具有更强的演进能力。
2020-12-23225 xj_zh老师,求DDD的系统样例代码。
xj_zh老师,求DDD的系统样例代码。作者回复: 代码样例还没准备好,后面我找时间整理一下吧。
2019-11-18915- FIGNT我们在设计领域模型时,遇到一些问题 1. 查询聚合的操作应该放在哪一层? 2. entity的实体和值对象太多需要分目录吗? 3. 针对实体的维护,需要通过聚合去维护吗?可以直接修改实体吗? 4. 一个聚合保存在一个库里,还是多个聚合都在一个库里?一个实体需要单独放一个库吗?如果一个实体被修改了。用到这个实体的聚合需要更新吗? 5. 聚合是设计成单个的还是批处理的?比如一棵树,业务上是以一片叶子为单位的,那么是以树为聚合还是以叶子为聚合?
作者回复: 1、个人感觉批量大数据量的查询用仓储有点勉强,你可以用传统的方式来做。如果不涉及到领域逻辑的话,可以放应用层。 2、一个微服务的聚合内部应该不会有太多的实体和值对象吧。在目录结构里面是一个聚合一个代码目录。当然如果实在太多,你是可以再分目录的。 3、聚合内的实体数据维护是通过聚合根通过仓储来统一维护的。 4、一个微服务一个库,微服务内的多个聚合可以共用一个库,但是尽量避免聚合之间的表关联,聚合之间的数据要做到松耦合。 5、不清楚你说的单个和批处理是什么意思?聚合是具有一个完整业务功能的单位,就看你业务的粒度大小。多个不同功能的聚合是可以构成一个比较大的业务模块。
2019-11-1413  Farewell丶1.应用服务只能调用领域服务和实体的方法,能调用仓储接口的方法么? 按理说应该隔离,也就是说应用服务应该调用领域服务的方法,再让领域服务调用仓储接口的方法吧? 2.实体的转换只有从用户接口层到应用服务层一次是么?也就是说,到应用服务层之后,以及之后的仓储接口都是可以直接对领域实体进行操作的? 3.参考了Spring Data Jdbc项目,里边也采用了DDD的设计思路,但是发现会需要在实体中配置一些和底层存储相关的注解,这样会不会不能把领域层可仓储实现进行隔离?如果是这样的化,那么Spring Data Jdbc是不是没有严格遵守DDD的一些设计?而且它提供的领域事件的发布机制实现,是在对应的实体中产生的,例如在某一个实体中定义产生领域事件的源头,当对应的实体保存或更新时,就会发出这样一个领域事件。按照咱们文章中讲解的事件的发布是在应用层,那么如果要这样做的话,是不是就需要在应用层重新转发领域层实体内产生的领域事件呢? 因为看到Spring Data这样比较广泛的项目实现和咱们文章的描述有一些我理解上的区别,所以比较困惑和疑问。
Farewell丶1.应用服务只能调用领域服务和实体的方法,能调用仓储接口的方法么? 按理说应该隔离,也就是说应用服务应该调用领域服务的方法,再让领域服务调用仓储接口的方法吧? 2.实体的转换只有从用户接口层到应用服务层一次是么?也就是说,到应用服务层之后,以及之后的仓储接口都是可以直接对领域实体进行操作的? 3.参考了Spring Data Jdbc项目,里边也采用了DDD的设计思路,但是发现会需要在实体中配置一些和底层存储相关的注解,这样会不会不能把领域层可仓储实现进行隔离?如果是这样的化,那么Spring Data Jdbc是不是没有严格遵守DDD的一些设计?而且它提供的领域事件的发布机制实现,是在对应的实体中产生的,例如在某一个实体中定义产生领域事件的源头,当对应的实体保存或更新时,就会发出这样一个领域事件。按照咱们文章中讲解的事件的发布是在应用层,那么如果要这样做的话,是不是就需要在应用层重新转发领域层实体内产生的领域事件呢? 因为看到Spring Data这样比较广泛的项目实现和咱们文章的描述有一些我理解上的区别,所以比较困惑和疑问。作者回复: 1、如果是应用服务直接调用文件或者缓存之类的,应用服务是可以之间调用仓储的。但如果中间有领域实体和数据库,则需通过领域服务,然后通过聚合根来调用仓储。 2、用户接口层大多是DTO,应用层和领域层大多是DO,基础层则是PO,在不同层之间是需要进行数据转换的。我有一节专门讲这个。 3、如果是这样的话,确实领域层与数据库层会有耦合。领域事件其实放领域层也是可以的,放应用层主要是为了统一管理。如果领域事件放在实体内部,查找和运维起来就不是太方便,而且这个实体还需要对领域事件的实体进行操作。目录结构的设计主要是从边界、分层和便利性考虑的。
2019-11-1339 小明欧阳老师,看回复收获很多,我也想请教一个问题,比如一个查询商品详情接口,包含查询商品信息、店铺信息、促销信息,可能跨多个域,那么结合DDD分层设计,应该怎么做呢,谢谢
小明欧阳老师,看回复收获很多,我也想请教一个问题,比如一个查询商品详情接口,包含查询商品信息、店铺信息、促销信息,可能跨多个域,那么结合DDD分层设计,应该怎么做呢,谢谢作者回复: 在用DDD设计时,这种复杂的查询逻辑一般不放到领域模型的领域逻辑中,而是采用CQRS模式,也就是一种读写分离的设计模型,在CQRS模型中读业务模型和写业务模型(领域模型)是分离的。 第一种方案,如果读模型和写模型在同一个微服务中,这种复杂查询模型可以共享同一个数据库的不同聚合的数据库表,用传统的SQL查询就可以实现复杂的跨聚合查询。 第二种方案,你也可以将读模型独立为查询库和查询微服务,汇集多个源头数据后,重构多个微服务或者聚合的读数据模型,然后提供独立的查询服务。 具体选用哪种方案,需要结合你的技术和业务场景来设计。
2020-11-0336 刘小龙Repository,放在领域层,如果一个对象出现在领域,多个领域对其进行操作,会不会太多重复的操作数据库?【将包括核心业务逻辑和仓储代码的聚合包整体迁移,轻松实现微服务架构演进】这个是为了将各个领域的代码进行隔离,进行了竖向划分,达到目标。如果系统过大,将基础层划分出来,接口层划分出来,也就横向划分,是不是也行?
刘小龙Repository,放在领域层,如果一个对象出现在领域,多个领域对其进行操作,会不会太多重复的操作数据库?【将包括核心业务逻辑和仓储代码的聚合包整体迁移,轻松实现微服务架构演进】这个是为了将各个领域的代码进行隔离,进行了竖向划分,达到目标。如果系统过大,将基础层划分出来,接口层划分出来,也就横向划分,是不是也行?作者回复: 聚合在领域建模的时候是要坚持职责单一性原则的,一个聚合的功能在企业内应该是唯一的。而一个仓储只对应一个聚合,所以这个仓储应该不会共享给其它的领域模型,不会在基础层被其它的聚合复用的。
2020-04-055 Tony实体自身的业务逻辑放在实体里面,会不会让实体对象很庞大,假如实体里面的业务逻辑设计仓储层的调用会不会有点奇怪了?求解
Tony实体自身的业务逻辑放在实体里面,会不会让实体对象很庞大,假如实体里面的业务逻辑设计仓储层的调用会不会有点奇怪了?求解作者回复: 充血模型才是真正的面向对象设计方式。 在一个聚合中,除了聚合根和领域服务外,一般的实体不会调用仓储接口的。为了保证聚合内数据的一致性和符合聚合的业务规则,聚合新增或修改的数据通常都是通过聚合根或领域服务一次提交到持久层,不允许直接去修改某一个普通实体的持久化数据的。
2021-01-274 z业务相关的校验是放到应用层还是领域层呢?放在应用层的话应用层有了业务逻辑。放在领域层,面向web的和面向微服务间的调用校验规则不同又不够灵活难以实现。
z业务相关的校验是放到应用层还是领域层呢?放在应用层的话应用层有了业务逻辑。放在领域层,面向web的和面向微服务间的调用校验规则不同又不够灵活难以实现。作者回复: 一般来说是这样的,前端页面逻辑的数据校验在前端应用完成。应用服务中进行安全认证、权限校验、事务控制、领域事件发布或订阅等。业务规则的校验一般在领域层完成。
2020-05-194 燕羽阳在《实现领域驱动设计》这本书中,Demo(https://github.com/VaughnVernon/IDDD_Samples)。 会倾向于:在application中调用repository, 领域实体和领域服务是不应当调用repository的,这样领域层会保持独立。在实际写代码的过程中,发现这样代码写比较麻烦。 老师能在详细对比讲讲,对repository和第三方接口依赖的情况,在哪一层处理么?
燕羽阳在《实现领域驱动设计》这本书中,Demo(https://github.com/VaughnVernon/IDDD_Samples)。 会倾向于:在application中调用repository, 领域实体和领域服务是不应当调用repository的,这样领域层会保持独立。在实际写代码的过程中,发现这样代码写比较麻烦。 老师能在详细对比讲讲,对repository和第三方接口依赖的情况,在哪一层处理么?作者回复: 是的,我感觉对应复杂的聚合在领域服务中调用repository比较顺手。第三方接口我建议放在应用服务中处理,应用服务主要对服务进行组合和编排。
2020-01-034

