

06 | 进阶部署(二):非量化版DeepSeek分布式部署方案实战
邢云阳

你好,我是邢云阳。
前面两节课,我们完成了私有化部署的入门。我们学到了一种非常简单的易上手的方案,即利用网关 + 多个 Ollama 实现负载均衡的大模型集群的方案。这种方案的本质还是单卡单模型,但通过负载均衡技术,可以将一次对话任务,分配到多个模型来共同完成,算是一种提高性能的曲线救国路线。
但 Ollama 毕竟提供的是量化模型,如果想要体验原版效果还是要部署原版模型。不过,随着 LLM 模型越来越大,单 GPU 已经无法加载一个模型。以 DeepSeek-R1-Distill-Llama-70B 为例,模型权重大概 140 GB,但是单个 NVIDIA A100 只有 80GB 显存。如果想要在 A100 上部署 DeepSeek-R1-Distill-Llama-70B 模型,我们至少需要将模型切分后部署到 2 个 A100 机器上,每个 A100 卡加载一半的模型,这种方式称之为分布式推理。
下图整理了 DeepSeek 各模型版本推荐的配置:
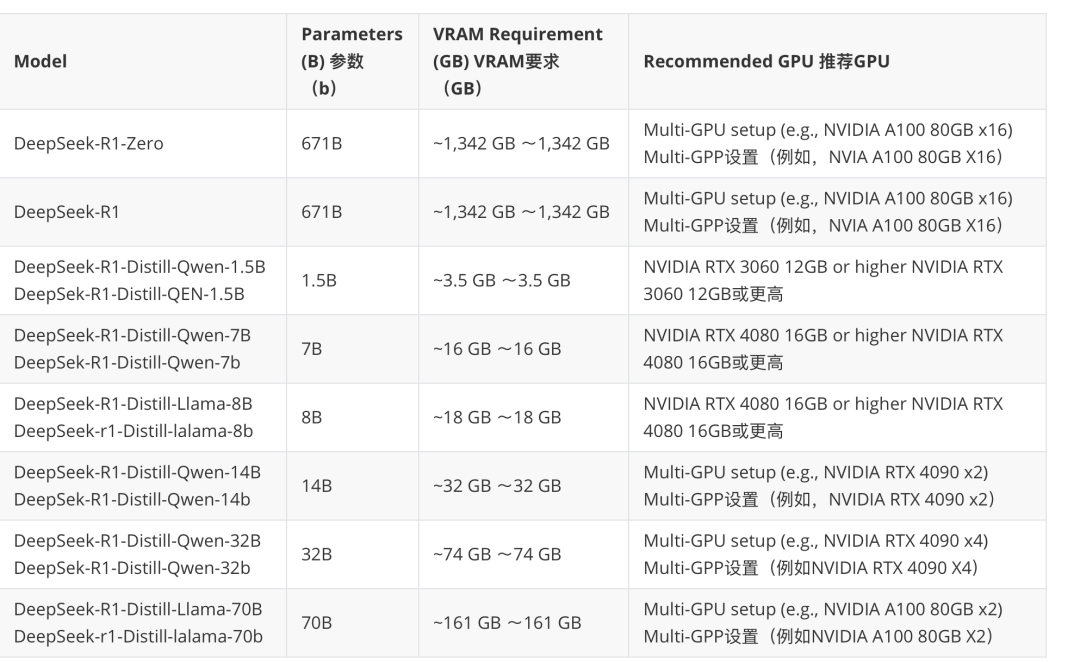
关于本地化运行,DeepSeek 官方提供了 7 种方式。

考虑到业界使用习惯和社区热度等因素,这节课,我们将会一起体验第 5 种运行方式——基于 vLLM 的模型部署方式,这也是云厂商使用非常多的一种方式,包括阿里、腾讯等公司都在使用。学习完 vLLM 框架后,等到第 8 节课,我们还会加上另一个分布式计算框架 Ray,组成 vLLM + Ray 的分布式推理方案。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. DeepSeek-R1-Distill-Llama-70B 模型的部署需要采用分布式推理,因为单个 NVIDIA A100 显存无法加载这么大的模型。 2. vLLM 是专为大型语言模型 (LLM) 的推理和部署而设计的库,通过引入创建的架构和算法,减少计算开销,提高吞吐量,实现推理过程的高效。 3. vLLM 的安装可以通过 pip 安装、从源码安装或使用 Docker 安装,其中推荐使用 Docker 安装,因为它可以避免环境适配问题。 4. 使用 vLLM 进行模型推理时,可以进行离线批量推理和在线推理,离线推理需要编写 Python 代码,而在线推理可以通过命令拉起大模型后,直接使用 OpenAI API 访问大模型。 5. vLLM 还支持 OpenAI Completions API,可以通过修改 base_url 和 model 来使用 vLLM 的 API server. 6. 分布式推理有不同的策略,包括单 GPU、单节点多 GPU(张量并行推理)、多节点单(多) GPU(张量并行加管道并行推理)的情况,需要根据模型大小和硬件情况选择合适的策略。 7. 在分布式推理中,需要考虑显存大小、GPU 卡数量、NVLink 技术、高速网络等因素,以及适用场景和效率优化。 8. 环境搭建、推理模式选择和分布式推理策略是部署大型模型时的关键知识点,需要根据具体情况进行合理选择和配置。 9. 在部署 DeepSeek-R1-671B 模型时,设置--tensor-parallel-size=16 可能会导致不同的现象,需要进行思考和讨论。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《DeepSeek 应用开发实战》,新⼈⾸单¥59
《DeepSeek 应用开发实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(3)
- 最新
- 精选
 小林子老师可以讲一下如何在华为昇腾910机器上部署吗2025-03-12归属地:贵州
小林子老师可以讲一下如何在华为昇腾910机器上部署吗2025-03-12归属地:贵州- 西钾钾思考题:当使用 2 台 8*A100 的服务器部署 DeepSeek-R1-671B 模型时,若设置 --tensor-parallel-size=16 会出现什么现象? 在没有指定 pipeline-parallel-size 时,是只能用到 1 台服务器吗?这种情况下,应该是不是显存不够,不能正常启动了。2025-03-12归属地:浙江
 willmyc张量并行设备仅限于同一台节点内,在未设置管道并行时,它不会将另一台服务器的GPU纳入张量并行队列。结果只能使用8张GPU,剩余8张GPU未被调度,导致无法充分利用所有的GPU资源。2025-03-12归属地:广东
willmyc张量并行设备仅限于同一台节点内,在未设置管道并行时,它不会将另一台服务器的GPU纳入张量并行队列。结果只能使用8张GPU,剩余8张GPU未被调度,导致无法充分利用所有的GPU资源。2025-03-12归属地:广东
收起评论