

第 16 章 解析器(2)
霍春阳(HcySunYang)
16.5 解析属性
上一节中介绍的 parseTag 解析函数会消费整个开始标签,这意味着该函数需要有能力处理开始标签中存在属性与指令,例如:
上面这段模板中的 div 标签存在一个 id 属性和一个 v-show 指令。为了处理属性和指令,我们需要在 parseTag 函数中增加 parseAttributes 解析函数,如下面的代码所示:
上面这段代码的关键点之一是,我们需要在消费标签的“开始部分”和无用的空白字符之后,再调用 parseAttribute 函数。举个例子,假设标签的内容如下:
标签的“开始部分”指的是字符串 <div,所以当消耗标签的“开始部分”以及无用空白字符后,剩下的内容为:
上面这段内容才是 parseAttributes 函数要处理的内容。由于该函数只用来解析属性和指令,因此它会不断地消费上面这段模板内容,直到遇到标签的“结束部分”为止。其中,结束部分指的是字符 > 或者字符串 />。据此我们可以给出 parseAttributes 函数的整体框架,如下面的代码所示:
实际上,parseAttributes 函数消费模板内容的过程,就是不断地解析属性名称、等于号、属性值的过程,如图 16-17 所示。
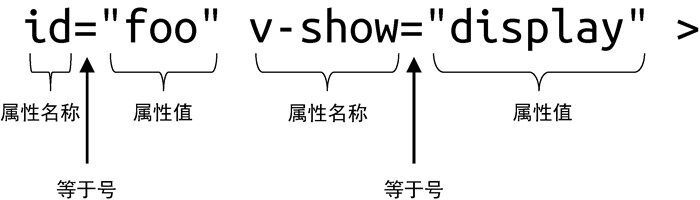
图 16-17 属性的格式
parseAttributes 函数会按照从左到右的顺序不断地消费字符串。以图 16-17 为例,该函数的解析过程如下。
首先,解析出第一个属性的名称 id,并消费字符串 'id'。此时剩余模板内容为:
在解析属性名称时,除了要消费属性名称之外,还要消费属性名称后面可能存在的空白字符。如下面这段模板中,属性名称和等于号之间存在空白字符:
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了解析器中解析属性和解析文本的过程。作者首先详细讲解了解析属性的过程,包括处理属性名称和属性值的正则表达式实现,并通过代码示例和图示清晰展示了解析属性的过程。接着,文章讨论了解析文本节点的过程,包括状态机的状态迁移过程和解析文本内容的具体实现。此外,还介绍了HTML实体的概念和解码命名字符引用的方法。整体来看,本文通过具体的技术细节和实现原理,为读者深入理解解析器的工作原理提供了有力的帮助。文章内容涵盖了解析器的核心技术,对于想深入了解解析器实现原理的读者来说,是一篇值得深入阅读的技术文章。文章还介绍了HTML实体的概念和解码命名字符引用的方法,以及解析器对文本节点中的HTML实体进行解码的原因和实现逻辑。通过对HTML实体解码的状态机状态迁移流程的讲解,读者可以深入了解解析器的解码逻辑。文章还通过具体的例子和图示,生动地展示了解析器对文本节点中HTML实体的解码过程,帮助读者更好地理解解析器的工作原理。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Vue.js 设计与实现》
《Vue.js 设计与实现》
立即购买

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论