
类人任务(human-like task)的模型
[美] 斯蒂芬 • 沃尔弗拉姆(Stephen Wolfram)
该思维导图由 AI 生成,仅供参考
上文提到的例子涉及为数值数据建立模型,这些数据基本上来自简单的物理学—几个世纪以来,我们已经知道可以用一些“简单的数学工具”为其建模。但是对于 ChatGPT,我们需要为人脑产生的人类语言文本建立模型。而对于这样的东西,我们(至少目前)还没有“简单的数学”可用。那么它的模型可能是什么样的呢?
在讨论语言之前,让我们谈谈另一个类人任务:图像识别。一个简单的例子是包含数字的图像(这是机器学习中的一个经典例子)。

我们可以做的一件事是获取每个数字的大量样本图像。

要确定输入的图像是否对应于特定的数字,可以逐像素地将其与已有的样本进行比较。但是作为人类,我们似乎肯定做得更好:因为即使数字是手写的,有各种涂抹和扭曲,我们也仍然能够识别它们。
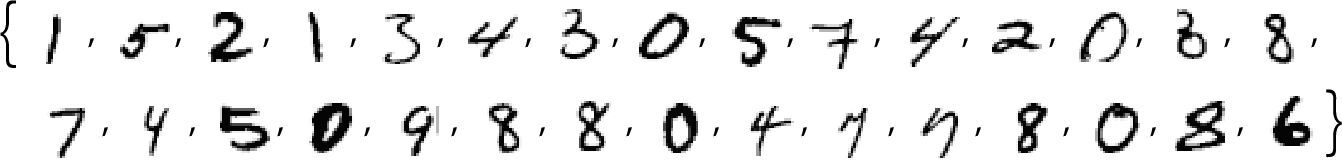
当为上一节中的数值数据建立模型时,我们能够在取得给定的数值 x 之后,针对特定的 a 和 b 来计算出
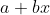
。那么,如果我们将图像中每个像素的灰度值视为变量
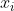
,是否存在涉及所有这些变量的某个函数,能(在运算后)告诉我们图像中是什么数字?事实证明,构建这样的函数是可能的。不过难度也在意料之中,一个典型的例子可能涉及大约 50 万次数学运算。
最终的结果是,如果我们将一个图像的像素值集合输入这个函数,那么输出将是一个数,明确指出该图像中是什么数字。稍后,我们将讨论如何构建这样的函数,并了解神经网络的思想。但现在,让我们先将这个函数视为黑盒,输入手写数字的图像(作为像素值的数组),然后得到它们所对应的数字。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文讨论了类人任务的模型,特别是在图像识别和语言生成方面的模型。文章指出,对于简单的数值数据,我们可以使用简单的数学工具来建立模型,但对于人类语言文本和图像识别,我们需要更复杂的模型。在图像识别方面,文章提到了构建函数来识别手写数字的例子,并探讨了模糊图像的识别问题。对于语言生成模型,文章提到了神经网络的思想,并强调了构建良好模型的重要性。最后,文章指出了构建这些模型的挑战,因为需要考虑人类视觉感知的复杂性。整体而言,本文深入浅出地介绍了类人任务模型的复杂性和挑战,为读者提供了对该主题的深入了解。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《这就是 ChatGPT》
《这就是 ChatGPT》
立即购买

登录 后留言
全部留言(1)
- 最新
- 精选

 Spicks and Specks说实话,我没明白大模型是怎么诞生的,为什么它可以产生推理逻辑2024-01-30归属地:上海
Spicks and Specks说实话,我没明白大模型是怎么诞生的,为什么它可以产生推理逻辑2024-01-30归属地:上海
收起评论