

21|部署一个鲜花网络电商的人脉工具(下)

项目步骤复习
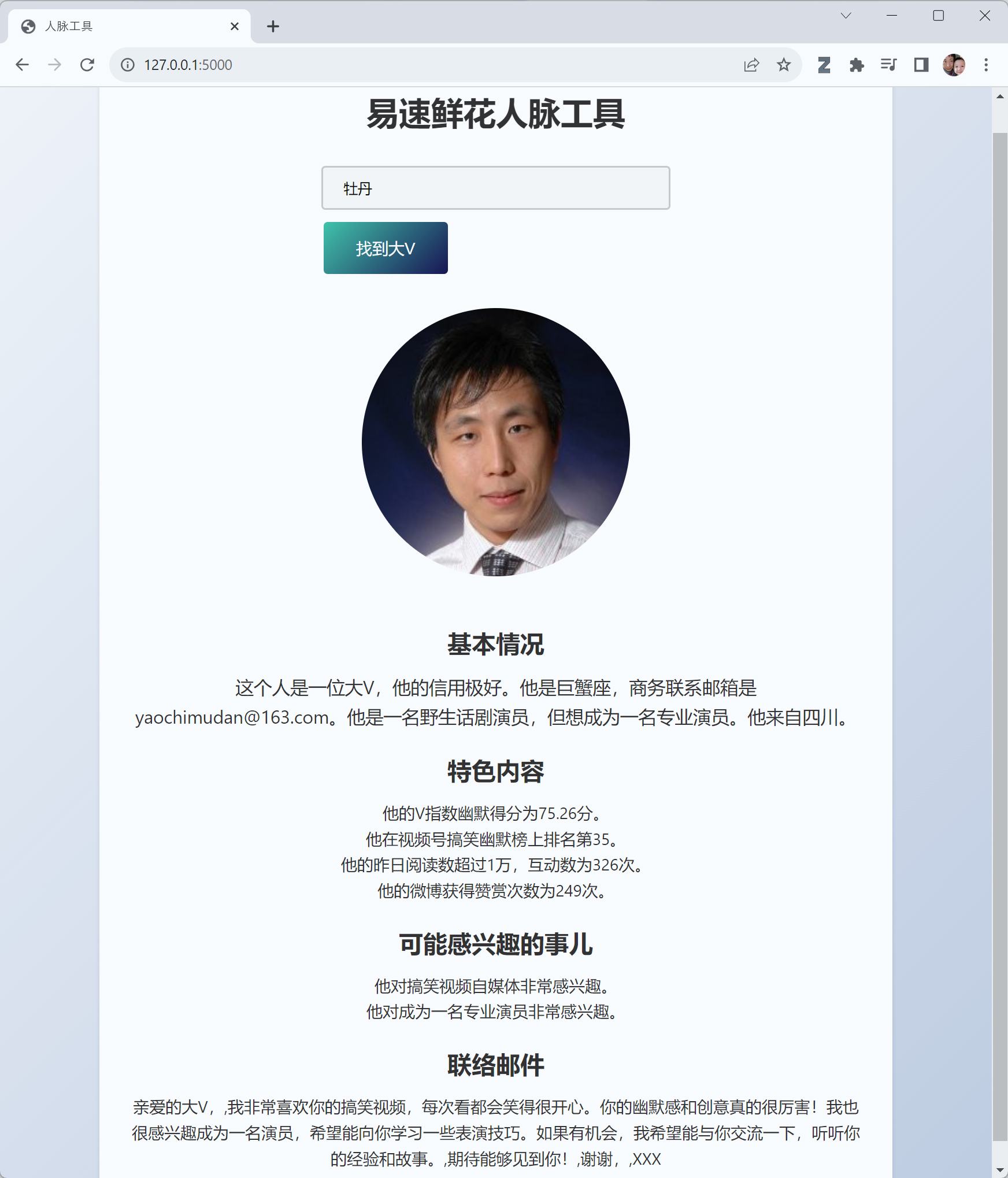
第三步:生成介绍文章
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何利用LangChain实现一个鲜花网络电商的人脉工具。通过LangChain搜索工具找到微博大V、爬取大V信息、生成介绍文章、输出解析以及部署人脉工具等五个具体步骤。重点介绍了通过LangChain调用LLM生成大V介绍文章,并利用输出解析器让LLM生成有良好结构的JSON文档。同时,还展示了创建HTML文件、CSS文件以及重构findbigV.py和创建app.py的具体操作。最后,作者提到了项目的完成和总结,以及对读者提出了思考题,鼓励读者进一步探索和优化这个人脉工具。整体来看,本文突出了利用LangChain实现自动化的技术特点,为读者提供了一种新颖的技术实践思路。
《LangChain 实战课》,新⼈⾸单¥59

全部留言(4)
- 最新
- 精选
 鲸鱼老师您好,我觉得有些代码可以优化下。app.py中将find_bigV返回的字符串反序列化为json,然后又将其转换为字典,我这边有时会遇到llm返回的json前面带了一句话,导致json反序列化失败;其实通过前面定义的输出解析器可以直接拿到最终的dict,而且解析器内部是通过正则匹配json也避免了额外语句导致的解析失败 result_dict = letter_parser.parse(response).to_dict()
鲸鱼老师您好,我觉得有些代码可以优化下。app.py中将find_bigV返回的字符串反序列化为json,然后又将其转换为字典,我这边有时会遇到llm返回的json前面带了一句话,导致json反序列化失败;其实通过前面定义的输出解析器可以直接拿到最终的dict,而且解析器内部是通过正则匹配json也避免了额外语句导致的解析失败 result_dict = letter_parser.parse(response).to_dict()作者回复: 好的好的,肯定有很多代码细节值得优化。这个点就很好。我制作这个东西的时候粗糙了一些,欢迎同学们进行大刀阔斧的探讨。
2023-11-20归属地:北京1 蝈蝈老师您好,我想请教一个问题,如何在向量库检索之后得到答案的出处。有个场景是这样的,我有三篇文章加载到了向量库,接下来我开始提问,我想在返回的答案时,带上这个答案出自哪片文章,这个需求的实现思路可以简单说一下吗?
蝈蝈老师您好,我想请教一个问题,如何在向量库检索之后得到答案的出处。有个场景是这样的,我有三篇文章加载到了向量库,接下来我开始提问,我想在返回的答案时,带上这个答案出自哪片文章,这个需求的实现思路可以简单说一下吗?作者回复: 同学你好,有很多种方式。这里我给你一个RetrievalQAWithSourcesChain,可能是比较简单的方法。下面的Sample代码你跟着这个框架可以实现一下。 from langchain.chains import RetrievalQAWithSourcesChain from langchain.vectorstores import FAISS from langchain.embeddings import OpenAIEmbeddings # Load documents into FAISS index doc_store = FAISS.from_documents(documents, OpenAIEmbeddings()) # Add metadata like title, url, etc to documents doc_store.update_document_metadata(0, {"title": "Document 1", "url": "http://example.com/doc1"}) # Initialize chain qa_chain = RetrievalQAWithSourcesChain( vectorstore=doc_store, retriever=doc_store.get_dense_retriever(), qa_model=QAModel() ) # Get answer and sources result = qa_chain(question, return_only_outputs=True) print(result["answer"]) print(result["sources"])
2023-10-26归属地:湖北1 招谁惹谁请问老师,最后如果流式输出,怎么对sse请求做压测来评估性能呢?
招谁惹谁请问老师,最后如果流式输出,怎么对sse请求做压测来评估性能呢?作者回复: 进行Server-Sent Events (SSE)请求的压力测试这块我不大熟,希望有经验的同学给讨论讨论。我回答的话我只能问ChatGPT。。。
2023-11-18归属地:浙江 打奥特曼的小怪兽老师您好,我这边是第一次接触 LangChain 和LLM。在运行这个Demo的时候,不能很稳定的获得GTP的输出。 有时候会获得 letter_parser.get_format_instructions() 的内容。 {"properties": {"summary": {"description": "大V个人简介", "title": "Summary", "type": "string"}, "facts": {"description": "大V的特点", "items": {"type": "string"}, "title": "Facts", "type": "array"}, "interest": {"description": "这个大V可能感兴趣的事情", "items": {"type": "string"}, "title": "Interest", "type": "array"}, "letter": {"description": "一篇联系这个大V的邮件", "items": {"type": "string"}, "title": "Letter", "type": "array"}}, "required": ["summary", "facts", "interest", "letter"]}。 想请教下 怎么添加调试代码,感谢!
打奥特曼的小怪兽老师您好,我这边是第一次接触 LangChain 和LLM。在运行这个Demo的时候,不能很稳定的获得GTP的输出。 有时候会获得 letter_parser.get_format_instructions() 的内容。 {"properties": {"summary": {"description": "大V个人简介", "title": "Summary", "type": "string"}, "facts": {"description": "大V的特点", "items": {"type": "string"}, "title": "Facts", "type": "array"}, "interest": {"description": "这个大V可能感兴趣的事情", "items": {"type": "string"}, "title": "Interest", "type": "array"}, "letter": {"description": "一篇联系这个大V的邮件", "items": {"type": "string"}, "title": "Letter", "type": "array"}}, "required": ["summary", "facts", "interest", "letter"]}。 想请教下 怎么添加调试代码,感谢!作者回复: 同学你好,想要得到稳定的输出,每一次调用LLM时(或者链和Agent)所有的Temperature参数都要设置为0。
2023-11-01归属地:上海3