

06|调用模型:使用OpenAI API还是微调开源Llama2/ChatGLM?

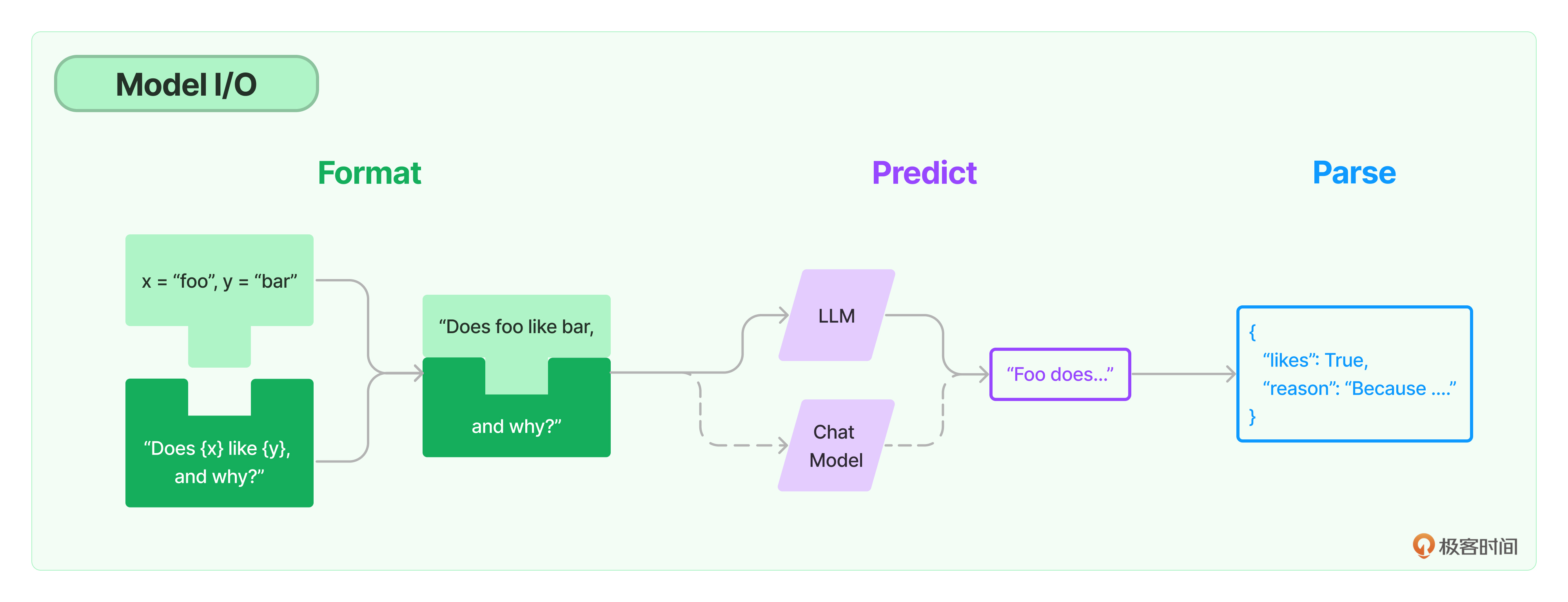
大语言模型发展史
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了大型语言模型的使用方法和技术特点,为读者提供了丰富的实践指导。文章首先回顾了大型语言模型的发展历程,包括Transformer架构的提出和BERT模型的影响。接着讨论了预训练+微调的模式,强调了预训练模型迁移语义信息的便利性和微调过程的高效性。文章详细介绍了如何通过HuggingFace库调用Llama2模型,包括注册并安装HuggingFace、申请使用Meta的Llama2模型以及通过HuggingFace调用Llama2模型的具体步骤。另外,还介绍了通过HuggingFace Hub和HuggingFace Pipeline两种方式集成模型的方法。最后,文章讨论了如何通过LangChain调用自定义语言模型,包括创建LLM的衍生类和下载模型的过程。文章还提到了Llama2模型的性能表现和推理速度,以及对PyTorch、HuggingFace和LangChain等工具的推荐。整体而言,本文内容丰富,涵盖了大型语言模型的多个方面,对于想要深入学习大模型的读者具有重要参考价值。
《LangChain 实战课》,新⼈⾸单¥59

全部留言(27)
- 最新
- 精选
 远游老师,macos安装pip install llama-cpp-python报错: ^ /private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/ggml.c:2243:11: note: expanded from macro 'GGML_F32x4_REDUCE' res = _mm_cvtss_f32(_mm_hadd_ps(t0, t0)); \ ~ ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 12 warnings generated. [10/13] /Library/Developer/CommandLineTools/usr/bin/c++ -DACCELERATE_LAPACK_ILP64 -DACCELERATE_NEW_LAPACK -DGGML_USE_ACCELERATE -DGGML_USE_K_QUANTS -DGGML_USE_METAL -DLLAMA_BUILD -DLLAMA_SHARED -D_DARWIN_C_SOURCE -D_XOPEN_SOURCE=600 -Dllama_EXPORTS -I/private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/. -O3 -DNDEBUG -std=gnu++11 -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -fPIC -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wunreachable-code-break -Wunreachable-code-return -Wmissing-declarations -Wmissing-noreturn -Wmissing-prototypes -Wextra-semi -MD -MT vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o -MF vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o.d -o vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o -c /private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/llama.cpp ninja: build stopped: subcommand failed. *** CMake build failed [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for llama-cpp-python Failed to build llama-cpp-python ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects
远游老师,macos安装pip install llama-cpp-python报错: ^ /private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/ggml.c:2243:11: note: expanded from macro 'GGML_F32x4_REDUCE' res = _mm_cvtss_f32(_mm_hadd_ps(t0, t0)); \ ~ ^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 12 warnings generated. [10/13] /Library/Developer/CommandLineTools/usr/bin/c++ -DACCELERATE_LAPACK_ILP64 -DACCELERATE_NEW_LAPACK -DGGML_USE_ACCELERATE -DGGML_USE_K_QUANTS -DGGML_USE_METAL -DLLAMA_BUILD -DLLAMA_SHARED -D_DARWIN_C_SOURCE -D_XOPEN_SOURCE=600 -Dllama_EXPORTS -I/private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/. -O3 -DNDEBUG -std=gnu++11 -isysroot /Library/Developer/CommandLineTools/SDKs/MacOSX10.15.sdk -fPIC -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wunreachable-code-break -Wunreachable-code-return -Wmissing-declarations -Wmissing-noreturn -Wmissing-prototypes -Wextra-semi -MD -MT vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o -MF vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o.d -o vendor/llama.cpp/CMakeFiles/llama.dir/llama.cpp.o -c /private/var/folders/x_/l6wthj_d7mb_gzcx3wvkmcvc0000gn/T/pip-install-ms76ov67/llama-cpp-python_9ce52d9b45d04a73950f2448a45590a0/vendor/llama.cpp/llama.cpp ninja: build stopped: subcommand failed. *** CMake build failed [end of output] note: This error originates from a subprocess, and is likely not a problem with pip. ERROR: Failed building wheel for llama-cpp-python Failed to build llama-cpp-python ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects作者回复: 使用 virtualenv 或 venv 创建一个新的虚拟环境吧,然后在这个环境中尝试安装 llama-cpp-python。这或许可以避免因为系统级的 Python 包的冲突而导致的问题。
2023-10-26归属地:北京2
 nick老师,有个疑问,原来使用像百度AI、腾讯AI做垂直领域的多轮对话,往往需要维护语料意图啥的,那有了大模型后,这些工作还需要做么,如果要那怎么做?跟传统维护语料意图有什么区别。谢谢
nick老师,有个疑问,原来使用像百度AI、腾讯AI做垂直领域的多轮对话,往往需要维护语料意图啥的,那有了大模型后,这些工作还需要做么,如果要那怎么做?跟传统维护语料意图有什么区别。谢谢作者回复: 好问题啊同学。当我们谈论大模型,特别是像GPT系列这样的大语言模型时,这确实改变了多轮对话的构建方式。但这并不意味着传统的意图分类和槽填充等技术就完全没有用处了。下面是一些考量哈(下面的部分回答来自于ChatGPT,但经过了作者的审定和补充🤩): 1. 减少手工标注需求:大模型如GPT能理解并生成自然语言,因此,对于很多常见的对话场景,你不再需要像传统方法那样进行大量的意图分类和槽填充标注。模型具有一定的通用知识,可以帮你做意图的分类哈。 2. 微调和特定任务训练:即使有了大模型,你仍可能需要进行微调,特别是针对特定的垂直领域或特定的业务场景。这通常需要一个相对较小但高质量的标注数据集。 3. 结合传统和新方法:大模型和传统的NLU(自然语言理解)方法可以结合使用。例如,你可以首先使用意图分类器判断用户的主要意图,然后将这个意图和用户的原始查询一起传递给大模型,让其生成更具体的回复。 4. 模型可解释性:传统的方法,如意图分类和槽填充,通常更具解释性。你知道模型为什么做出某个决策,因为它基于明确的意图和实体。而大模型的决策过程可能更加“黑箱”。 5. 成本效率和资源需求:大模型通常需要更多的计算资源。而且最好的大模型入GPT4是要付费的呀。在某些实时或资源受限的环境中,使用轻量级的传统方法可能更为合适。 6. 错误和偏见:大模型可能会犯一些出乎意料的错误,或者可能继承了预训练数据中的偏见。使用传统方法,你对数据和模型的控制更为明确。 结合大模型的能力和传统的意图分类和槽填充方法可能是一个更好的策略。根据具体的业务需求和场景来决定使用哪种方法,要结合两者的优点。
2023-09-21归属地:福建2- Geek_cb5e16老师 要使用HuggingFace 和 Pipeline HuggingFaceHUB 有什么区别 还是不太明白
作者回复: 差不多。这是搜到的内容,基本上解释的清晰。Pipeline更简易操作一些。 HuggingFace和使用Pipeline HuggingFaceHUB存在一些差异。这些差异主要体现在使用方式和应用场景上。 HuggingFace Pipeline: HuggingFace的Pipeline是一个简化的接口,用于从HuggingFace Hub加载和使用各种模型。它提供了一个通用的、易于使用的方法,用于各种任务,如文本分类、语音识别、图像分割等。即使您对特定的模型或任务不熟悉,也可以使用Pipeline轻松实现推理任务。Pipeline抽象了与特定任务相关的所有其他可用Pipeline,可以处理多种类型的输入,并自动加载默认模型和预处理类。 HuggingFace Hub: HuggingFace Hub是一个平台,提供超过350,000个模型、75,000个数据集和150,000个演示应用程序(Spaces)。在Hub上,您可以找到、下载和使用各种任务的预训练模型。它是一个为机器学习社区提供协作和构建ML应用程序的开源平台。您可以使用Hub上的模型,但需要自己处理模型加载和推理逻辑,这与Pipeline提供的简化方法略有不同。
2023-11-28归属地:上海1  Monin老师 用LangChain调用自定义语言模型时,在初始化具体模型时如何确定相对应的具体类名。比如目前性能最好的XwinLM模型,在HuggingFace上下载合适的模型后 如何找到对应的初始化类?
Monin老师 用LangChain调用自定义语言模型时,在初始化具体模型时如何确定相对应的具体类名。比如目前性能最好的XwinLM模型,在HuggingFace上下载合适的模型后 如何找到对应的初始化类?作者回复: 同学可以看这个Link:https://python.langchain.com/docs/integrations/llms/ 给出了所有LangChain支持的模型的初始化示例代码。比如说https://python.langchain.com/docs/integrations/llms/chatglm from langchain.llms import ChatGLM from langchain.prompts import PromptTemplate from langchain.chains import LLMChain # import os template = """{question}""" prompt = PromptTemplate(template=template, input_variables=["question"]) # default endpoint_url for a local deployed ChatGLM api server endpoint_url = "http://127.0.0.1:8000" # direct access endpoint in a proxied environment # os.environ['NO_PROXY'] = '127.0.0.1' llm = ChatGLM( endpoint_url=endpoint_url, max_token=80000, history=[["我将从美国到中国来旅游,出行前希望了解中国的城市", "欢迎问我任何问题。"]], top_p=0.9, model_kwargs={"sample_model_args": False}, ) 如果找不到你要的模型,那么,你只能通过https://python.langchain.com/docs/integrations/llms/huggingface_hub或者https://python.langchain.com/docs/integrations/llms/huggingface_pipelines 来导入所需要的模型。
2023-10-11归属地:上海21- 陈东GITHUB上的类似WeChat chat类项目https://github.com/zhayujie/chatgpt-on-wechat,如何结合LangChain和huggingFace结合修改?找不到方向?老师可以加餐讲一讲吗?谢谢。
作者回复: 嗯,这个项目看起来是把ChatGPT整合到微信中。让我先研究一下这个项目先。有了解的同学也可以说一说。
2023-09-29归属地:中国台湾1  无限可能MabBook M2上面的DEMO都运行不了,提示`AssertionError: Torch not compiled with CUDA enabled`,不知道是不是使用的方式不正确。
无限可能MabBook M2上面的DEMO都运行不了,提示`AssertionError: Torch not compiled with CUDA enabled`,不知道是不是使用的方式不正确。作者回复: 这个错误通常是Torch和你的CUDA Version不兼容。
2023-09-19归属地:美国41 Alan黄佳老师好,有没有可能弄一个可运行的镜像环境。每次运行实例程序都有各种环境问题,包括python库的版本兼容等。
Alan黄佳老师好,有没有可能弄一个可运行的镜像环境。每次运行实例程序都有各种环境问题,包括python库的版本兼容等。作者回复: 嗯嗯,是啊,LangChain发展非常快。我目前在Github上面贴了一个requirements.txt文件。但是,估计跟着这个文件走,也会有Warning或者Error。 下次新的课程,我会弄一个镜像环境,Docker之类的,方便同学复现。 这次课程只好麻烦同学自己研究,更新。这也是学习的一部分。而且,LangChain的版本变化实在太快,看看新的版本也有好处。
2024-01-03归属地:广东 Charliellama-cpp-python v0.2.22 加载 llama-2-7b-chat.ggmlv3.q4_K_S.bin 时报错,错误信息如下: gguf_init_from_file: invalid magic characters 'tjgg' error loading model: llama_model_loader: failed to load model from /Users/xxx/PycharmProjects/hello_langchain/OfflineModel/llama-2-7b-chat.ggmlv3.q4_K_S.bin 准备尝试用gguf model (llama-2-7b-chat.Q4_K_S.gguf)去加载。 https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/tree/main
Charliellama-cpp-python v0.2.22 加载 llama-2-7b-chat.ggmlv3.q4_K_S.bin 时报错,错误信息如下: gguf_init_from_file: invalid magic characters 'tjgg' error loading model: llama_model_loader: failed to load model from /Users/xxx/PycharmProjects/hello_langchain/OfflineModel/llama-2-7b-chat.ggmlv3.q4_K_S.bin 准备尝试用gguf model (llama-2-7b-chat.Q4_K_S.gguf)去加载。 https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/tree/main作者回复: "gguf_init_from_file: invalid magic characters 'tjgg'" 通常表明您尝试加载的模型文件格式或内容不正确,版本不兼容之类的。换了模型之后通了吗?
2023-12-13归属地:新加坡3 高浩宇Llama 2和智谱AI的ChatGLM3-6b哪个适合用来做基础模型
高浩宇Llama 2和智谱AI的ChatGLM3-6b哪个适合用来做基础模型作者回复: 英文会是Llama2,中文可以选择智谱的模型。
2023-11-29归属地:江苏- Geek_cb5e16大规模使用语言模型的时候 适合使用开源模型 量大的时候时候私有化模型会减少一部分成本
作者回复: 对啊。但是开源模型需要部署再本地GPU上面也是一些成本。
2023-11-28归属地:上海