

07|输出解析:用OutputParser生成鲜花推荐列表

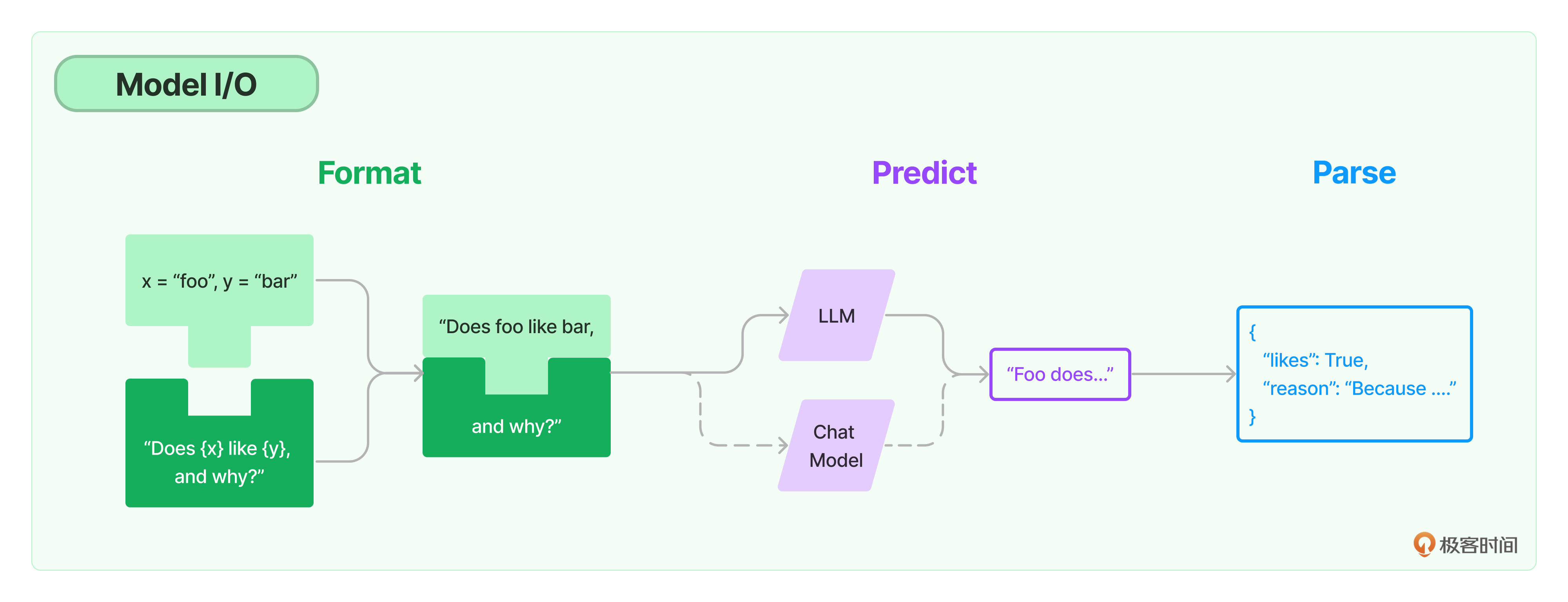
LangChain 中的输出解析器
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

LangChain实战课中的文章“输出解析:用OutputParser生成鲜花推荐列表”深入探讨了LangChain平台中输出解析器的作用和种类,重点介绍了Pydantic(JSON)解析器的实际应用。文章首先解释了输出解析器的基本原理和核心方法,然后详细介绍了LangChain中的各种输出解析器,包括列表解析器、日期时间解析器、枚举解析器、结构化输出解析器等。重点突出了Pydantic(JSON)解析器的实战应用,通过创建模型实例、定义输出数据格式和创建输出解析器的步骤,展示了如何使用Pydantic库来重构鲜花文案生成程序。文章强调了Pydantic库在数据验证、数据转换、易于使用和JSON支持等方面的特点,以及如何利用PydanticOutputParser来解析模型的输出,确保其符合指定的数据格式。整体而言,本文通过实际案例向读者展示了LangChain中输出解析器的应用,特别突出了Pydantic(JSON)解析器的重要性和实际操作。文章内容涵盖了输出解析器的核心概念和实际操作,为读者提供了深入了解LangChain平台技术特点的机会。文章还介绍了自动修复解析器(OutputFixingParser)和重试解析器(RetryWithErrorOutputParser)的实际应用,展示了如何利用这些解析器来处理格式错误和缺失内容,以及利用大模型的推理能力找回相关信息。这些技术特点使得LangChain平台在输出解析和数据处理方面具有更强的灵活性和鲁棒性。文章还提出了思考题,引导读者深入思考输出解析器的应用和原理,为读者提供了进一步学习的延伸阅读建议。
《LangChain 实战课》,新⼈⾸单¥59

全部留言(9)
- 最新
- 精选
 在路上从源码上看,OutputFixingParser和RetryWithErrorOutputParser的本质是相同的,都是当PydanticOutputParser.parse(input)解析失败,通过语言模型分析抛出的异常,修正input。 不同之处在于,OutputFixingParser利用input schema、input、exception来修正input,RetryWithErrorOutputParser除了利用input schema、input、exception,还利用一个额外的prompt来修正input,有了额外的prompt,自然就能够既修正input格式,又补全input内容。
在路上从源码上看,OutputFixingParser和RetryWithErrorOutputParser的本质是相同的,都是当PydanticOutputParser.parse(input)解析失败,通过语言模型分析抛出的异常,修正input。 不同之处在于,OutputFixingParser利用input schema、input、exception来修正input,RetryWithErrorOutputParser除了利用input schema、input、exception,还利用一个额外的prompt来修正input,有了额外的prompt,自然就能够既修正input格式,又补全input内容。作者回复: 总结的清晰透彻 🧑🎓
2023-09-20归属地:广东11 高源老师有个问题请教,例如目前大模型比较多,我的理解如果满足企业内部自己使用,是需要对大模型微调吧才能完全满足定制,例如输出企业自己相关数据,文档,代码等,而不是简单把提示写好弄个差不多开源大模型上去。我的理解是需要微调吧,针对自己企业数据进行训练对模型,但这块听老师课我理解需要对模型层次熟悉才能下手进行微调吧,我自己理解目前从效果上还是gpt其它模型还是比较弱,百度说他的2.0已经超过gpt3.5,比gpt4差点,我觉得没那么快吧,另外训练模型机器硬件人员等各种因素叠加,不是说都能做好了吧,企业自己落地自己模型这块现实吗,自己做需要那些条件,例如人员要求等,谢谢
高源老师有个问题请教,例如目前大模型比较多,我的理解如果满足企业内部自己使用,是需要对大模型微调吧才能完全满足定制,例如输出企业自己相关数据,文档,代码等,而不是简单把提示写好弄个差不多开源大模型上去。我的理解是需要微调吧,针对自己企业数据进行训练对模型,但这块听老师课我理解需要对模型层次熟悉才能下手进行微调吧,我自己理解目前从效果上还是gpt其它模型还是比较弱,百度说他的2.0已经超过gpt3.5,比gpt4差点,我觉得没那么快吧,另外训练模型机器硬件人员等各种因素叠加,不是说都能做好了吧,企业自己落地自己模型这块现实吗,自己做需要那些条件,例如人员要求等,谢谢作者回复: 你的问题涉及到大型预训练模型在企业应用中的微调、性能比较以及企业落地实现的可行性和条件。我给出比较官方的回答。 微调大模型 对于企业来说,确实,将一个通用的大型语言模型直接用于特定业务场景通常是不够的,因为通用模型在预训练时使用的是跨领域的数据集,这可能无法充分覆盖企业特定的术语、风格或任务。因此,微调是一种常用的技术,可以提高模型在特定应用上的表现。 微调过程通常包括以下几个步骤: 数据准备:收集和整理企业相关的数据集,如内部文档、日志、对话记录等。 预处理:对数据进行清洗和格式化,使其适合模型输入。 微调:在企业数据上继续训练模型,以适应特定任务。 评估:测试微调后模型的性能,确保其满足业务需求。 部署:将微调后的模型部署到生产环境中。 对于模型的层次结构和架构熟悉程度,实际上现在有很多工具和库已经简化了这一过程,使得即使不是深度学习专家也能进行基本的微调工作。当然,更深入的定制化和优化仍然需要对模型的工作原理和机器学习的相关知识有较深入的理解。 大模型性能比较 关于模型性能的比较,如百度的文心一言,科大的星火认知,与OpenAI的GPT-3或GPT-4的比较,不好比较。需要根据具体任务和独立评估来考量。不同的模型可能在不同的任务上表现出不同的性能水平,而且性能也受数据集、评估指标、测试条件等因素的影响。因此,没有绝对的“最好”模型,只有最适合特定任务和条件的模型。 企业落地自建模型的现实性 对于企业来说,自己从头开始训练一个大型语言模型通常是不现实的,原因有以下几个方面: 成本:训练大型模型需要大量的计算资源,这意味着高昂的硬件和电力成本。 数据:需要大规模的、高质量的训练数据。 专业知识:需要有经验的数据科学家和机器学习工程师。 时间:训练可能需要数周甚至数月的时间。 维护:模型训练后还需要持续的维护和更新。 因此,大多数企业会选择使用现成的预训练模型,并在此基础上进行微调来满足自己的需要,而不是从零开始训练。 企业自建模型需要的条件 如果企业确实想要自建模型,那么需要: 团队:由数据科学家、机器学习工程师和领域专家组成的团队。 数据:访问或创建足够的训练数据。 计算资源:高性能的计算硬件或云计算资源。 时间和耐心:模型开发是一个长期的过程。 策略:清晰的业务理解和战略,以确定模型的具体用途和ROI。 结合外部服务提供商的专业知识和资源可能是一个更实际的途径。通过合作,企业可以在不承担全部开发负担的情况下,有效利用大型语言模型。 希望你有什么疑问可以继续探讨。
2023-11-01归属地:吉林5 棟老师,请教一个问题, fix_parser或retry_parser中,如果错误的输出是json格式会报如下错误: action_input Field required [type=missing, input_value={'action': 'search'}, input_type=dict] For further information visit https://errors.pydantic.dev/2.3/v/missing 我是将错误bad_response = '{"action": "search"}' --> 更改为bad_response = "{'action': 'search'}"才能正常调用模型,这个要怎么修复。 知道的朋友也请指点,感谢!
棟老师,请教一个问题, fix_parser或retry_parser中,如果错误的输出是json格式会报如下错误: action_input Field required [type=missing, input_value={'action': 'search'}, input_type=dict] For further information visit https://errors.pydantic.dev/2.3/v/missing 我是将错误bad_response = '{"action": "search"}' --> 更改为bad_response = "{'action': 'search'}"才能正常调用模型,这个要怎么修复。 知道的朋友也请指点,感谢!作者回复: 这里示例的意思是action_input是必须的字段,但是我们并没有pass到模型里面去。要确保你在传递数据之前将JSON字符串解析为Python字典。可以使用 json.loads() 方法来实现这一点: import json bad_response = '{"action": "search"}' parsed_response = json.loads(bad_response) 不知道我这里是否理解了同学的具体问题。
2023-10-07归属地:广东21 风隼[咖啡]# parsed_output_dict = parsed_output.dict() # 将Pydantic格式转化位字典 # Pydantic 格式转化为字典,Pydantic V2dict 方法已经被废弃,推荐使用 model_dump 方法来代替 parsed_output_dict = parsed_output.model_dump()
风隼[咖啡]# parsed_output_dict = parsed_output.dict() # 将Pydantic格式转化位字典 # Pydantic 格式转化为字典,Pydantic V2dict 方法已经被废弃,推荐使用 model_dump 方法来代替 parsed_output_dict = parsed_output.model_dump()作者回复: 好嘞,谢谢您的分享!!
2023-12-15归属地:上海- rick009老师您好,有个问题请教一下,我想要从给定的一段文本中抽离一些FAQ,然后想返回JSON数组的格式,以下是prompt: template = """你是一名知识库管理员,需将以下内容拆分成 {nums} 个问答对,确保准确无误且只从文献中获取,不得扩散。你的算法或流程应该能够准确抽取关键信息,并生成准确的问答对,以充分利用文献。 {doc_content} {format_instructions} """ 想要返回的格式为 The output should be formatted as a JSON instance that conforms to the JSON schema below.\n\nAs an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}\nthe object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.\n\nHere is the output schema:\n```\n{"$defs": {"QA": {"properties": {"Q": {"description": "\\u95ee\\u9898", "title": "Q", "type": "string"}, "A": {"description": "\\u7b54\\u6848", "title": "A", "type": "string"}}, "required": ["Q", "A"], "title": "QA", "type": "object"}}, "items": {"$ref": "#/$defs/QA"}}\n``` class QA(BaseModel): Q: str = Field(description="问题") A: str = Field(description="答案") class QAList(RootModel): root: List[QA] = Field(description="FAQ问答对列表") 但是返回的格式总是不停的在变,都无法返回希望的数据结构
作者回复: 可能这个格式过于复杂了,需要简化任务。另外,用最新的gpt-4-1106-preview模型试试?
2023-12-06归属地:北京  鲸鱼我遇到一个问题,目前的langchain必须使用v1版本的pydantic,如果使用了v2版本抛出的异常类型不对,会导致PydanticOutputParser无法捕获正常的ValidationError异常,从而不会去请求openAI修复response。 PydanticOutputParser的具体捕获代码是这里 class PydanticOutputParser(BaseOutputParser[T]): """Parse an output using a pydantic model.""" pydantic_object: Type[T] """The pydantic model to parse.""" def parse(self, text: str) -> T: try: # Greedy search for 1st json candidate. match = re.search( r"\{.*\}", text.strip(), re.MULTILINE | re.IGNORECASE | re.DOTALL ) json_str = "" if match: json_str = match.group() json_object = json.loads(json_str, strict=False) return self.pydantic_object.parse_obj(json_object) except (json.JSONDecodeError, ValidationError) as e: # 这里只能捕获v1版本的ValidationError name = self.pydantic_object.__name__ msg = f"Failed to parse {name} from completion {text}. Got: {e}" raise OutputParserException(msg, llm_output=text)
鲸鱼我遇到一个问题,目前的langchain必须使用v1版本的pydantic,如果使用了v2版本抛出的异常类型不对,会导致PydanticOutputParser无法捕获正常的ValidationError异常,从而不会去请求openAI修复response。 PydanticOutputParser的具体捕获代码是这里 class PydanticOutputParser(BaseOutputParser[T]): """Parse an output using a pydantic model.""" pydantic_object: Type[T] """The pydantic model to parse.""" def parse(self, text: str) -> T: try: # Greedy search for 1st json candidate. match = re.search( r"\{.*\}", text.strip(), re.MULTILINE | re.IGNORECASE | re.DOTALL ) json_str = "" if match: json_str = match.group() json_object = json.loads(json_str, strict=False) return self.pydantic_object.parse_obj(json_object) except (json.JSONDecodeError, ValidationError) as e: # 这里只能捕获v1版本的ValidationError name = self.pydantic_object.__name__ msg = f"Failed to parse {name} from completion {text}. Got: {e}" raise OutputParserException(msg, llm_output=text)作者回复: 同学的这个观察很好。也很有用。可以再LangChain中Log一个Issue一起讨论一下解决方案。
2023-10-25归属地:北京- 在路上佳哥好,我发现在OutputFixingParser示例中,如果做如下修改: new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI(temperature=0)) 或者 new_parser = OutputFixingParser.from_llm(parser=parser, llm=OpenAI(temperature=0)) 可以得到稳定的输出: name='康乃馨' colors=['粉红色', '白色', '红色', '紫色', '黄色'] 而不是: name='Rose' colors=['red', 'pink', 'white']
作者回复: 很好的尝试,谢谢分享!!
2023-09-20归属地:广东  zhang老师你好,我是一个从事了几年的C语言开发者。计划在机器学习领域拓展拓展。可是我看了LangChain的一些基本理念之后,使用提示模板在性能方面比直接用代码处理异常开销要差很多吧。 比如作为一个server对外提供服务的时候,它的延迟、并发数等又该如何考量呢?2024-03-06归属地:北京
zhang老师你好,我是一个从事了几年的C语言开发者。计划在机器学习领域拓展拓展。可是我看了LangChain的一些基本理念之后,使用提示模板在性能方面比直接用代码处理异常开销要差很多吧。 比如作为一个server对外提供服务的时候,它的延迟、并发数等又该如何考量呢?2024-03-06归属地:北京- Geek_a23cc7Traceback (most recent call last): File "E:\Code-python\langchain-main\langchain-main\07_解析输出\01_Pydantic_Parser.py", line 71, in <module> parsed_output = output_parser.parse(output) File "D:\Anaconda\envs\python3.10\lib\site-packages\langchain\output_parsers\pydantic.py", line 34, in parse return self.pydantic_object.parse_obj(json_object) File "D:\Anaconda\envs\python3.10\lib\site-packages\typing_extensions.py", line 2499, in wrapper return arg(*args, **kwargs) File "D:\Anaconda\envs\python3.10\lib\site-packages\pydantic\main.py", line 1027, in parse_obj return cls.model_validate(obj) File "D:\Anaconda\envs\python3.10\lib\site-packages\pydantic\main.py", line 503, in model_validate return cls.__pydantic_validator__.validate_python( pydantic_core._pydantic_core.ValidationError: 4 validation errors for FlowerDescription flower_type Field required [type=missing, input_value={'properties': {'flower_t...description', 'reason']}, input_type=dict] For further information visit https://errors.pydantic.dev/2.5/v/missing price Field required [type=missing, input_value={'properties': {'flower_t...description', 'reason']}, input_type=dict] For further information visit https://errors.pydantic.dev/2.5/v/missing description Field required [type=missing, input_value={'properties': {'flower_t...description', 'reason']}, input_type=dict] For further information visit https://errors.pydantic.dev/2.5/v/missing reason Field required [type=missing, input_value={'properties': {'flower_t...description', 'reason']}, input_type=dict] For further information visit https://errors.pydantic.dev/2.5/v/missing 黄老师您看一下我这个问题2024-01-30归属地:黑龙江1