

32|存储引擎:数据清洗与存储
郑建勋

你好,我是郑建勋。
爬虫项目的一个重要的环节就是把最终的数据持久化存储起来,数据可能会被存储到 MySQL、MongoDB、Kafka、Excel 等多种数据库、中间件或者是文件中。
要达到这个目的,我们很容易想到使用接口来实现模块间的解耦。我们还要解决数据的缓冲区问题。最后,由于爬虫的数据可能是多种多样的,如何对最终数据进行合理的抽象也是我们需要面临的问题。
这节课,我们将书写一个存储引擎,用它来处理数据的存储问题。
爬取结构化数据
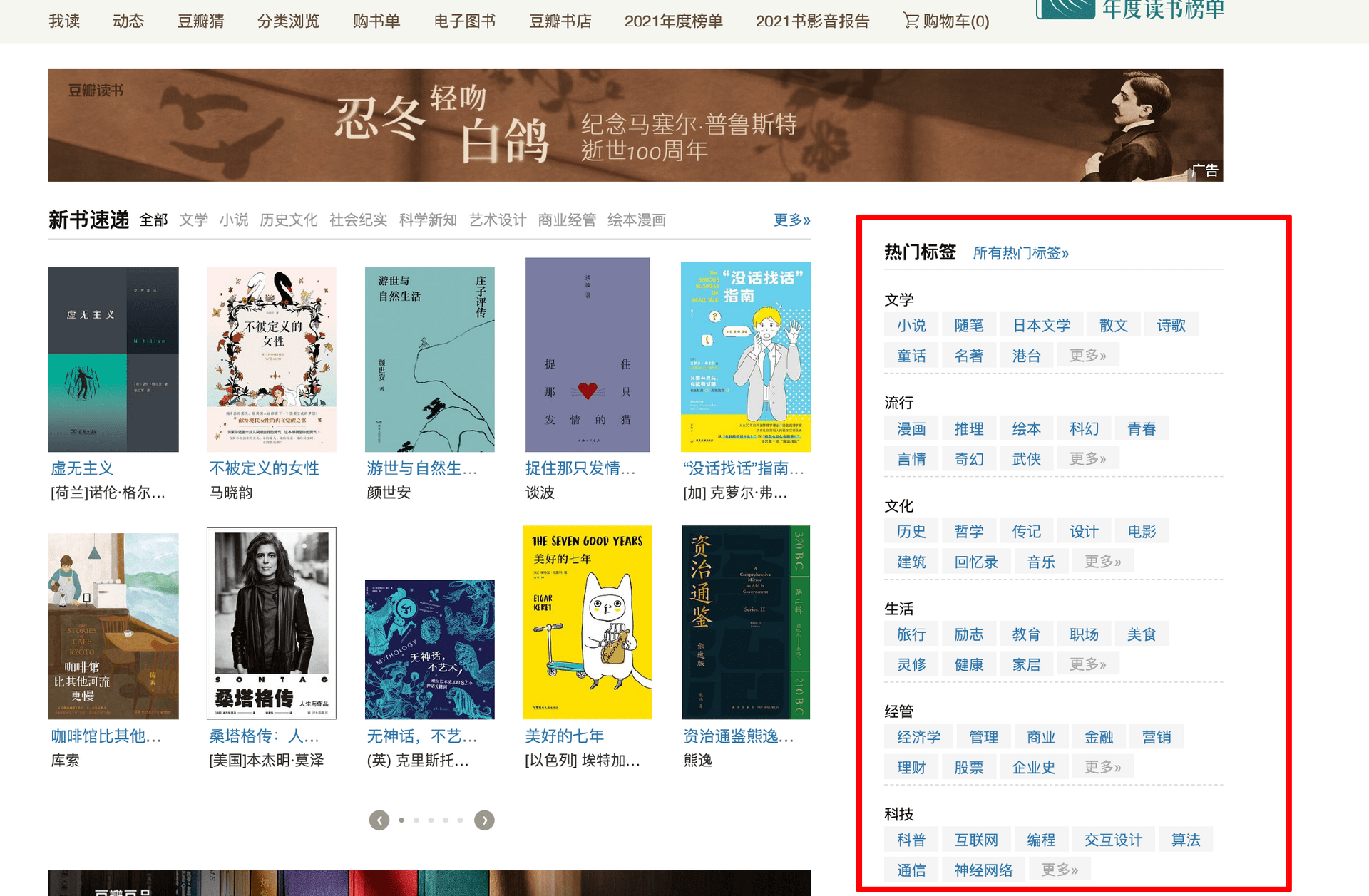
之前我们爬取的案例比较简单,像是租房网站的信息等。但是实际情况下,我们的爬虫任务通常需要获取结构化的数据。例如一本书的信息就包含书名、价格、出版社、简介、评分等。为了生成结构化的数据,我以豆瓣图书为例书写我们的任务规则。
第一步,从首页中右侧获取热门标签的信息。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了如何通过编写存储引擎来解决爬虫项目中的数据持久化存储问题。作者以爬取豆瓣图书信息为例,详细介绍了任务规则的编写过程,并提出了对数据的抽象,将每条要存储的数据抽象为DataCell结构,并规定了其中的Key-Value对应关系。此外,文章还展示了如何实现存储引擎Storage,以及对存储引擎的验证。通过实际代码示例,深入浅出地介绍了存储引擎的设计与实现过程。在数据输出时,作者提出了一个问题:是否可以直接使用像Book这样的结构体,将数据直接传递给存储引擎来处理。这篇文章内容丰富,涵盖了存储引擎的设计、实现和验证,对于需要处理爬虫项目数据存储问题的读者具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Go 进阶 · 分布式爬虫实战》,新⼈⾸单¥68
《Go 进阶 · 分布式爬虫实战》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 出云按文中的写法,SqlStore.Flush() 方法不能处理同一个Batch中存在不同Task的DataCell的情况。2023-03-12归属地:广东1
出云按文中的写法,SqlStore.Flush() 方法不能处理同一个Batch中存在不同Task的DataCell的情况。2023-03-12归属地:广东1
收起评论

