

27 | 稳定性场景之二:怎样搞定磁盘不足产生的瓶颈问题?
高楼

你好,我是高楼。
上节课,我们讲解了稳定性场景的两个要点:运行时长和压力量级,并通过课程的示例系统,带你具体操作了稳定性场景。
在定向分析的第一个阶段中,我们分析了虚拟机内存超分导致的操作系统 OOM 的问题,发现是配置的超分过大导致的。在我们降低了虚拟机的内存之后,稳定性场景的运行时间超过了 12 个小时,累积业务量达到 7200 多万,这样的结果已经达到了我们的目标。
可是,由于贪心,我并没有停止场景,就在它继续运行的时候,又出现了新问题……因此,我们今天就进入到定向分析的第二阶段,看看还有什么问题在等着我们。
定向监控分析
定向分析第二阶段
当场景继续运行的时候,我看到了这样的数据:
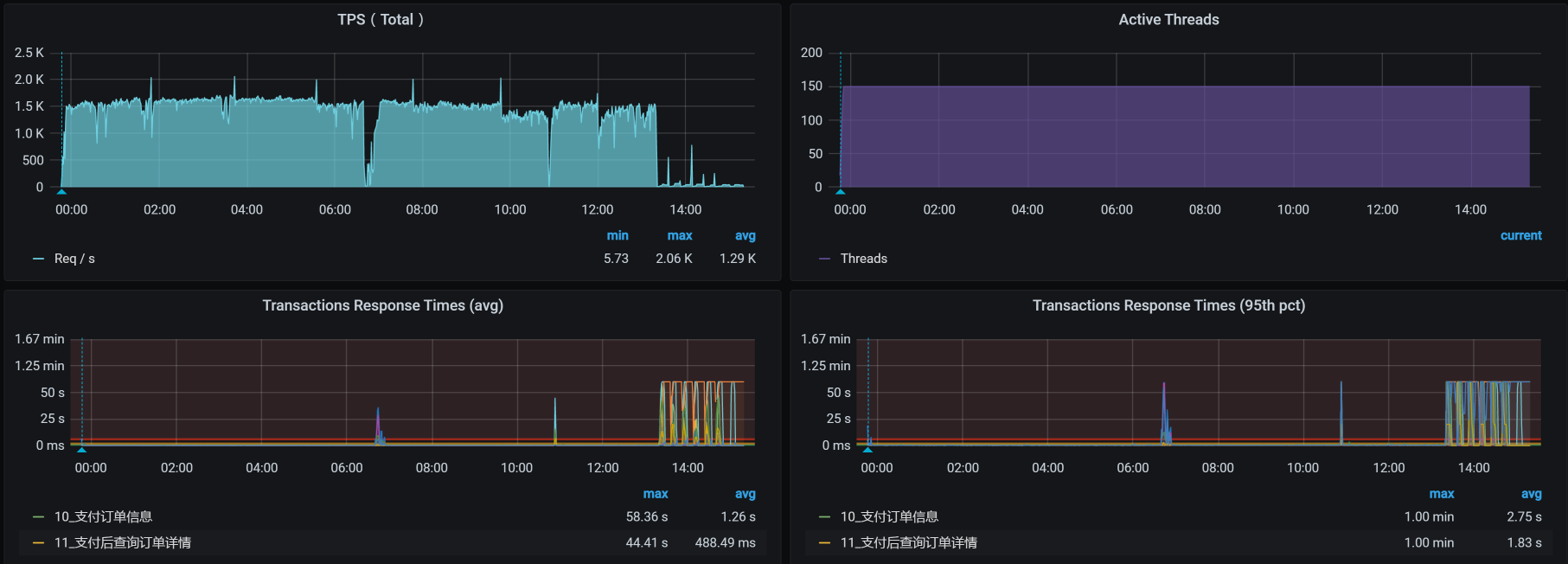
从图中我们可以很明显地看到,在场景持续运行的过程中,TPS 掉下来了,响应时间则是蹭蹭往上涨。
我们看一下这时候的总业务累积量:
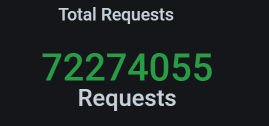
也就是说,多了 20 多万的业务累积量。
见到问题,不分析总是觉得不那么舒服,那我们就来分析一下。
还是按照性能分析决策树,我们把计数器一个一个查过去。在我查看 MySQL 的 Pod 日志时,发现它一直在被删掉重建:
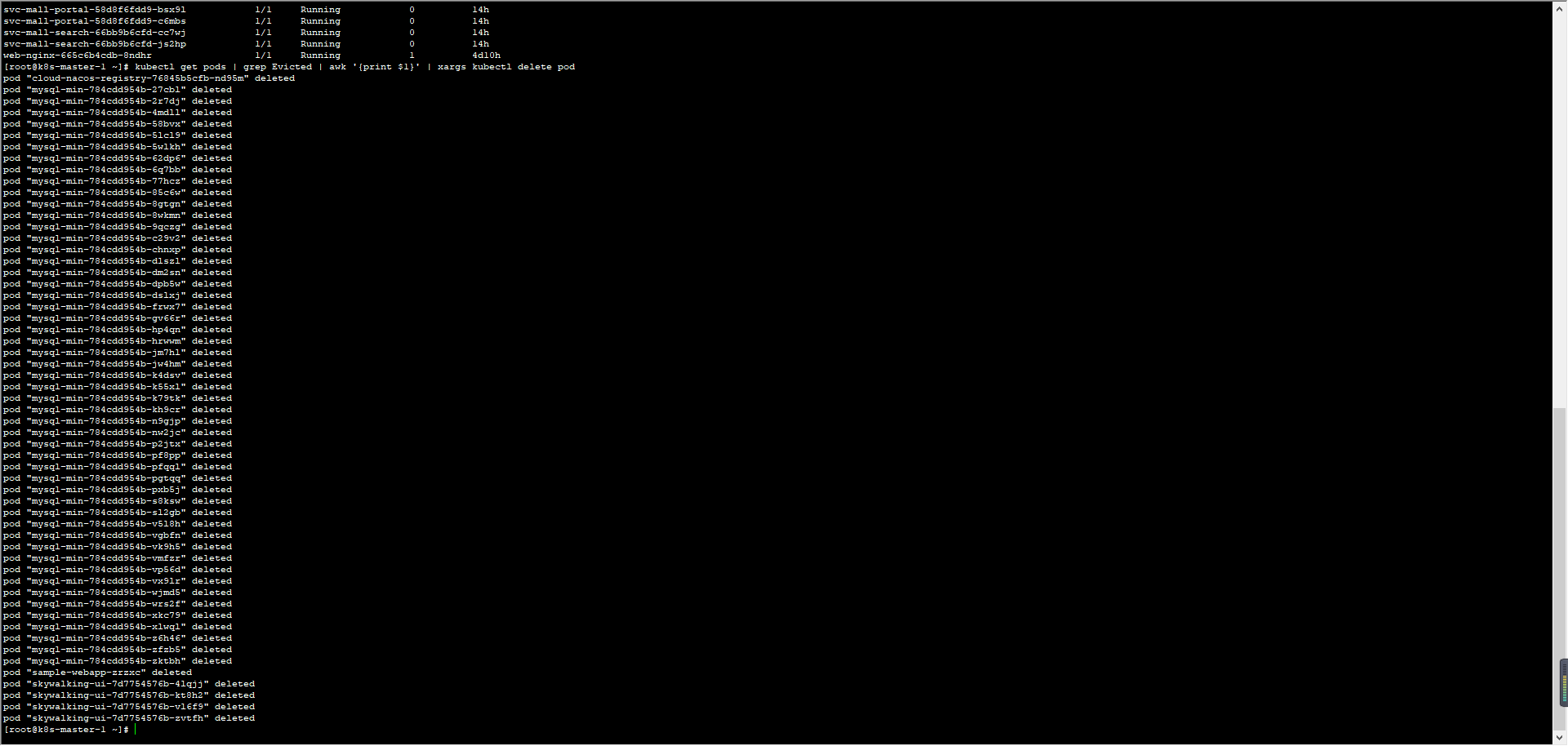
请注意,我们这是一个示例系统,为了方便重建,我把 MySQL 放到 Pod 中了。如果是在真实的环境中,我建议你最好根据生产的实际配置来做数据库的配置。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了磁盘不足导致的性能瓶颈问题,并提供了解决方案。作者通过实际案例分析,详细介绍了在稳定性场景中出现的问题及解决方法。重点介绍了定向分析的过程和方法,帮助读者了解如何通过监控分析解决系统性能问题。作者通过定向分析的第一个阶段发现了虚拟机内存超分导致的操作系统OOM问题,并成功解决了这一问题。随后,在场景继续运行时,又出现了新问题,作者引出了定向监控分析的第二阶段。通过分析数据和操作系统日志,作者发现磁盘配额被用满导致MySQL的Pod一直在被删掉重建,最终提出了扩大磁盘的解决方案。整篇文章通过实际案例和操作示例,为读者提供了解决磁盘不足产生的瓶颈问题的方法,具有很高的实用性和指导意义。文章还总结了在稳定性场景中遇到的问题,并提出了保证磁盘使用量不会随场景持续增加的建议。文章内容丰富,涉及到了实际案例分析和解决方案,对于需要解决类似问题的读者具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高楼的性能工程实战课》,新⼈⾸单¥59
《高楼的性能工程实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(4)
- 最新
- 精选
 knife分享个老运维的小技巧,在磁盘放20G的空文件,关键时刻能救命
knife分享个老运维的小技巧,在磁盘放20G的空文件,关键时刻能救命作者回复: 一看就是高手呀。
2022-05-0623 小孔丞相1.你在稳定性场景中遇到过什么由于业务不断累积导致的问题? 之前在稳定性测试过程中,遇到多redis的内存一直持续增长,导致内存OOM。后来排查是因为key的过期时间设置的太长了,改正后redis内存基本稳定了。 2.在稳定性场景中,如何保证磁盘使用量不会随场景持续增加,而是保持在一个使用量级? 数据类型的目录,一般会有个保留机制,保留3个月;日志类型的会做日志轮询
小孔丞相1.你在稳定性场景中遇到过什么由于业务不断累积导致的问题? 之前在稳定性测试过程中,遇到多redis的内存一直持续增长,导致内存OOM。后来排查是因为key的过期时间设置的太长了,改正后redis内存基本稳定了。 2.在稳定性场景中,如何保证磁盘使用量不会随场景持续增加,而是保持在一个使用量级? 数据类型的目录,一般会有个保留机制,保留3个月;日志类型的会做日志轮询作者回复: 不错不错。
2021-06-213- sky_you1.你在稳定性场景中遇到过什么由于业务不断累积导致的问题? 通常是内存不足。另外就是在混合场景中不曾出现的Full GC 会在稳定性测试中出现,然后通过GC的发生频率,和发生时间适当的调整堆栈的大小。 2.在稳定性场景中,如何保证磁盘使用量不会随场景持续增加,而是保持在一个使用量级? 通过日志文件归档,日志旋转,保持一定时间内的日志的方式,控制磁盘的无限扩增。
作者回复: 不错,靠谱。
2021-06-183  姑射仙人1. 你在稳定性场景中遇到过什么由于业务不断累积导致的问题? 1). pod未设置memory limit,长时间运行导致k8s随机删除pod。劣币驱逐良币。 2). 数据库一些明细类、日志类表增长较快,有一些骚的join操作会挂掉。 2. 在稳定性场景中,如何保证磁盘使用量不会随场景持续增加,而是保持在一个使用量级? 1) Docker的日志输出也要设置大小去轮转,长时间运行日志太大。 2) 业务上debug日志,或者info日志输出的太多了。不要打印结果集明细数据到日志中。
姑射仙人1. 你在稳定性场景中遇到过什么由于业务不断累积导致的问题? 1). pod未设置memory limit,长时间运行导致k8s随机删除pod。劣币驱逐良币。 2). 数据库一些明细类、日志类表增长较快,有一些骚的join操作会挂掉。 2. 在稳定性场景中,如何保证磁盘使用量不会随场景持续增加,而是保持在一个使用量级? 1) Docker的日志输出也要设置大小去轮转,长时间运行日志太大。 2) 业务上debug日志,或者info日志输出的太多了。不要打印结果集明细数据到日志中。作者回复: 总结的不错哦。
2022-01-21
收起评论

