

07 | 性能场景的数据到底应该做成什么样子?
高楼

你好,我是高楼。
在性能项目中,性能数据是非常重要的输入资源。但是我经常看到有人拿着少得可怜的数据,来做比较大的压力,这显然不符合真实的场景,虽然拿到的结果很好看,但并不会得到什么有价值的结果。所以,今天我们就来讲一下性能场景中的数据到底应该做成什么样子。
在 RESAR 性能工程中,场景里使用的数据需要满足两个方面:
第一,数据要符合真实环境中的数据分布,因为只有这样,我们才能模拟出相应的 IO 操作;
第二,要符合真实用户输入的数据,以真正模拟出真实环境中的用户操作。
而这两个方面分别对应着两类数据:铺底数据和参数化数据。我们先来看铺底数据。
铺底数据
在通常的线上系统架构中,系统中用到的数据分为两部分:静态数据(图中红色点)和动态数据(图中绿色点),这也是我们在性能场景中需要存入的铺底数据。
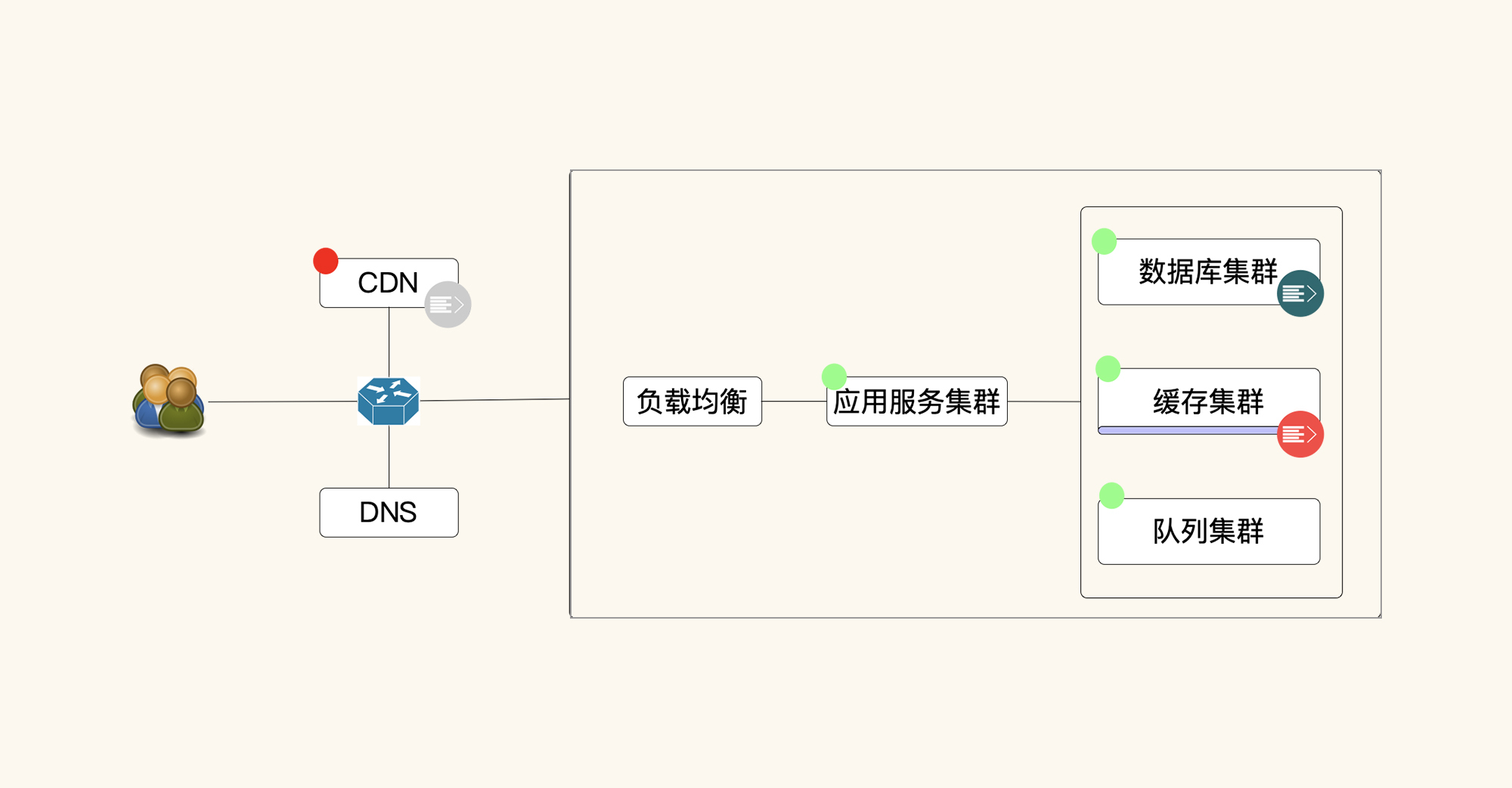
从这个简单的结构图中不难看出,如果没有铺底数据,那就相当于是一个空系统。但是在生产环境中,这个系统肯定不会是空的,所以要有足够的数据在里面。如果数据不真实,我们就无法模拟出生产上有真实数据的场景,比如应用的内存占用、数据库 IO 能力、网络吞吐能力等。
其中,对于静态数据而言,我们最容易出现的问题是,一想到它占的网络带宽大,就觉得要用 CDN 了 ;或者是觉得不模拟静态数据,就是不符合真实场景,不支持我们的优化结果了。其实,数据放在哪里,怎么做最合理,怎么做成本最低,这些都需要综合考虑,并不是一味跟风,别人怎么做我们就要怎么做。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

在性能场景中,数据的设计和模拟对系统的影响至关重要。RESAR性能工程中,数据分为铺底数据和参数化数据。铺底数据需要满足真实性和充分性的条件,而参数化数据则需要足够的数据量和符合真实用户输入的数据。文章通过具体案例和分析,强调了铺底数据在性能场景中的重要性,以及不同数据量对系统各方面的影响。在造数据时,可以采用多种方法,只要能快速造出足够的数据量即可。最后,读者被留下两个思考题,引发思考和交流。整体而言,本文深入浅出地介绍了性能场景数据设计的重要性和方法,对读者具有一定的指导意义。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《高楼的性能工程实战课》,新⼈⾸单¥59
《高楼的性能工程实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(24)
- 最新
- 精选
- Geek_bbe4c8“对于唯一性数据(比如用户数据)来说,我们需要使用多少参数化数据是非常容易计算的。比如一个运行半小时的场景,TPS 如果是 100 的话,那就需要 18 万的数据量” 老师,你这段话的意思是,要模拟每一个压测请求都是不同的用户发起的,这里需要构造18万个不同用户?
作者回复: 是的。
2021-04-123 - 道长老师,我想问下你说尽量模拟真实用户效果,但像我们测试web一般都是忽略了css,js等直接测试主接口,这种是否合理呢?
作者回复: 对后端的压力来说,是合理的。 如果从用户的角度来说,显然是不合理的。 所以我们要做相应的换算。 请看第8篇中的换算。
2021-04-083 - wfw123老师,通常我们执行性能脚本的时候不会执行一次,如果按照上面30分钟100tps的场景,对于不可重复使用的数据,如果我们每次执行前做一次数据,太不易用啦,但是不造数据还不行,那么我们如何来解决这样的数据问题呢?
作者回复: 做数据库备份回滚哇。
2021-04-0623 - yz老师, 问题1,这里说的静态铺地数据指图片?视频这些吗? 问题2,参数化数据是否影响压测机的性能,看压测机压力就可以了吧? 问题3,若压测环境跟生产环境硬件配置不对等,那数据量是不是也等比缩放?
作者回复: 1. 是的。 2. 是的。不过要分析了参数化数据量的具体影响才能判断。 3. 也要缩放,不过不一定是等比的。这个要做基准测试才能知道。
2021-05-282 - Geek_648160老师 使用mysql和redis方式参数化,这个前提是db和redis本身没有瓶颈,是吗?
作者回复: 那必然的。有就分析处理嘛。
2022-03-151  不将就高老师,请教个问题,文中提到了使用redis和mysql作为参数化的数据源,那么在性能测试执行的过程中,会不断的通过连接redis和mysql来查询参数化数据,这样的话也有很大的性能损失吧?
不将就高老师,请教个问题,文中提到了使用redis和mysql作为参数化的数据源,那么在性能测试执行的过程中,会不断的通过连接redis和mysql来查询参数化数据,这样的话也有很大的性能损失吧?作者回复: 有损失,也可以接受。 只要压力能发起来。
2021-10-231 啸龙请教高老师, 原文中 “对于唯一性数据(比如用户数据)来说,我们需要使用多少参数化数据是非常容易计算的。比如一个运行半小时的场景,TPS 如果是 100 的话,那就需要 18 万的数据量,计算过程如下:数据量=30min×60s×100TPS=18w” (1)如果造出18万用户,实际我只需要TPS100,那我应该用18万中多少用户去并发呢,是简单的算成:如果1个业务时间2s,那就是100/0.5=200 并发用户 (2)如果按照您的思路,所有并发以TPS来计算,那么有些性能工具,如jmeter中的同步定时器(synchronizing timer)用不用也无所谓了,因为我同步不同步无所谓了,只要压测到最后满足100TPS就可以了,无非多增加几个线程或用户而已?
啸龙请教高老师, 原文中 “对于唯一性数据(比如用户数据)来说,我们需要使用多少参数化数据是非常容易计算的。比如一个运行半小时的场景,TPS 如果是 100 的话,那就需要 18 万的数据量,计算过程如下:数据量=30min×60s×100TPS=18w” (1)如果造出18万用户,实际我只需要TPS100,那我应该用18万中多少用户去并发呢,是简单的算成:如果1个业务时间2s,那就是100/0.5=200 并发用户 (2)如果按照您的思路,所有并发以TPS来计算,那么有些性能工具,如jmeter中的同步定时器(synchronizing timer)用不用也无所谓了,因为我同步不同步无所谓了,只要压测到最后满足100TPS就可以了,无非多增加几个线程或用户而已?作者回复: 数据一定是按总体的业务积累量来算的。 压力工具的集合点(同步定时器),我觉得没有必要使用。真实场景中也不会有这样的时间点。
2021-10-141 掌柜参数化直接从数据库取,连接数据库,查询数据需要消耗时间,而且会占用数据库资源,这种参数化方式很明显对压测的性能有影响,老师为什么还要推荐这种方式呢?
掌柜参数化直接从数据库取,连接数据库,查询数据需要消耗时间,而且会占用数据库资源,这种参数化方式很明显对压测的性能有影响,老师为什么还要推荐这种方式呢?作者回复: 在参数化数据多的时候建议用缓存或数据库中直接取数据的方式。 但是你可以不用被测系统的缓存或数据库嘛,独立搭建一个专门存参数化数据的缓存或数据库即可。
2021-05-251 金面王朝老师,jemeter参数化文件一般超过多少条的数据量会使jmeter成为瓶颈呢
金面王朝老师,jemeter参数化文件一般超过多少条的数据量会使jmeter成为瓶颈呢作者回复: 这个倒没有定论。还是得看一下参数化的是什么。有的放一个数据,有的放十个数据,那不一样嘛。
2021-05-071 一只胖虎老师真实环境下单都是要真正的支付钱的,这个怎么解决
一只胖虎老师真实环境下单都是要真正的支付钱的,这个怎么解决作者回复: 如果对方提供测试系统就可以连。如果不提供,那只能mock了。
2021-04-091
收起评论

