

31 | GroupMetadataManager:查询位移时,不用读取位移主题?
胡夕

你好,我是胡夕。
上节课,我们学习了位移主题中的两类消息:消费者组注册消息和消费者组已提交位移消息。今天,我们接着学习位移主题,重点是掌握写入位移主题和读取位移主题。
我们总说,位移主题是个神秘的主题,除了它并非我们亲自创建之外,它的神秘之处还体现在,它的读写也不由我们控制。默认情况下,我们没法向这个主题写入消息,而且直接读取该主题的消息时,看到的更是一堆乱码。因此,今天我们学习一下读写位移主题,这正是去除它神秘感的重要一步。
写入位移主题
我们先来学习一下位移主题的写入。在第 29 讲学习 storeOffsets 方法时,我们已经学过了 appendForGroup 方法。Kafka 定义的两类消息类型都是由它写入的。在源码中,storeGroup 方法调用它写入消费者组注册消息,storeOffsets 方法调用它写入已提交位移消息。
首先,我们需要知道 storeGroup 方法,它的作用是向 Coordinator 注册消费者组。我们看下它的代码实现:
为了方便你理解,我画一张图来展示一下 storeGroup 方法的逻辑。
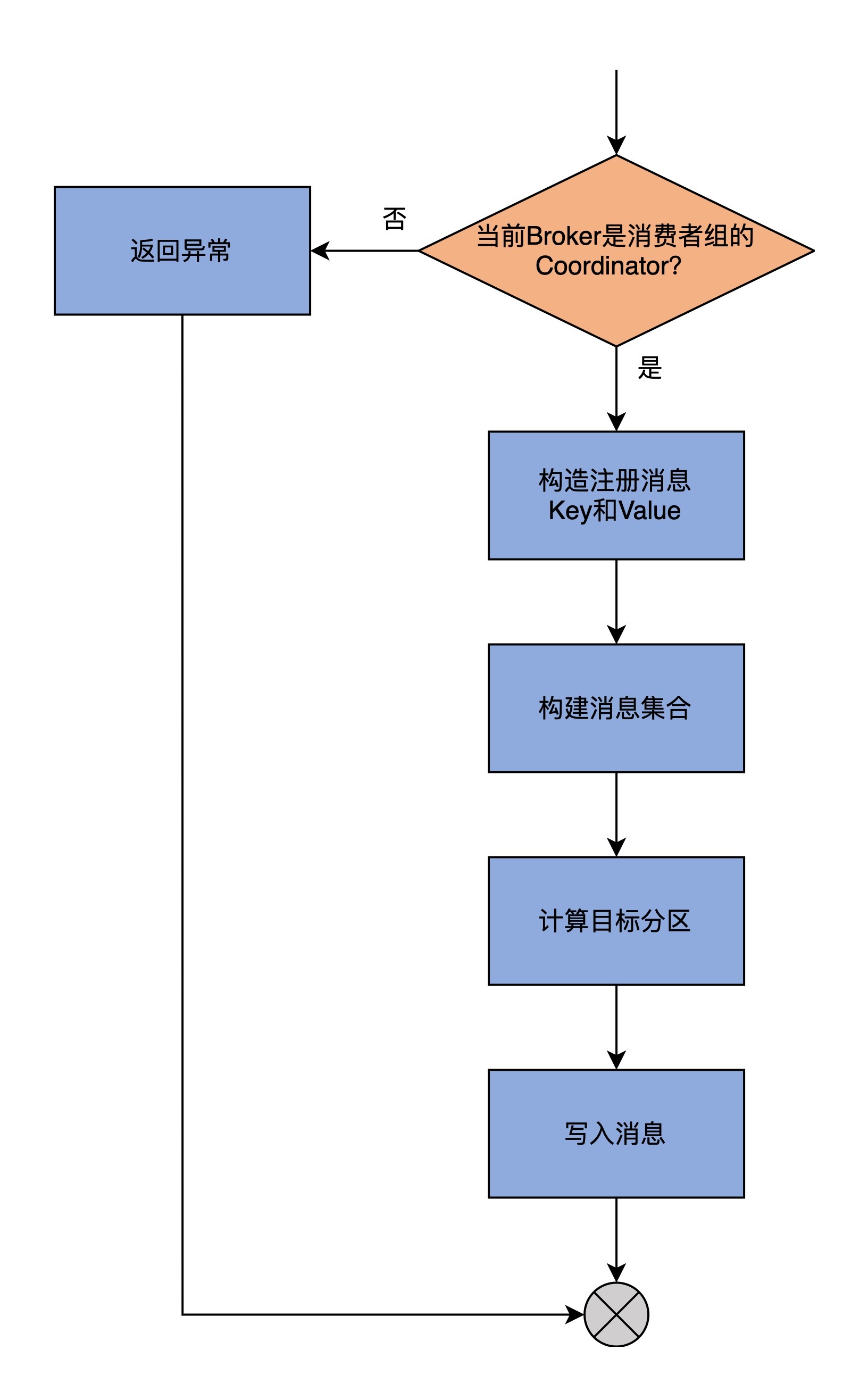
storeGroup 方法的第 1 步是调用 getMagic 方法,来判断当前 Broker 是否是该消费者组的 Coordinator 组件。判断的依据,是尝试去获取位移主题目标分区的底层日志对象。如果能够获取到,就说明当前 Broker 是 Coordinator,程序进入到下一步;反之,则表明当前 Broker 不是 Coordinator,就构造一个 NOT_COORDINATOR 异常返回。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了Kafka中位移主题的读取和处理过程,适合对Kafka技术感兴趣的读者阅读。文章首先详细讲解了写入位移主题的过程,包括storeGroup方法的实现逻辑和调用过程。接着,通过代码实例和流程图清晰地展示了读取位移主题的操作流程,包括创建列表和缓冲区、计算日志起始位移值以及消息集合的处理。文章还重点介绍了GroupMetadataManager类中读写位移主题的方法代码,以及Coordinator在其中扮演的角色。读者可以了解到查询消费者组已提交位移时,Kafka是直接从内存中的消费者组元数据缓存中查询,而不是读取位移主题。总体而言,本文通过对GroupMetadataManager类的源码解析,帮助读者深入理解了Kafka中位移主题的读取和处理过程,为他们提供了宝贵的技术知识。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Kafka 核心源码解读》,新⼈⾸单¥59
《Kafka 核心源码解读》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(2)
- 最新
- 精选
 胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,我们重点学习了消费者组管理器GroupMetadataManager类中关于位移主题的管理。课后我请你思考下kafka-console-consumer脚本中输出字段的含义。对于已提交位移消息来说,它的Key格式是offset_commit::group=<groupId>,partition=<分区号>。它的Value可能有三种取值:1、如果是tombstone消息,那么Value值是<DELETE>;2、如果仅包含位移消息,则Value是offset=<offset>;3、如果还包括已提交的元数据信息,那么Value是offset=<offset>,metadata=<metadata> okay,你同意这个说法吗?或者说你有其他的看法吗?我们可以一起讨论下。2020-07-211
胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,我们重点学习了消费者组管理器GroupMetadataManager类中关于位移主题的管理。课后我请你思考下kafka-console-consumer脚本中输出字段的含义。对于已提交位移消息来说,它的Key格式是offset_commit::group=<groupId>,partition=<分区号>。它的Value可能有三种取值:1、如果是tombstone消息,那么Value值是<DELETE>;2、如果仅包含位移消息,则Value是offset=<offset>;3、如果还包括已提交的元数据信息,那么Value是offset=<offset>,metadata=<metadata> okay,你同意这个说法吗?或者说你有其他的看法吗?我们可以一起讨论下。2020-07-211 胡小禾读__consumer_offset 的逻辑第一步那里有点不是很理解 while (currOffset < logEndOffset && readAtLeastOneRecord && !shuttingDown.get()){ } 它这里貌似是从 Log 的起始位置开始读取的,那么: 1. 每一次while循环,会不会有后面的查询结果查询前者的情况 2. 假如log很大,难道还费挺久从头开始读那四个列表,然后更新到缓存? 难道不是读Log最后几条就可以?2021-12-291
胡小禾读__consumer_offset 的逻辑第一步那里有点不是很理解 while (currOffset < logEndOffset && readAtLeastOneRecord && !shuttingDown.get()){ } 它这里貌似是从 Log 的起始位置开始读取的,那么: 1. 每一次while循环,会不会有后面的查询结果查询前者的情况 2. 假如log很大,难道还费挺久从头开始读那四个列表,然后更新到缓存? 难道不是读Log最后几条就可以?2021-12-291
收起评论

