

01 | 日志段:保存消息文件的对象是怎么实现的?

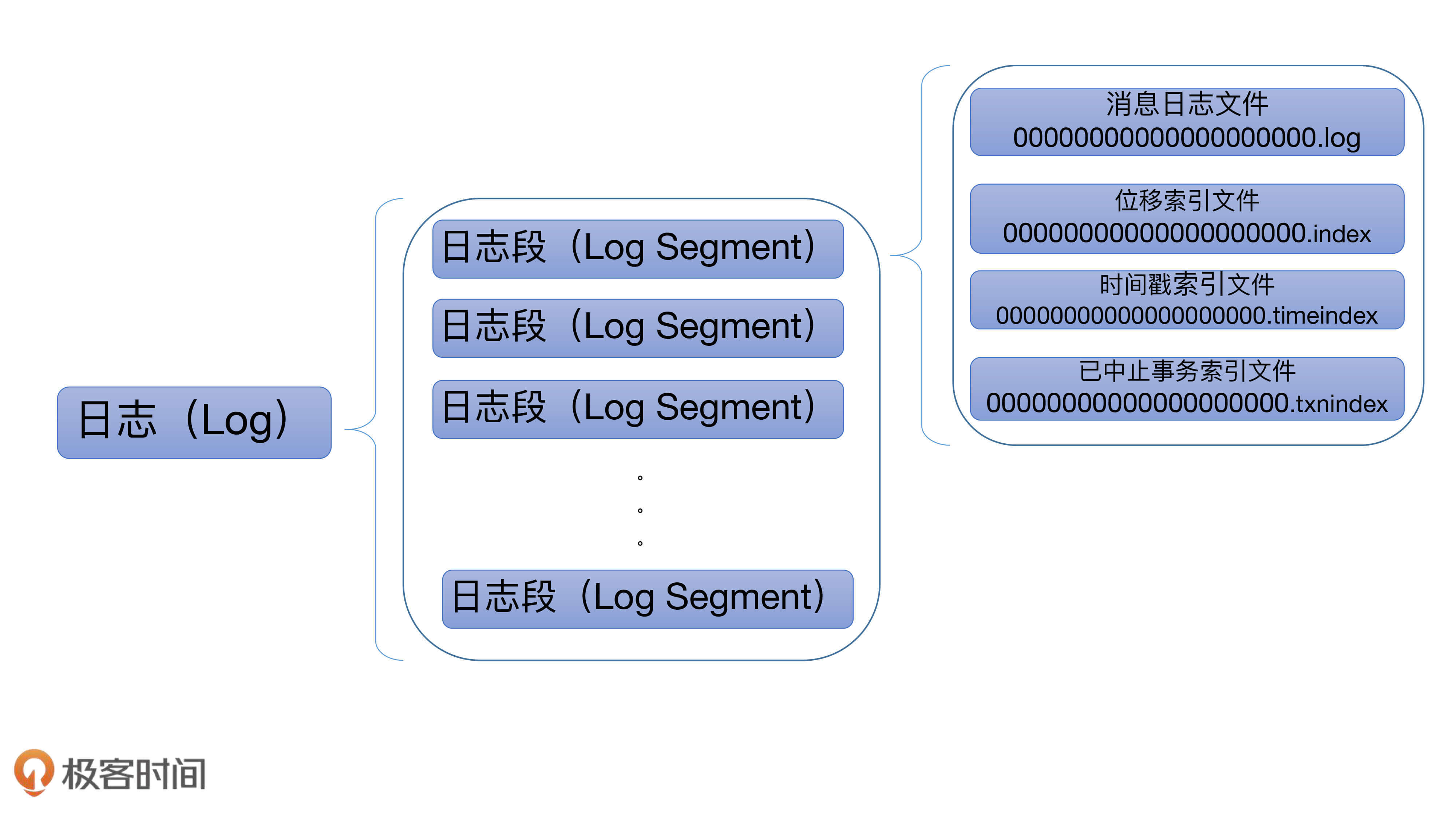
Kafka 日志结构概览
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文深入解析了Kafka日志段的重要性和实现细节,包括日志段的组织架构和重要组件,以及LogSegment类的定义和关键方法。重点分析了append、read和recover方法,强调了它们在日志段对象中的重要性。此外,还提到了truncateTo方法,并引发了对于指定位移值超出日志段保存最大位移值的思考。通过源码解析,读者可以深入了解Kafka消息的保存和组织方式,以及解决实际问题的方法。总之,本文内容详实,对Kafka日志段的重要性和实现细节进行了深入解析,对于想深入了解Kafka源码的读者具有很高的参考价值。
《Kafka 核心源码解读》,新⼈⾸单¥59

全部留言(74)
- 最新
- 精选
 胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,咱们重点学习了如何构建Kafka工程和搭建源码阅读环境。课后我让你去尝试寻找kafka-console-producer.sh脚本对应的Java类是哪个文件。现在我给出答案:如果我们打开这个SHELL脚本,可以清楚地发现它调用了kafka.tools.ConsoleProducer类。这个类位于core包的src/main/scala/kafka/tools下,文件名是ConsoleProducer.scala。 怎么样,你找到了吗?我们可以一起讨论下。2020-04-267
胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,咱们重点学习了如何构建Kafka工程和搭建源码阅读环境。课后我让你去尝试寻找kafka-console-producer.sh脚本对应的Java类是哪个文件。现在我给出答案:如果我们打开这个SHELL脚本,可以清楚地发现它调用了kafka.tools.ConsoleProducer类。这个类位于core包的src/main/scala/kafka/tools下,文件名是ConsoleProducer.scala。 怎么样,你找到了吗?我们可以一起讨论下。2020-04-267 小虞仔置顶offsetIndex.truncateTo(offset) 和 timeIndex.truncateTo(offset)中有相同的一部分代码: /* There are 3 cases for choosing the new size * 1) if there is no entry in the index <= the offset, delete everything * 2) if there is an entry for this exact offset, delete it and everything larger than it * 3) if there is no entry for this offset, delete everything larger than the next smallest */ val newEntries = if(slot < 0) 0 else if(relativeOffset(idx, slot) == offset - baseOffset) slot else slot + 1 我觉得这应该解释了老师的提问:如果指定的位移值特别特别大,并且没有可以截断的消息时,会截断比下一个消息的位移大的所有的消息。代码里面用了solt+1来表示。不知道我理解的对不对。
小虞仔置顶offsetIndex.truncateTo(offset) 和 timeIndex.truncateTo(offset)中有相同的一部分代码: /* There are 3 cases for choosing the new size * 1) if there is no entry in the index <= the offset, delete everything * 2) if there is an entry for this exact offset, delete it and everything larger than it * 3) if there is no entry for this offset, delete everything larger than the next smallest */ val newEntries = if(slot < 0) 0 else if(relativeOffset(idx, slot) == offset - baseOffset) slot else slot + 1 我觉得这应该解释了老师的提问:如果指定的位移值特别特别大,并且没有可以截断的消息时,会截断比下一个消息的位移大的所有的消息。代码里面用了solt+1来表示。不知道我理解的对不对。作者回复: 对的:)
2020-04-16511 Eternal一个分区partion对应一个Log对象 一个Log对象对应一个日志目录 一个日志目录有多个LogSegment,一个Logment概念下有4个文件,多一个LogSegment下的文件都是在一个目录下的,也就是LogSegment只是一个概念不是真的文件目录 一个LogSegment就有4个物理文件,那么集群有文件=4 * LogSegment*partion*副本因子*topic。当topic和分区数很多的时候,系统的文件句柄就不够用了,好像系统默认是65535 所有我们对topic的数量和分区的数量需要有一个合理的规划。 我有一个疑问:我们公司之前遇到过类似的问题,业务方创建了非常多的topic和分区,然后一次broker重启的时候,重启失败,原因是Map failed 内存映射失败,这个和老师文中讲的“ Broker 在启动时会从磁盘上加载所有日志段信息到内存中,并创建相应的 LogSegment 对象实例” 好像是一样的,不止我理解的对不对:
Eternal一个分区partion对应一个Log对象 一个Log对象对应一个日志目录 一个日志目录有多个LogSegment,一个Logment概念下有4个文件,多一个LogSegment下的文件都是在一个目录下的,也就是LogSegment只是一个概念不是真的文件目录 一个LogSegment就有4个物理文件,那么集群有文件=4 * LogSegment*partion*副本因子*topic。当topic和分区数很多的时候,系统的文件句柄就不够用了,好像系统默认是65535 所有我们对topic的数量和分区的数量需要有一个合理的规划。 我有一个疑问:我们公司之前遇到过类似的问题,业务方创建了非常多的topic和分区,然后一次broker重启的时候,重启失败,原因是Map failed 内存映射失败,这个和老师文中讲的“ Broker 在启动时会从磁盘上加载所有日志段信息到内存中,并创建相应的 LogSegment 对象实例” 好像是一样的,不止我理解的对不对:作者回复: 是的。出现map failed + 超多分区的情况除了调整ulimit -n之外,最好调整下vm.max_map_count~
2020-04-20312- 趣一口气读完了这篇文章,感觉老师讲得特别清楚,现在我很有信心学好源码。谢谢老师,期待后续的更新。
作者回复: 谢谢,后面我们一起讨论~
2020-04-1312  小崔1.时间戳,是broker接收到消息时设置的,还是生产者发送时设置的? 2.read方法里的maxSize我理解可以由消费者设定,但是maxPosition由谁设定?又有什么用呢?防止物理位置越界么?
小崔1.时间戳,是broker接收到消息时设置的,还是生产者发送时设置的? 2.read方法里的maxSize我理解可以由消费者设定,但是maxPosition由谁设定?又有什么用呢?防止物理位置越界么?作者回复: 1. 都可以的。Kafka支持两种时间戳策略,CREATE和APPEND。前者是producer端生成的,后者是指broker端使用本机时间覆盖producer端生成的时间戳 2. 由消费者角色而定。假设不考虑事务型consumer。 如果是普通consumer,那么你只能读到HW以下的消息,那么maxPosition就是HW的物理位置——这是假设读取起始位移与hw在同一个段上,否则maxPosition就是整个段的字节数; 同理,如果是follower,那么最多可以读到LEO,maxPosition就是LEO的物理位置——同样是假设读取起始位移与hw在同一个段上
2020-04-297 灰机老师您好,我想问一下 “日志段至少新写入 4KB 的消息数据才会新增一条索引项” 这个是写在OffsetIndex 中么? 对应物理位置是***.index中么? 这个新增一条索引项不是很理解,希望老师看到后给予解答。 感谢
灰机老师您好,我想问一下 “日志段至少新写入 4KB 的消息数据才会新增一条索引项” 这个是写在OffsetIndex 中么? 对应物理位置是***.index中么? 这个新增一条索引项不是很理解,希望老师看到后给予解答。 感谢作者回复: 大致意思是说producer写入4KB的消息数据后,会为当前日志段对象的索引文件中新写入一条OffsetIndex索引项。索引文件就是***.index。4KB是由Broker端参数log.index.interval.bytes决定
2020-04-206 李奕慧不明白为啥 recover 需要清空索引文件(这里的索引文件指的是 xxx.index 文件吗?)
李奕慧不明白为啥 recover 需要清空索引文件(这里的索引文件指的是 xxx.index 文件吗?)作者回复: 可能发生截断、日志段被删除等情况,因此最好重建索引文件
2020-09-025- 灰机先回答老师提出的问题:log.truncateTo(validBytes) validBytes为要清到的大小,在truncate方法中首先会获取当前LogSegment的文件大小,当validByte> 该文件大小的时候会throws 一个异常 异常为"打算清空 xxx.log 到validBytes 这么大 但是失败了,日志段大小为当前LogSegement大小",如果validByte小于当前log byte 调用fileChannel.truncate(validBytes)进行直接截断, 同时返回截断的大小有多少字节。 请教:老师 我看到源码中val truncated = log.sizeInBytes - validBytes validBytes为从logFile中的bactch 批量读取message的字节数累加实现,而log.sizeInByte同样不是log文件读取出来的么? 为什么会出现需要truncate呢? 能否举例说明什么时候LogFile中写入了异常数据呢 这个不是很理解。
作者回复: 可能出现这种情况:日志文件写入了消息的部分字节然后broker宕机。磁盘是块设备,它可不能保证消息的全部字节要么全部写入,要么全都不写入。因此Kafka必须有机制应对这种情况,即校验+truncate
2020-04-225  Roger宇if (largestTimestamp > maxTimestampSoFar) —————- 请想问一下,既然是要追加的日志,而一个日志段段消息应该是顺序追加(推测),那为什么需要这个if 判断呢?请问老师,在什么情况下会出现需要追加的消息集合中最大时间戳小于等于当前日志段已经见到的时间戳的最大值,即 largestTimestamp <= maxTimestampSoFar的情况呢?
Roger宇if (largestTimestamp > maxTimestampSoFar) —————- 请想问一下,既然是要追加的日志,而一个日志段段消息应该是顺序追加(推测),那为什么需要这个if 判断呢?请问老师,在什么情况下会出现需要追加的消息集合中最大时间戳小于等于当前日志段已经见到的时间戳的最大值,即 largestTimestamp <= maxTimestampSoFar的情况呢?作者回复: 目前producer端是可以自行指定任意时间戳的
2020-05-044 drapeau🏖希望老师以后能讲讲页缓存这个东西
drapeau🏖希望老师以后能讲讲页缓存这个东西作者回复: 很多操作系统的书对页缓存都有介绍。简单来说,page cache是最重要的一类操作系统(特别是Linux系统)disk cache。相关介绍可以看看《Understanding the Linux Kernel》
2020-04-163

