

07 | SocketServer(上):Kafka到底是怎么应用NIO实现网络通信的?

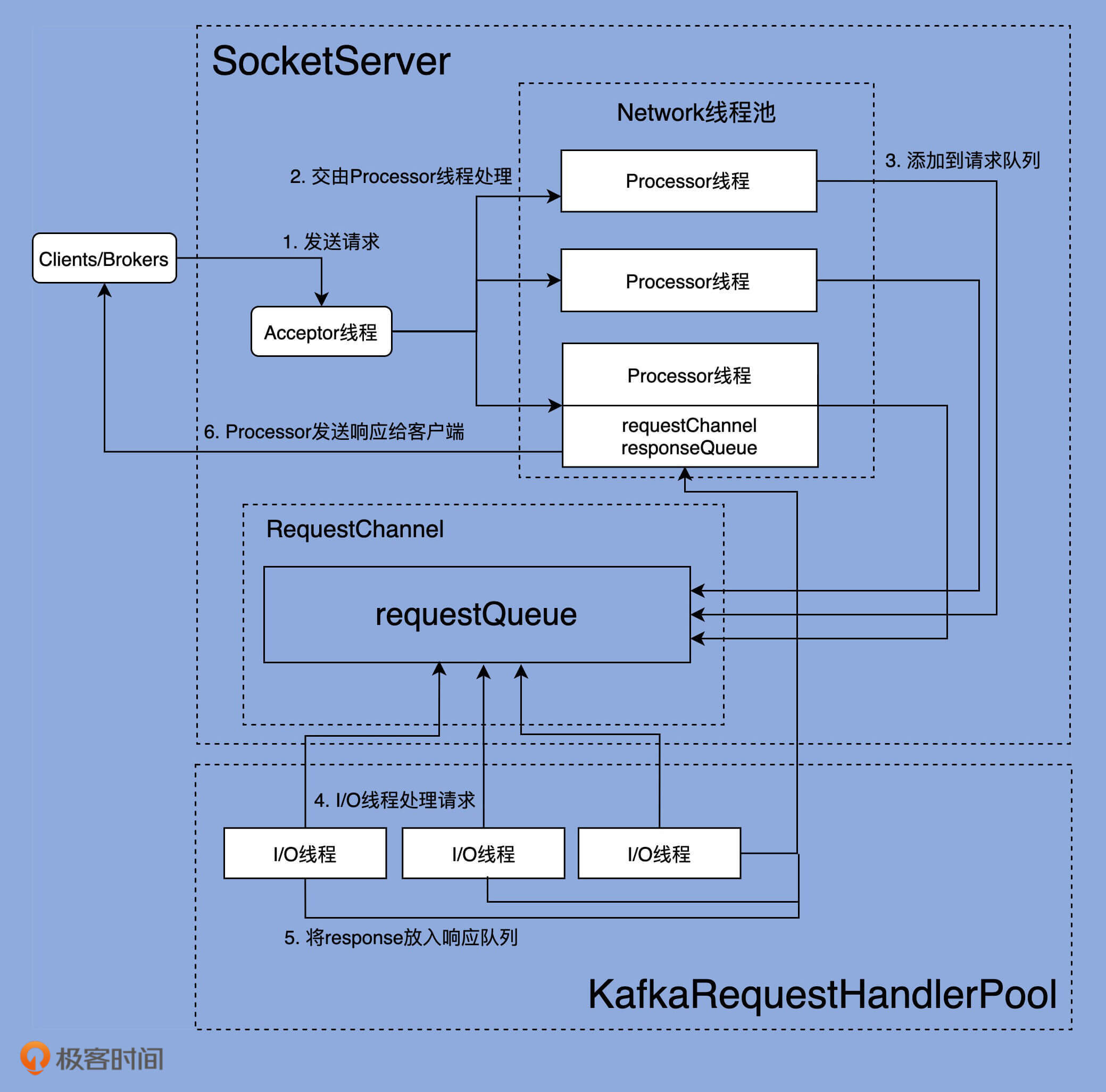
网络通信层
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

Kafka网络通信底层源码解析 本文深入解析了Kafka底层的NIO通信机制源码,重点关注了SocketServer和KafkaRequestHandlerPool组件。通过介绍Kafka的网络通信层架构和详细介绍SocketServer组件的运行逻辑,读者可以了解Kafka是如何应用NIO来实现网络通信的。文章还提供了Acceptor线程和Processor线程的源码分析,展示了它们在处理外部连接和请求分发方面的重要作用。此外,文章还包含了对于生产环境中调整参数的优化建议。 在文章中,我们深入了解了Kafka网络通信层的全貌,大致介绍了核心组件SocketServer,还花了相当多的时间研究SocketServer下的Acceptor和Processor线程代码。我们了解到网络通信层由SocketServer组件和KafkaRequestHandlerPool组件构成,SocketServer实现了Reactor模式,用于高性能地并发处理I/O请求,底层使用了Java的Selector实现NIO通信。 在下节课中,我们将重点介绍SocketServer处理不同类型Request所做的设计及其对应的代码,这是社区为了提高Broker处理控制类请求的重大举措,也是为了改善Broker一致性所做的努力,非常值得我们重点关注。 总的来说,本文通过深入解析Kafka底层的NIO通信机制源码,为读者提供了深入了解Kafka网络通信原理的机会。欢迎你在留言区畅所欲言,跟我交流讨论,也欢迎你把今天的内容分享给你的朋友。
《Kafka 核心源码解读》,新⼈⾸单¥59

全部留言(24)
- 最新
- 精选
 胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,咱们重点了解了Kafka中的请求通道:RequestChannel类。课后我让你去源码中寻找监控Request队列当前使用情况的监控指标。下面我给出我的答案。这个监控指标就是RequestQueueSize。完整的MBean写法是kafka.network:type=RequestChannel,name=RequestQueueSize。你可以在RequestChannel.scala中找到这行源码:newGauge(requestQueueSizeMetricName, () => requestQueue.size) 这里的requestQueueSizeMetricName就对应于RequestQueueSize okay,你找到了吗?我们可以一起讨论下。2020-05-065
胡夕置顶你好,我是胡夕。我来公布上节课的“课后讨论”题答案啦~ 上节课,咱们重点了解了Kafka中的请求通道:RequestChannel类。课后我让你去源码中寻找监控Request队列当前使用情况的监控指标。下面我给出我的答案。这个监控指标就是RequestQueueSize。完整的MBean写法是kafka.network:type=RequestChannel,name=RequestQueueSize。你可以在RequestChannel.scala中找到这行源码:newGauge(requestQueueSizeMetricName, () => requestQueue.size) 这里的requestQueueSizeMetricName就对应于RequestQueueSize okay,你找到了吗?我们可以一起讨论下。2020-05-065 每天晒白牙去年自己在工作中接触了 Kafka,然后写了篇网络层的源码分析(应该叫源码注释 + 画图) https://mp.weixin.qq.com/s/-VzDU0V8J2guNXwhiBEEyg
每天晒白牙去年自己在工作中接触了 Kafka,然后写了篇网络层的源码分析(应该叫源码注释 + 画图) https://mp.weixin.qq.com/s/-VzDU0V8J2guNXwhiBEEyg作者回复: 赞👍
2020-04-3010 Geek_d1cc4dRequest队列线程共享,这样不同线程的workload才不会发生倾斜,不然可能会发生一边的线程空闲,一边的线程队列满
Geek_d1cc4dRequest队列线程共享,这样不同线程的workload才不会发生倾斜,不然可能会发生一边的线程空闲,一边的线程队列满作者回复: 很有道理:)
2020-04-3026 在路上课后题思考: (1)Request 队列在被 IO 线程取走处理时不需要关心 Request 被哪个 IO 线程处理了。处理完放入到对应的 Response 队列就好。 (2)Response 队列是线程私有的,因为 Processor 管理着某一组 SocketChannel,SocketChannel 发出的某个 Request 处理完成后生成 Response 还需要在该 Processor Send 出去。 (3)如果 Response 设计成跟 Request 一样在共享队列中, Processor 需要主动去 take 出来,这时还需要判定对应的 SocketChannel 是否属于这个 Processor。 或者设计成 由一个专门的线程取分发给不同的 Processor。那还不如 IO 线程处理完直接发给不同的 Response 队列划算也没有锁的竞争。 表达的核心逻辑就是 :Processor 线程的 selector 注册了该线程所管理的一组 SocketChannel,收发请求只能由该 Processor 处理。所以由 Processor 管理独属的 Response 队列。
在路上课后题思考: (1)Request 队列在被 IO 线程取走处理时不需要关心 Request 被哪个 IO 线程处理了。处理完放入到对应的 Response 队列就好。 (2)Response 队列是线程私有的,因为 Processor 管理着某一组 SocketChannel,SocketChannel 发出的某个 Request 处理完成后生成 Response 还需要在该 Processor Send 出去。 (3)如果 Response 设计成跟 Request 一样在共享队列中, Processor 需要主动去 take 出来,这时还需要判定对应的 SocketChannel 是否属于这个 Processor。 或者设计成 由一个专门的线程取分发给不同的 Processor。那还不如 IO 线程处理完直接发给不同的 Response 队列划算也没有锁的竞争。 表达的核心逻辑就是 :Processor 线程的 selector 注册了该线程所管理的一组 SocketChannel,收发请求只能由该 Processor 处理。所以由 Processor 管理独属的 Response 队列。作者回复: 👍
2021-04-095 __Unsafe老师,想请教一个问题,kafka是如何处理nio 的 epoll空轮训bug的?
__Unsafe老师,想请教一个问题,kafka是如何处理nio 的 epoll空轮训bug的?作者回复: Kafka没做处理。毕竟不属于它应做的事情
2020-07-023 hc老师你好,我这边生产环境kafka0.10版本生产者偶然会出现kafka.common.FailedToSendMessageException: Failed to send messages after 3 tries的问题,问一下您这边有什么好的定位思路吗?
hc老师你好,我这边生产环境kafka0.10版本生产者偶然会出现kafka.common.FailedToSendMessageException: Failed to send messages after 3 tries的问题,问一下您这边有什么好的定位思路吗?作者回复: 看着像是非常古老的异常了。通常都是listeners配置或是clients的/etc/hosts配置的问题。总之是连不上Broker导致的
2020-05-2021 小崔为什么Clients 与 Broker 的通信网络延迟很大,建议调大缓冲区呢?背后原理是什么?
小崔为什么Clients 与 Broker 的通信网络延迟很大,建议调大缓冲区呢?背后原理是什么?作者回复: 如果RTT很大,我们最好是让Socket buffer累积更多的数据之后一次性发送,节省网络I/O带宽。就比如送快递,如果目的地很远,快递员最好先积攒多一点待发送的物件之后再去发送
2020-05-0721 咸老师您好,看过这块的网络模型后是不是可以理解为kafka的broker端采用的是reactor中的多线程模型,也就是说一个reactor负责网络上的链接,接收等操作,处理资源池是多个,负责读数据,处理业务(这里也就是放在队列里),这样理解对吗
咸老师您好,看过这块的网络模型后是不是可以理解为kafka的broker端采用的是reactor中的多线程模型,也就是说一个reactor负责网络上的链接,接收等操作,处理资源池是多个,负责读数据,处理业务(这里也就是放在队列里),这样理解对吗作者回复: 嗯嗯,是这样的
2021-08-28 Bryant.C老版本的response Queue好像确实是保存在requestChannel中,用processor id去索引的
Bryant.C老版本的response Queue好像确实是保存在requestChannel中,用processor id去索引的作者回复: 哈哈,这个要考证下了:)
2020-10-202
 长脖子树文中说: 每当 Processor 线程接收新的连接请求时,都会将对应的 SocketChannel 放入这个队列。后面在创建连接时(也就是调用 configureNewConnections 时),就从该队列中取出 SocketChannel,然后注册新的连接。 按照我的理解, tcp 三次握手是在 Acceptor 调用 accept() 完成之前就已经完成了的. 而并不是 processor 的工作. processor 的 configureNewConnections 方法只是将 已经建立的连接取出来再次注册 OP_READ 事件而已 老师怎么看? 大家有什么想法么?
长脖子树文中说: 每当 Processor 线程接收新的连接请求时,都会将对应的 SocketChannel 放入这个队列。后面在创建连接时(也就是调用 configureNewConnections 时),就从该队列中取出 SocketChannel,然后注册新的连接。 按照我的理解, tcp 三次握手是在 Acceptor 调用 accept() 完成之前就已经完成了的. 而并不是 processor 的工作. processor 的 configureNewConnections 方法只是将 已经建立的连接取出来再次注册 OP_READ 事件而已 老师怎么看? 大家有什么想法么?作者回复: 嗯嗯,你说的是对的。只是我们对于“创建连接”的定义可能不太一样。通常情况下,除了创建TCP连接,Kafka还需要创建所需的通道等对象,这在Kafka看来都是正常工作前的准备工作:)
2020-07-232

