

30 | 目标代码的生成和优化(二):如何适应各种硬件架构?
宫文学

该思维导图由 AI 生成,仅供参考
前一讲,我带你了解了指令选择和寄存器分配,本节课我们继续讲解目标代码生成的,第三个需要考虑的因素:指令重排序(Instruction Scheduling)。
我们可以通过重新排列指令,让代码的整体执行效率加快。那你可能会问了:就算重新排序了,每一条指令还是要执行啊?怎么就会变快了呢?
别着急,本节课我就带你探究其中的原理和算法,来了解这个问题。而且,我还会带你了解 LLVM 是怎么把指令选择、寄存器分配、指令重排序这三项工作组织成一个完整流程,完成目标代码生成的任务的。这样,你会对编译器后端的代码生成过程形成完整的认知,为正式做一些后端工作打下良好的基础。
首先,我们来看看指令重排序的问题。
指令重排序
如果你有上面的疑问,其实是很正常的。因为我们通常会把 CPU 看做一个整体,把 CPU 执行指令的过程想象成,依此检票进站的过程,改变不同乘客的次序,并不会加快检票的速度。所以,我们会自然而然地认为改变顺序并不会改变总时间。
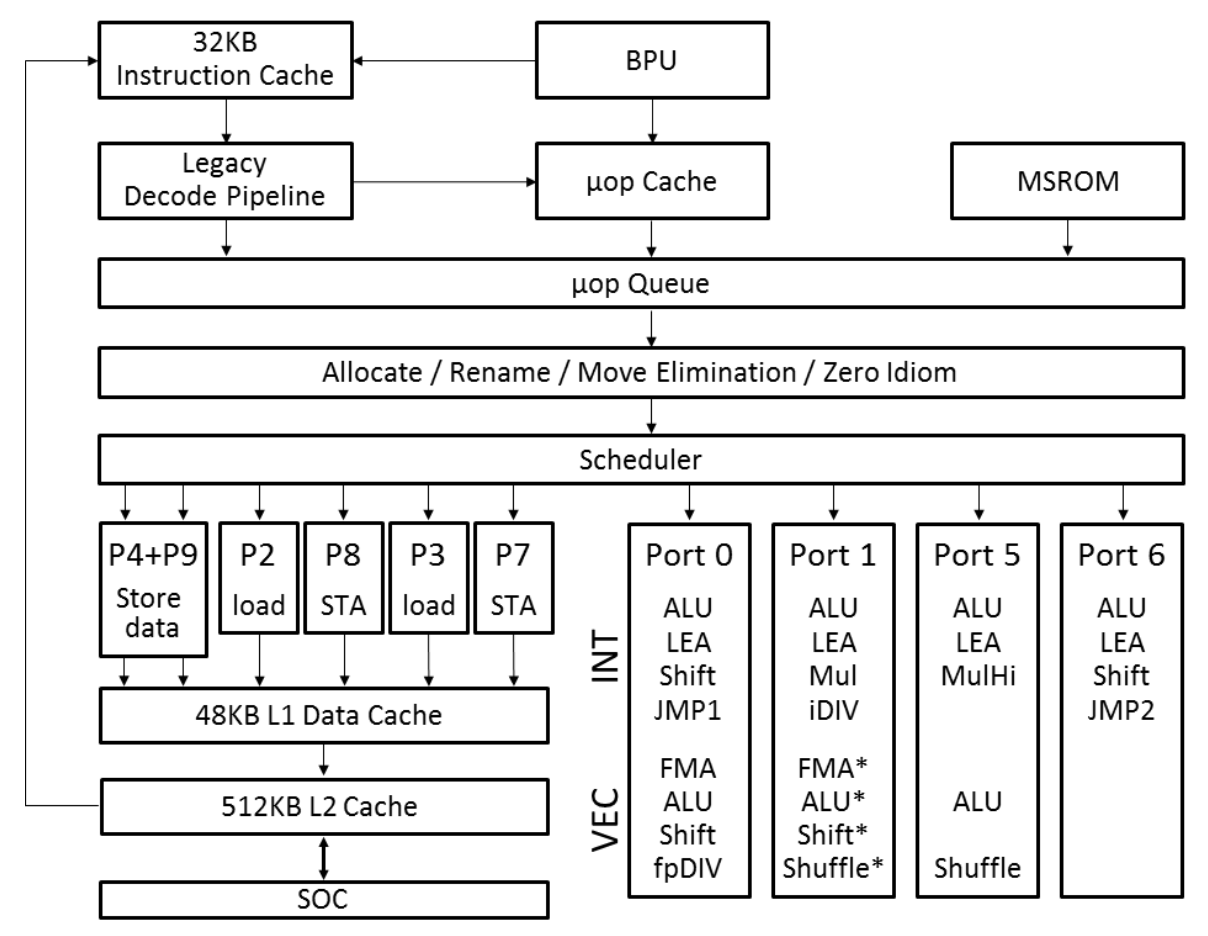
在这个结构中,一条指令执行时,要依次用到多个功能部件,分成多个阶段,虽然每条指令是顺序执行的,但每个部件的工作完成以后,就可以服务于下一条指令,从而达到并行执行的效果。这种结构叫做流水线(pipeline)结构。我举例子说明一下,比如典型的 RISC 指令在执行过程会分成前后共 5 个阶段。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

LLVM的目标代码生成和优化过程是本文的重点,特别关注了指令重排序对代码执行效率的影响。通过重新排列指令,可以提高代码的整体执行效率。文章详细介绍了LLVM如何组织指令选择、寄存器分配和指令重排序,完成目标代码生成的任务。指令重排序的原理和算法得到了详细讨论,包括流水线结构、指令级并行和数据依赖约束等概念。此外,文章还介绍了List Scheduling算法,并探讨了算法的复杂度。对于读者来说,本文对编译器后端的代码生成过程进行了深入的讲解,适合对编译器后端有一定了解的读者阅读。文章还提到了LLVM如何支持新的CPU架构,以及TableGen模块如何帮助快速生成后端,为读者提供了实用的技术知识。总的来说,本文内容丰富,涵盖了编译器后端的重要领域,对于对编译器技术感兴趣的读者具有一定的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《编译原理之美》,新⼈⾸单¥59
《编译原理之美》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(9)
- 最新
- 精选
 lion_flymark,一下,走到这里不容易,越是后面的内容,越觉得吸引人。
lion_flymark,一下,走到这里不容易,越是后面的内容,越觉得吸引人。作者回复: 没有人知道,其实你已经在静悄悄的成长。 成长,都是发生在远离喧嚣的时候:-)
2020-12-245 余晓飞LLVM 的指令选择算法是基于 DAG(有向无边图)的树模式匹配 括号里应该为“有向无环图”。
余晓飞LLVM 的指令选择算法是基于 DAG(有向无边图)的树模式匹配 括号里应该为“有向无环图”。作者回复: 多谢! 是的,文字有错误,马上修正!
2019-12-302 🐳正小歪我们可以给图中的每个节点再加上两个属性,利用这两个属性,就可以对指令进行排序了: 一是操作类型,因为这涉及它所需要的功能单元。 二是时延属性,也就是每条指令所需的时钟周期。 ----------------------------------------------- 老师,你好,请问下每条指令所需的时钟周期是固定的吗?
🐳正小歪我们可以给图中的每个节点再加上两个属性,利用这两个属性,就可以对指令进行排序了: 一是操作类型,因为这涉及它所需要的功能单元。 二是时延属性,也就是每条指令所需的时钟周期。 ----------------------------------------------- 老师,你好,请问下每条指令所需的时钟周期是固定的吗?作者回复: 通常来说,精简指令集(RISC)的每条指令,所需时钟周期是固定的。而复杂指令集(CISC)中,每条指令所需时钟周期就不太一样。具体可以去查CPU的手册。
2020-06-301 沉淀的梦想不太理解,为什么文中例子的指令重排序结果是a-c-e-b-d-g-f-h-i?b,d不是存在数据依赖吗?而且add的时钟周期为2,这么排应该会导致停顿啊
沉淀的梦想不太理解,为什么文中例子的指令重排序结果是a-c-e-b-d-g-f-h-i?b,d不是存在数据依赖吗?而且add的时钟周期为2,这么排应该会导致停顿啊作者回复: 我们在这个例子中,假设add的时钟周期是2。 这么排已经是总时钟周期最短的了。
2019-11-011 Giacomo后端比前端难了好多啊
Giacomo后端比前端难了好多啊作者回复: 前端有点偏纯逻辑。后端还需要了解计算机的架构等技术细节,客观上你需要考虑的东西更多一些。但这些基本上都是知识(比如汇编的写法)而已,学习的任务是加重了,但不见得难。因为你熟悉了就不难了。 真正难的还是算法。无论是前端的算法还是后端的算法。相比而言,本课程所涉及的后端算法反倒比前段算法更容易掌握,比如寄存器分配的算法。只不过后端涉及的技术细节更多。
2019-11-03 dllmark2022-07-27
dllmark2022-07-27- Someday根据时延属性,我们计算出了每个节点的累计时延(每个节点的累计时延等于父节点的累计时延加上本节点的时延) 这里把a后面标了13 ,b后面标了10,c后面标了12究竟是什么意思啊,怎么算出来的,没看懂啊2022-05-221
 ifelse
ifelse 都是新知识,收获满满2021-10-24
都是新知识,收获满满2021-10-24 皮皮侠“……能够帮助你为某个新的 CPU 架构快速生成后端。你可以用一系列配置文件定义你的 CPU 架构的特征,比如寄存器的数量、指令集等等。”,老师,关于这块可以推荐一些资料么?2021-10-17
皮皮侠“……能够帮助你为某个新的 CPU 架构快速生成后端。你可以用一系列配置文件定义你的 CPU 架构的特征,比如寄存器的数量、指令集等等。”,老师,关于这块可以推荐一些资料么?2021-10-17
收起评论

