

02 | 正则文法和有限自动机:纯手工打造词法分析器

该思维导图由 AI 生成,仅供参考
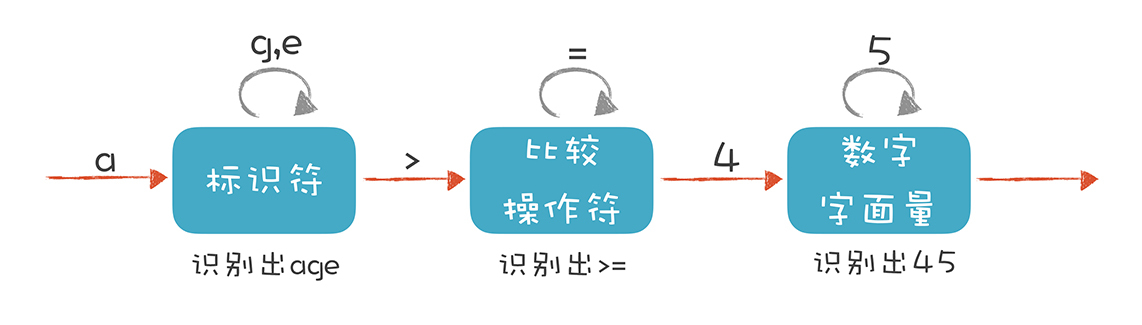
解析 age >= 45
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文详细介绍了如何通过纯手工打造一个词法分析器,通过讲解正则表达式和有限自动机的知识来解决这个问题。作者首先解析了一个关系表达式“age >= 45”,并提出了词法分析要用到有限自动机。然后详细描述了标识符、比较操作符和数字字面量这三种Token的词法规则,并构造了相应的有限自动机。接着,作者介绍了初识正则表达式,将词法规则用正则表达式表达,并解释了几种规则中用到的符号。最后,作者表示在后续课程中将带领读者用工具生成词法分析器,而工具读取的就是用正则表达式描述的词法规则。整体来看,本文通过实例和代码示例生动地介绍了词法分析的原理和实现过程,为读者提供了一种纯手工打造词法分析器的方法。文章内容涵盖了词法分析器的原理、正则表达式和有限自动机的应用,对于想要深入了解词法分析的读者来说,是一篇值得阅读的技术文章。
《编译原理之美》,新⼈⾸单¥59

全部留言(102)
- 最新
- 精选
- KnowNothing老师,在关键字和保留字的识别上,我认为有不需要加入中间状态的更简单的方式: 完成词法分析后,遍历所有ID token,如果其text在关键字和保留字集合内,将该token类型改成对应的关键字/保留字类型。 或者, 每当识别出一个ID token,都检查其text,如果是在关键字和保留字集合内,纠正type。
作者回复: 没错,可以的。 但是构造成有限自动机的话,程序就可以标准化处理。不需要再手写其他代码。比如正则表达式工具。 当然,如果纯手写词法分析器,不受任何标准算法的限制的话,那发挥空间就会大很多。 爱动脑的好同学!
2019-08-161463  傲娇的小宝感觉有限状态机有点类似图灵机的工作方式。我一般只用正则匹配一下文件名或者某个字符串是否符合我的预期。
傲娇的小宝感觉有限状态机有点类似图灵机的工作方式。我一般只用正则匹配一下文件名或者某个字符串是否符合我的预期。作者回复: 有限自动机是比较简单的一种自动机,对应于正则文法,也叫做3型文法。 比它强大的是下推自动机,对应于上下文无关文法,也叫做2型文法。 比它更强大的是线性有界自动机,对应于上下文相关文法,也叫1型文法。 图灵机的范围比它们都大,它对应0型文法。你任何能用产生式写出来的文法规则,都属于0型文法。 希望对你有帮助,了解有限自动机和图灵机的关系:)
2019-08-18261 易林林宫老师,例子里面的词法分析大多是靠条件判断来实现,如果对一门完整的语言来进行分析的话,工作量会不会很大。我在想,是否有其他方式可以实现?
易林林宫老师,例子里面的词法分析大多是靠条件判断来实现,如果对一门完整的语言来进行分析的话,工作量会不会很大。我在想,是否有其他方式可以实现?作者回复: 课程的示例代码的主要目的是把意思讲明白,我甚至把状态都用枚举表示,就是为了易读。性能不是第一考虑。 从性能的角度,词法分析可以用查表的方法实现状态迁移。在每个状态,接收什么字符,切换到另外的状态。那样更快,这是常用的方法。 不光词法分析可以这么做,语法分析也可以。基于表驱动。这时候,最重要的是构造那张表。代码的话,就不大看明白是啥意思。
2019-08-1750 Fan宫老师,有没有一些词法分析的demo可以推荐看看呢?
Fan宫老师,有没有一些词法分析的demo可以推荐看看呢?作者回复: 最好的demo,就是现有语言的词法分析器,比如Java的、GNU c的,都能拿到源代码。比如Java的编译器在JDK的源代码里就有。 此外,我们在后端时会讲到LLVM工具。LLVM的文档里有一个小的教程,做了一个完整的前端。你也可以参考一下。http://llvm.org/docs/tutorial/MyFirstLanguageFrontend/LangImpl01.html 回头我整理一份清单放到github上,告诉大家去哪里下载。你的需求估计其他同学也有。 谢谢你!
2019-08-16231 逗逼师父老师您好,我的疑问是,age>=45的有限状态机图中,为什么比较操作符不像标识符那样停留在同一个状态?我觉得>和>=都是属于比较操作符呀
逗逼师父老师您好,我的疑问是,age>=45的有限状态机图中,为什么比较操作符不像标识符那样停留在同一个状态?我觉得>和>=都是属于比较操作符呀作者回复: 很好的问题。 是这样的。从Token分类的角度,我们确实可以把这两个归为一类。 但如果把它们看做同一个状态,就会有一些问题。比如,接收到=号应该怎么处理呢?接收第一个=号,仍然处于比较操作符状态。那么接收第二个呢?问题是,有限状态机接收字符的时候,是没法数个数的。如果你要记个数,也就相当于在内部新增加了一个状态,还是等价于两个状态。我这么说你理解吗?
2019-08-17522 宋健老师,我写完这一节激动的浑身发抖,自己果然实现了一个简单的词法分析器!老师讲得太棒了!
宋健老师,我写完这一节激动的浑身发抖,自己果然实现了一个简单的词法分析器!老师讲得太棒了!作者回复: 主要是你自己的功劳:) 在技术领域,有时候你会觉得某个领域高山仰止,其实你自己也可以成为高山上的一棵青松。知识这东西,就在那里,只要想学,没有可能学不会。一旦学会,没有可能再变得不会,是个只会增加的过程,这是多便宜的事情! 不过,学习过程中,肯定还是会遇到挫折的,会觉得难懂,会觉得坚持不下去。这也没关系。你吃的苦越多,进入的境界就越高,这都是值得的!
2020-03-2420 诺亚isAlpha 的 alpha 好像没有字母的意思吧?用 alphabet 会不会比较合适点?
诺亚isAlpha 的 alpha 好像没有字母的意思吧?用 alphabet 会不会比较合适点?作者回复: 你很细心,所以我也仔细给你解答下:-) isAlpha是 is alphabetic 的缩写。isalpha()函数是好几个语言的标准库里都提供的,比如C、python等。 alphabet指的是整个字母表,不是字母表里的单个字母。
2019-08-25220 (╯‵□′)╯︵┻━┻有回随手发现Google搜索可以使用正则表达式……然后感觉星星都亮了
(╯‵□′)╯︵┻━┻有回随手发现Google搜索可以使用正则表达式……然后感觉星星都亮了作者回复: 嗯。等你学了算法篇第16讲,了解了正则表达式的机制后,可以设计点正则表达式测试一下谷歌的性能,看看能否把谷歌的服务器累趴下...
2019-10-0315- 请叫我赓哥您好,老师,初步接触编译原理,您讲的手工打造词法分析,是用已知的java或c或其他语言实现,我想问一下,c语言的编译器是用什么实现的呢,或者其他语言的编译器?另外其他的词法分析器又是用什么语言编写的呢,谢谢
作者回复: 在编译领域,有一个事情,叫做自举(bootstraping),也就是这门语言的编译器可以用自己这门语言编写。这是语言迈向成熟的标志。一般前面的版本,是要借助别的语言编写编译器,但后面就应该用自己的语言来编译了。 著名的语言都实现了自举。比如,go语言的编译器是用go编写的(早期版本应该是用C语言写的编译器。能实现自举,还是go发展历程上的一个历程碑),jdk里面自带了java语言的编译器,本身也是用java写的。 更早的语言,那当然是用汇编写编译器。比尔盖茨当年就是用汇编写。 掌握编译原理之后,其实用什么语言都可以写。 这门课程的示例语言是playscript。我有计划后面把playscript实现自举。
2019-08-28215 
 梓航(﹏)我是来提意见的,麻烦老师在讲示例的时候,把对应的github链接贴上,而不是在最后贴一个总的地址,我点进去一脸懵,哪个文件对应哪个例子啊?
梓航(﹏)我是来提意见的,麻烦老师在讲示例的时候,把对应的github链接贴上,而不是在最后贴一个总的地址,我点进去一脸懵,哪个文件对应哪个例子啊?作者回复: 好的,谢谢您提意见!已通知后台调整一下。 02课的文件是目录中的SimpleLexer.java文件。 另,如果到github的https://github.com/RichardGong/PlayWithCompiler项目主页,里面有每堂课的课件的介绍,供您参考。
2019-08-1715

