

01 | 理解代码:编译器的前端技术

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

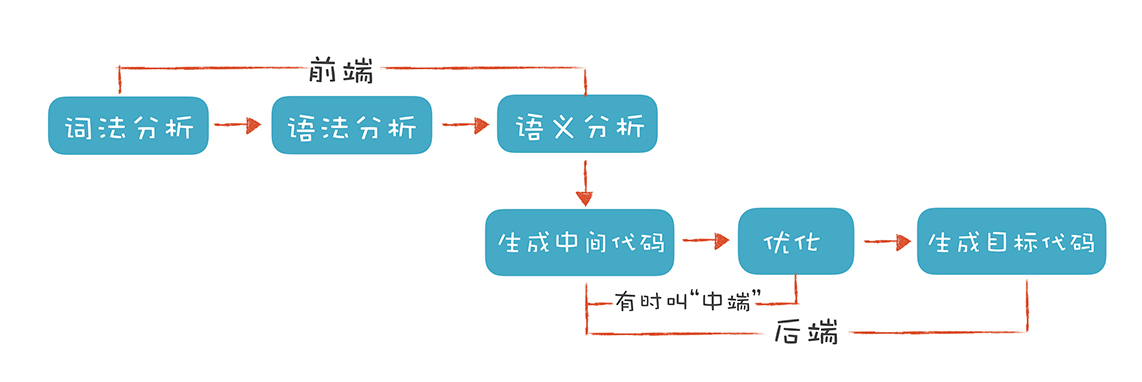
编译器前端技术包括词法分析、语法分析和语义分析,对程序代码的分析和理解至关重要。词法分析通过识别Token将程序代码分解成基本单元,类似于汉语的分词。语法分析在此基础上识别程序的语法结构,构造抽象语法树(AST)。语义分析消除语义模糊,生成属性信息,让计算机生成目标代码。递归下降算法是一种常用的语法分析算法,而语义分析基本上就是根据语义规则进行分析判断。这些编译过程的核心原理是容易理解的,学习之后读者能够快速上手,善用辅助生成工具会更省事。文章通过通俗易懂的语言和实际使用场景,帮助读者直观地理解词法分析的重要性和实现方法。对于从事软件开发、编程语言设计以及编译器开发的读者具有实际应用价值。
《编译原理之美》,新⼈⾸单¥59

全部留言(134)
- 最新
- 精选

 梓航(﹏)程序的某个地方写错了,比如某个关键词拼错,少逗号,分号等,是在哪一个阶段发现的呢?
梓航(﹏)程序的某个地方写错了,比如某个关键词拼错,少逗号,分号等,是在哪一个阶段发现的呢?作者回复: 在各个阶段都会发现一些错误。 在词法分析阶段,可能会发现某些输入不符合我们的任何一条词法规则。 关键词拼错,在词法分析阶段是发现不出来的,它会被识别成一个标识符。比如inta, 假设是笔误,少了空格,也是一个合法的标识符。 在语法分析阶段,你说的少逗号,分号什么的,这些错误在语法分析阶段就可以识别出。因为不满足语法规则。 还有一些必须要等到语义分析阶段才能发现错误。比如 inta=10; 语法是没错的。 但我们真正想写的是: int a = 10; 在语义检查的时候,对第一句就会检查出,之前并没有声明inta这个变量。所以可能是错误。 不知道是否解答了你的疑问。在后面的课程例子中,我们会做出错处理。
2019-08-162205 coder我做过一款已经投入商用的编译器,从编译器的前端到中端的优化,再到后端针对某个特定architecture的代码生成以及优化,完整地趟过一遍,编译器的实现是基于clang和llvm的,目前的感觉是,工程经验确实积累了不少。antlr,flex,bison等这些工具也都用过。所以在看到课程目录时,感觉比较熟悉,目录中提到的东西都是知道的。 但是我目前的感觉是,自己在理论方面的积累还是有些欠缺的,那些PL相关的理论也同样重要,包括图灵机,状态机,计算模型,lambda演算,类型和类型系统等,所以希望老师也能够也讲一下这部分理论🌝🌝🌝
coder我做过一款已经投入商用的编译器,从编译器的前端到中端的优化,再到后端针对某个特定architecture的代码生成以及优化,完整地趟过一遍,编译器的实现是基于clang和llvm的,目前的感觉是,工程经验确实积累了不少。antlr,flex,bison等这些工具也都用过。所以在看到课程目录时,感觉比较熟悉,目录中提到的东西都是知道的。 但是我目前的感觉是,自己在理论方面的积累还是有些欠缺的,那些PL相关的理论也同样重要,包括图灵机,状态机,计算模型,lambda演算,类型和类型系统等,所以希望老师也能够也讲一下这部分理论🌝🌝🌝作者回复: 看来我要跟你学习才对:) 这门课是实战和原理并重。但在设计上,会先让同学们建立对编译的直观感受,然后再引导到对算法的兴趣上。所以,在前端部分,我把算法的总结和提升放到了最后部分。因为这个时候,大家都已经没有陌生感、恐惧感了,学算法也就顺理成章了。 你的经验已经比大部分同学多。我也争取把理论这部分也在课程里搞好!
2019-08-1412108 公众号:业余草BAT为什么没有造出一门语言的轮子?
公众号:业余草BAT为什么没有造出一门语言的轮子?作者回复: 首先呢,编译原理不仅仅是造大家通用的语言。有很多是用来解决领域问题的。比如,好像阿里内部就有一个语言,叫cava,是跟它的搜索引擎配合的。 其次,我们做这些底层平台的时候,都要涉及编译。还是拿阿里的druid开源项目说事,它就手写了一个高速的sql parser。其他几家大的互联网公司肯定也有不少这种应用。 华为的方舟编译器,不是也很争气吗?有人说它没有多少创新,但它就是效果显著呀。 我跟大家一样,都期盼带有中国血统的、全球人都用的语言诞生出来。我相信时间不远了。这种事情需要技术底蕴,更重要的是需要产业发言权。这方面,我们是越来越强了!大家一起期盼!
2019-08-15670 Simon之前基于ANTLR给游戏策划做了一套dsl 战斗技能解析器,策划只要在文件中配置技能的效果就行,战斗的时候根据配置的表达式去解析并计算伤害啥的。感觉策划们用的很爽,新增加技能或者修改技能效果再也不用找开发了。开发感觉更爽。😀️😀️
Simon之前基于ANTLR给游戏策划做了一套dsl 战斗技能解析器,策划只要在文件中配置技能的效果就行,战斗的时候根据配置的表达式去解析并计算伤害啥的。感觉策划们用的很爽,新增加技能或者修改技能效果再也不用找开发了。开发感觉更爽。😀️😀️作者回复: 对的,做DSL能够给具体的领域带来很大的帮助!感谢你分享游戏领域的经验! 我知道游戏领域有人在做DSL,我对这个领域不太了解。马云也曾经参观国外的一个游戏公司,发现他们把平台做的很好,能够支持很多游戏的快速研发。他回来以后,在阿里提了中台的概念,目前在企业应用领域很流行。中台呀,游戏平台呀,编译原理都能发挥作用。
2019-08-14754 William分析一下自己做得一些摘录。 trick: mac 下的 clang命令可以编译C语言代码。 术语: 正则文法 最普通、最常见的规则 有限自动机 有限个状态的自动机器 词法分析 lexical analysis -> 分词 * 实现原理:有限自动机 * 现成的词法分析工具:Lex、GNU Flex 语法分析 parser -> 根据语法规则识别出程序的语法结构 (抽象语法树AST) * 需要考虑优先级等等 * 递归下降方法 * 现成的语法分析工具:Yacc、GNU Bison、Antlr、JavaCC 语义分析 semantic analysis -> 上下文分析、消除歧义 * 变量引用消解、作用域 * 合法性检查 * 数据类型标识 * 语义分析的某些结果,会作为属性标注在AST上
William分析一下自己做得一些摘录。 trick: mac 下的 clang命令可以编译C语言代码。 术语: 正则文法 最普通、最常见的规则 有限自动机 有限个状态的自动机器 词法分析 lexical analysis -> 分词 * 实现原理:有限自动机 * 现成的词法分析工具:Lex、GNU Flex 语法分析 parser -> 根据语法规则识别出程序的语法结构 (抽象语法树AST) * 需要考虑优先级等等 * 递归下降方法 * 现成的语法分析工具:Yacc、GNU Bison、Antlr、JavaCC 语义分析 semantic analysis -> 上下文分析、消除歧义 * 变量引用消解、作用域 * 合法性检查 * 数据类型标识 * 语义分析的某些结果,会作为属性标注在AST上作者回复: 记得这么认真! Great!
2019-08-1426 Rockbean想起标识符的命名为什么不能用数字开头,扫描到了数字,立马认为这个token是数字,不作标识符处理了
Rockbean想起标识符的命名为什么不能用数字开头,扫描到了数字,立马认为这个token是数字,不作标识符处理了作者回复: 对的。 如果允许数字开头的标识符,处理起来要麻烦一点。但也不是不可以。改一改本文的有限自动机应该也能实现。
2019-08-1522 Mr.J老师好,词法分析好理解一些,即程序识别出每个词汇,语法分析这个,拆分AST,打个比方,一个java代码: class A { int a = 2; boolean = false; } 语法分析时,把这个拆分AST,比如,遇到class,定义为根节点,两个关键字int 和boolean为两个子节点,每个子节点下面继续拆分,可以这样理解不,一条完整的java代码,就是从最后一个自己点一直向上到某个节点? 语义分析这个是在整个上下文中去进行的,定了全局变量a,在方法中使用a时,能够知道这个是在全居中定义过的那个a?
Mr.J老师好,词法分析好理解一些,即程序识别出每个词汇,语法分析这个,拆分AST,打个比方,一个java代码: class A { int a = 2; boolean = false; } 语法分析时,把这个拆分AST,比如,遇到class,定义为根节点,两个关键字int 和boolean为两个子节点,每个子节点下面继续拆分,可以这样理解不,一条完整的java代码,就是从最后一个自己点一直向上到某个节点? 语义分析这个是在整个上下文中去进行的,定了全局变量a,在方法中使用a时,能够知道这个是在全居中定义过的那个a?作者回复: 你大的概念理解完全正确。 这个类语法分析后会变成一棵树。像这样的语法,解析起来是很简单的。反倒是像表达式这样看似很简单的语法,解析起来反倒有难度。在后面的课程里会深入到细节。 语义分析的关键点你也抓住了,就是上下文。语法阶段是上下文无关的,语义阶段则专门处理上下文。 加油!
2019-08-15415 Fan希望后面有具体的一些demo
Fan希望后面有具体的一些demo作者回复: 有的,有很多demo。这门课不是纯讲理论,而是拿实操带动我们学理论。 第一节课是前端技术的概述。第二节就开始做例子了!示例代码到时候也释放出来。
2019-08-1414 Benjamin词法分析说白了就是分词,但是这个分词和搜索引擎中的分词不太一样,每种编程语言的语法规则是确定的,相应的词法规则也是确定的,不需要考虑太多上下文中的东西。这一步能够检查出不满足词法规则的错误。 语法分析的是和具体编程语言最相关的一步,能根据语法规则将词法分析的结果组装成一棵抽象语法树,以便于计算机处理。这一步走完,这个程序的整个语法结构就出来了。但是语法分析仅仅是检查语法,其输出结果也是一个半成品,类比中文的“我想静静”中的“静静”是谁还没有确定下来。 语义分析处理语法分析出来的半成品,丰富抽象语法树每个节点的内容,根据上下文确定每个节点的“具体含义”,确定不了的就报编译错误了。
Benjamin词法分析说白了就是分词,但是这个分词和搜索引擎中的分词不太一样,每种编程语言的语法规则是确定的,相应的词法规则也是确定的,不需要考虑太多上下文中的东西。这一步能够检查出不满足词法规则的错误。 语法分析的是和具体编程语言最相关的一步,能根据语法规则将词法分析的结果组装成一棵抽象语法树,以便于计算机处理。这一步走完,这个程序的整个语法结构就出来了。但是语法分析仅仅是检查语法,其输出结果也是一个半成品,类比中文的“我想静静”中的“静静”是谁还没有确定下来。 语义分析处理语法分析出来的半成品,丰富抽象语法树每个节点的内容,根据上下文确定每个节点的“具体含义”,确定不了的就报编译错误了。作者回复: 变成了自己的理解,很好!
2019-12-0713- Rockbean请教老师,AST可不可以转成可视化UML
作者回复: 我刚好研究过UML和MDA。 UML是对世界的建模。我们普通的程序也是对世界的建模。所以,这两者之间应该是可以互相翻译的。就像一门高级语言可以翻译成另一门高级语言。 我记得之前有一个方向,就是建好UML模型之后,程序自动生成。在这个意义上,UML就是一门计算机语言。
2019-08-15411

