

18 | 移进和规约:用LR算法推演一个实例

该思维导图由 AI 生成,仅供参考
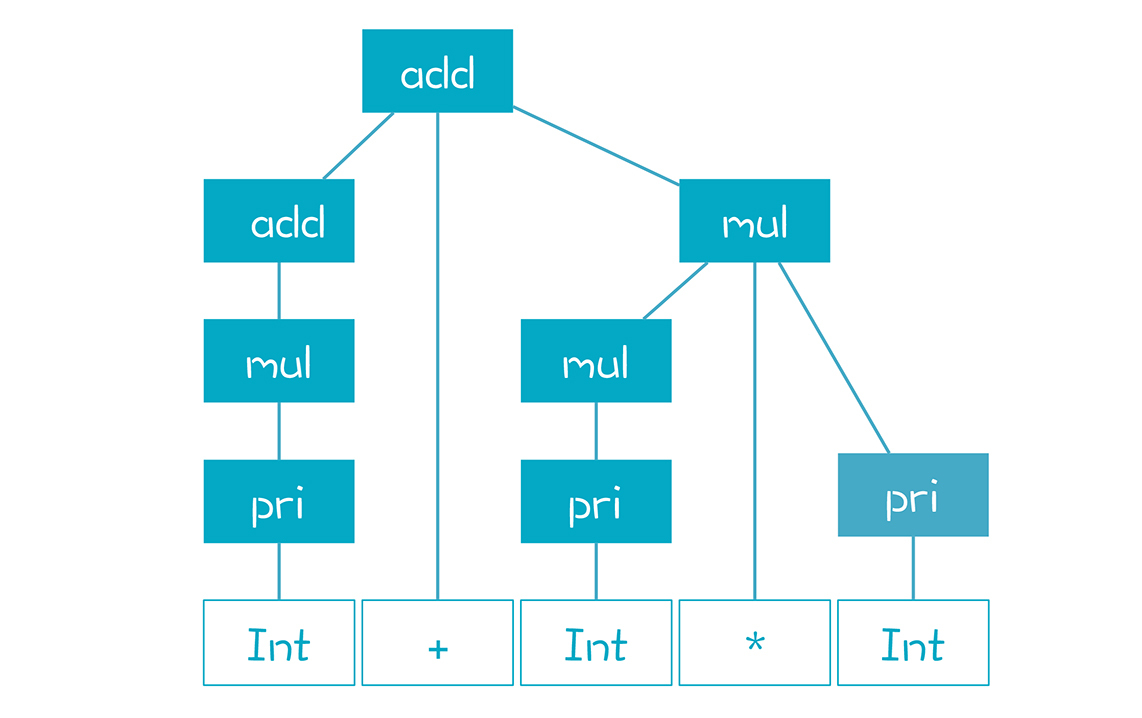
通过实例了解自底向上语法分析的过程
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

LR算法是一种自底向上的语法分析算法,通过移进-规约方法逐步构造AST完成语法解析。本文详细介绍了LR算法的原理和类型,包括LR(0)、SLR(k)、LALR(k)和LR(k)等级别的算法特点和实现细节。文章强调了句柄的重要性,即产生式的右边部分及其在句型中的位置,以及如何通过句柄做出正确的选择。LR算法要解决的核心问题是如何找到正确的句柄。通过实例生动地展示了LR算法的实际运用,为读者提供了深入理解自底向上语法分析的方法和原理的实用指南。此外,文章还介绍了LR算法的类型和实现细节,建议读者多做推导练习,以建立直觉认知。LR算法的特点和实际应用使得本文成为一份有价值的技术指南。文章还提到LR算法的缺点和改进,以及对于LR算法的思考和应用。
《编译原理之美》,新⼈⾸单¥59

全部留言(12)
- 最新
- 精选
 沉淀的梦想既然LALR(1)有性能低的缺点,那为什么yacc和bison还使用它呢?用yacc和bison生成的语法分析器性能差的话,为什么还有这么多人用?
沉淀的梦想既然LALR(1)有性能低的缺点,那为什么yacc和bison还使用它呢?用yacc和bison生成的语法分析器性能差的话,为什么还有这么多人用?作者回复: LALR(1)比LR(1)的性能要高。实际上,它是LR家族中比较优秀的一个算法了,所以实用度已经比较高,这也是yacc和bison用它的原因。 我再看看文稿,是不是我有什么地方表达得不清楚,引起了你的误解。 另外,我补充几点: 1.就算是LR(1)算法,在处理现代语言的一些语法特征时(泛型、Lamda等),也会产生很多冲突(移进-规约冲突,规约-规约冲突)。所以,用yacc和bison,可以支持实现比较简单的语法,但到了更加复杂的语法,就不够了。 2.GLR是很多人关注的一个LR家族的算法,具有处理冲突的能力。 3.我们课程中讲的单一的算法,无论是LL的还是LR的,在处理复杂的语法时都不够。有语法处理能力的原因,也有处理错误信息方面的考虑。所以,生产环境中支持比较复杂语法的编译器,都不会这么的单线条。GCC之前用过LALR,现在改为纯手写的基于递归下降的(如果我没记错的话...)了。
2019-09-254- minghu6用Rust写了一个完整demo: https://bitbucket.org/minghu6code/alg-parser/src/master/
作者回复: 我的bitbucket账号不允许看你的页面。 “We can't let you see this page”... 奇怪!
2021-05-2632  余晓飞start -> exp exp -> lvalue = rvalue exp -> rvalue lvalue -> Id lvalue -> *rvalue rvalue -> lvalue 对这里最后两行的产生式不太理解,请问有对应哪种具体语言的语法吗?
余晓飞start -> exp exp -> lvalue = rvalue exp -> rvalue lvalue -> Id lvalue -> *rvalue rvalue -> lvalue 对这里最后两行的产生式不太理解,请问有对应哪种具体语言的语法吗?作者回复: C语言。 左值,代表可以放在赋值符号左边的值,在编译器内部,要把它解析成一个地址,这样才能修改值。 右值,就是一般意义上的值,比如一个整形字面量。 "a = 10 * 2;" 这个表达式中,a是左值,编译器会把它编译成一个内存地址(或寄存器),而10、2、10*2都是右值。 lvalue -> *rvalue : 是取某个右值的地址,也就是一个指针。通过这个指针,可以改变其值。 rvalue -> lvalue:意思是左值是可以用在需要右值的地方(但反过来是不行的)。
2019-11-032 ZYS宫老师这个课件做的真棒👍,GCC语法分析用的是LR分析器么?Clang用的是什么语法分析器
ZYS宫老师这个课件做的真棒👍,GCC语法分析用的是LR分析器么?Clang用的是什么语法分析器作者回复: GCC用过LR,后来用手写的递归下降算法取代了。Clang也是用的手写的递归下降算法。 这说明,递归下降算法真的还是很有实用价值的:-) 用手写代码的好处,是随时可以Hack。就像我们在解决手写实现左结合的时候,就是在做hack。
2019-09-2321 Amy一个小typo: LR 算法中的 R,带有反向(Reverse)和最右(Reightmost)这两层含义。 s/Reightmost/Rightmost
Amy一个小typo: LR 算法中的 R,带有反向(Reverse)和最右(Reightmost)这两层含义。 s/Reightmost/Rightmost作者回复: 收到!感谢!我让小编同学改一下!
2021-08-04 lion_flymark一下,算法篇趟过去了
lion_flymark一下,算法篇趟过去了作者回复: 算法部分会有点抽象。多用图形化的方法做实例的推演,有助于你深入理解编译器的运行机制。
2020-11-032- 飞翔老师,不理解第 13 步,根据“add->add+mul”规约到 add 为什么会回到状态 2 状态2中“add->add.+mul”点号不是在中间吗,状态1的点号在开始
作者回复: 用状态2中的第一个产生式:start->add.
2019-10-17  xiaobang这一章看的有点困难,不理解那个NFA怎么来的
xiaobang这一章看的有点困难,不理解那个NFA怎么来的作者回复: 那个NFA表达了在做正向推导的时候,可能采取的所有可能的推导路径。用了Item这种方式表达出来了而已。 你按照我这种说法看看,是不是那个NFA就代表了示例的语法的推导路径。 把这一关过了,转DFA的过程你肯定是理解的。
2019-09-253 locke.wei在状态 2,如果下一个输入是“=”,那么做移进和规约都是可以的。因为“=”在 rvalue 的 Follow 集合中。 这里我理解"="应该是lvalue的follow集合?2020-05-096
locke.wei在状态 2,如果下一个输入是“=”,那么做移进和规约都是可以的。因为“=”在 rvalue 的 Follow 集合中。 这里我理解"="应该是lvalue的follow集合?2020-05-096
 温雅小公子把follow集合拆解是怎么做的?2022-10-10归属地:河北1
温雅小公子把follow集合拆解是怎么做的?2022-10-10归属地:河北1

