腾讯大规模分布式机器学习系统无量是如何进行技术选型的?
张红林

导读: 在互联网场景中,亿级的用户每天产生着百亿规模的用户数据,形成了超大规模的训练样本。如何利用这些数据训练出更好的模型并用这些模型为用户服务,给机器学习平台带来了巨大的挑战。腾讯开发了一个基于参数服务器架构的机器学习计算框架——无量框架,已经能够完成百亿样本 / 百亿参数模型的小时级训练能力。无量框架提供多种机器学习算法,不但能进行任务式的离线训练,还能支持以流式样本为输入的 7*24 小时的在线训练。
1. 背景
QQ 浏览器首页的推荐 Feeds 流。业务入口如图所示:
图 1 QB Feeds 流业务
浏览器的 Feeds 业务每天的流点击曝光日志在百亿级;为了更好的给用户提供个性化的推荐服务,如果我们取半个月的数据来训练推荐模型的话,则我们会面对一个千亿样本的状况。
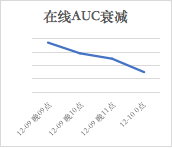
图 2 模型在线表现的时间衰减曲线
此外,对一个训练好的模型,我们观察了模型在线的指标变化,如图所示。这个图说明我们的 Feeds 流业务是一个时效性高度敏感的业务,在线用户访问的规律实时在变化,要取得最好的业务效果,我们必须不断及时的更新模型。浏览器另一个业务——识花君,需要用百万级图片预训练一个多分类的图片分类模型,如果采用单机单卡的模式,大约需要半个月才能训练一个收敛的模型;如果使用 TensorFlow 的分布式训练也大概需要一周,有没有更高效的方法呢?
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论