

14 | 进程数据结构(下):项目多了就需要项目管理系统
刘超

该思维导图由 AI 生成,仅供参考
上两节,我们解读了 task_struct 的大部分的成员变量。这样一个任务执行的方方面面,都可以很好地管理起来,但是其中有一个问题我们没有谈。在程序执行过程中,一旦调用到系统调用,就需要进入内核继续执行。那如何将用户态的执行和内核态的执行串起来呢?
这就需要以下两个重要的成员变量:
用户态函数栈
在用户态中,程序的执行往往是一个函数调用另一个函数。函数调用都是通过栈来进行的。我们前面大致讲过函数栈的原理,今天我们仔细分析一下。
函数调用其实也很简单。如果你去看汇编语言的代码,其实就是指令跳转,从代码的一个地方跳到另外一个地方。这里比较棘手的问题是,参数和返回地址应该怎么传递过去呢?
我们看函数的调用过程,A 调用 B、调用 C、调用 D,然后返回 C、返回 B、返回 A,这是一个后进先出的过程。有没有觉得这个过程很熟悉?没错,咱们数据结构里学的栈,也是后进先出的,所以用栈保存这些最合适。
在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构,也就是上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
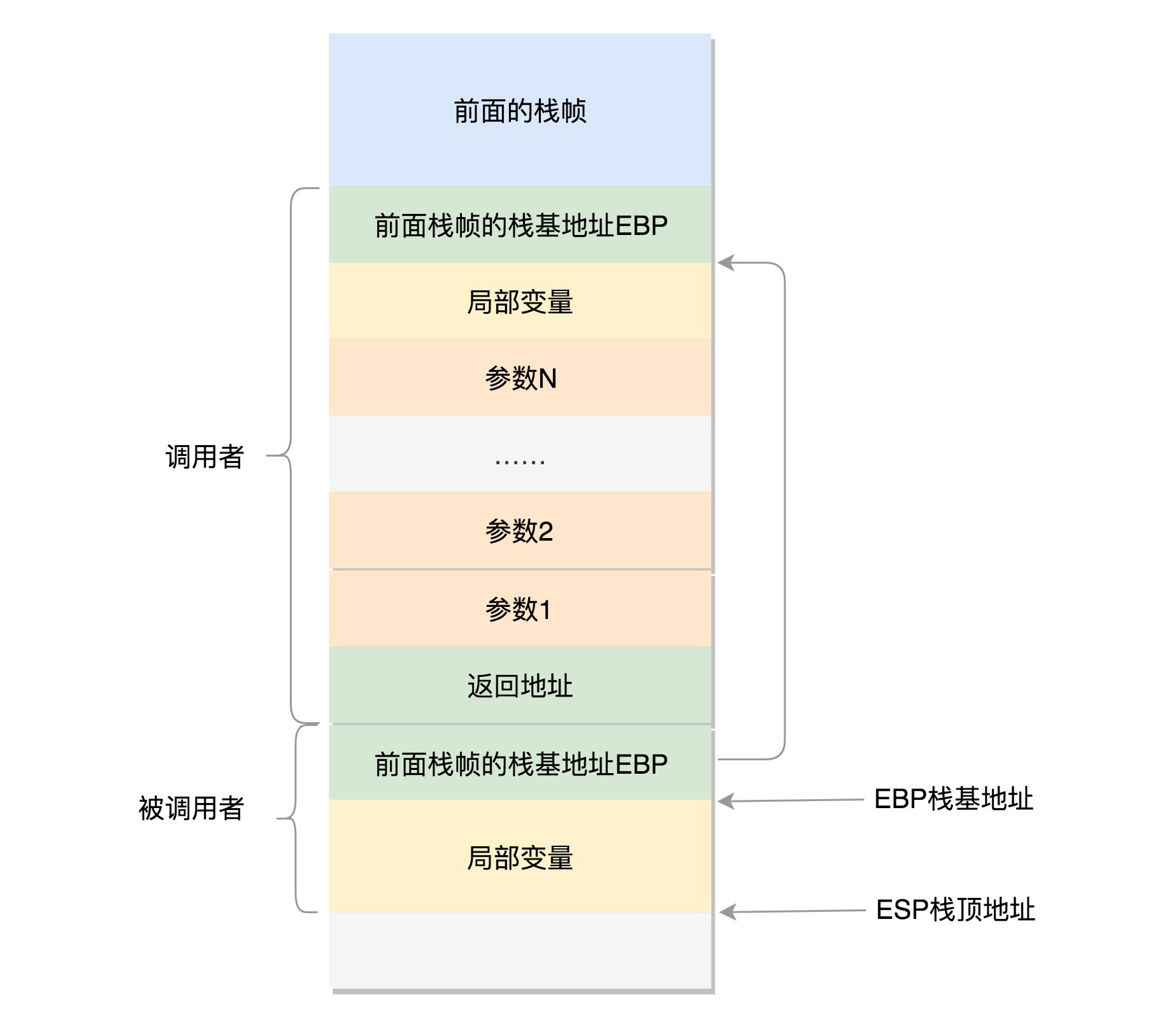
我们先来看 32 位操作系统的情况。在 CPU 里,ESP(Extended Stack Pointer)是栈顶指针寄存器,入栈操作 Push 和出栈操作 Pop 指令,会自动调整 ESP 的值。另外有一个寄存器 EBP(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了进程数据结构中的用户态函数栈和内核态函数栈的相关内容,包括32位和64位操作系统下的栈结构和寄存器使用方式,以及内核栈的特殊结构和使用方法。文章还详细解释了如何通过task_struct找到相应的内核栈和内核寄存器,并介绍了新的机制下获取当前运行中的task_struct的方式。此外,文章还涉及了Per CPU变量作为内核中的重要同步机制,以及函数调用时函数栈的工作模式。通过本文的阅读,读者可以深入了解进程数据结构中的栈和寄存器的使用方式,以及如何在内核中进行函数调用和上下文切换。文章内容丰富,涵盖了多个技术细节,对于想深入了解进程数据结构和内核机制的读者来说,是一篇值得深入研读的文章。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《趣谈 Linux 操作系统》,新⼈⾸单¥68
《趣谈 Linux 操作系统》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(46)
- 最新
- 精选
 第九天魔王从网络协议课学到这里,满满的干货啊。特别是配图,太用心了,一看就是非常有心才能做出来的。谢谢刘老师!
第九天魔王从网络协议课学到这里,满满的干货啊。特别是配图,太用心了,一看就是非常有心才能做出来的。谢谢刘老师!作者回复: 谢谢鼓励
2019-04-2939 青石看这篇内容时,查了几篇资料。 在汇编代码中,函数调用的参数传递是通过把参数依次放在靠近调用者的栈的顶部来实现的。调用者获取参数时,只要相对于当前帧指针的向上偏移即可取到参数。即取调用者函数参数时执行movl 8(%ebp), %edx。
青石看这篇内容时,查了几篇资料。 在汇编代码中,函数调用的参数传递是通过把参数依次放在靠近调用者的栈的顶部来实现的。调用者获取参数时,只要相对于当前帧指针的向上偏移即可取到参数。即取调用者函数参数时执行movl 8(%ebp), %edx。作者回复: 赞,推荐这种查资料的方式,这样学到的东西就多多了
2019-04-29313 hua168老师,我求您了,能不能把您讲的专栏中涉及的书名加个豆瓣之类的链接😂😂,有些都重名,作者不同,😭😭不带这样玩的😭😭😭
hua168老师,我求您了,能不能把您讲的专栏中涉及的书名加个豆瓣之类的链接😂😂,有些都重名,作者不同,😭😭不带这样玩的😭😭😭作者回复: 啊,好的,看来应该给英文名加作者的
2019-04-298 嘉木有个疑问,两个进程切换时,用户栈的上下文保存在哪?
嘉木有个疑问,两个进程切换时,用户栈的上下文保存在哪?作者回复: 后面讲切换的时候会讲,用户栈相关寄存器在pt_regs中,用户栈的内存在虚拟地址空间,不会冲突
2019-05-285 骨汤鸡蛋面为什么用户态的栈不需要 task_struct 维护一个类似 *stack 的指针呢?
骨汤鸡蛋面为什么用户态的栈不需要 task_struct 维护一个类似 *stack 的指针呢?作者回复: mm里面有的
2019-05-224 Liber0点自动发,应该是自动发布的吧
Liber0点自动发,应该是自动发布的吧作者回复: 是的,是的,是自动发的。
2019-04-294 k先生老师,有个问题能否解答? task_struct找内核栈过程理解了,但是反过来找,这句“而 thread_info 的位置就是内核栈的最高位置,减去 THREAD_SIZE,就到了 thread_info 的起始地址。”没懂,烦请解答一下 这里说的最高位置应该是栈顶,到了栈顶就是thread_info最低地址,那不就直接找到了吗
k先生老师,有个问题能否解答? task_struct找内核栈过程理解了,但是反过来找,这句“而 thread_info 的位置就是内核栈的最高位置,减去 THREAD_SIZE,就到了 thread_info 的起始地址。”没懂,烦请解答一下 这里说的最高位置应该是栈顶,到了栈顶就是thread_info最低地址,那不就直接找到了吗作者回复: 不是的,对着图可以看的比较清楚
2019-07-2562 ...老师有个疑问 A调用B B应该是被调用者吧 是不是应该放在图上面部分
...老师有个疑问 A调用B B应该是被调用者吧 是不是应该放在图上面部分作者回复: 上面是栈的底部
2019-08-1421- 青石在12节里面提到“Linux的任务管理由统一的结构task_struct进行管理”。那么多核CPU的任务切换时,是不是就是将current_task切换到另一个task_struct呢? THREAD_SIZE是固定的大小,32位系统中是8K(页大小左移一位),64位系统是16K(页大小左移二位)。TOP_OF_KERNEL_STACK_PADDING就是图“内核栈是一个非常特殊的结构”中的“预留8个字节”。 通过task_struct找内核栈的过程: 1. task_struct找内核栈是通过stack指针,直接找到内核线程栈,stack指针记录的是内核栈的首地址。 2. task_struck找内核寄存器是通过 内核栈的首地址(1中的stack指针) + (THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING)定位到pt_regs的最高位地址,再减一得到pt_regs的最低位地址(首地址)。
作者回复: 不仅仅切换这个变量,要切换的还挺多的
2019-04-2921  石维康文中说“接下来就是 B 的栈帧部分了,先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,”感觉主流编译器还是直接能通过当前 RBP 或者 RSP 来进行偏移定位到传进来的参数了吧?保存这个 A 栈底位置更多的是为了回复 A 的现场吧?
石维康文中说“接下来就是 B 的栈帧部分了,先保存的是 A 栈帧的栈底位置,也就是 EBP。因为在 B 函数里面获取 A 传进来的参数,就是通过这个指针获取的,”感觉主流编译器还是直接能通过当前 RBP 或者 RSP 来进行偏移定位到传进来的参数了吧?保存这个 A 栈底位置更多的是为了回复 A 的现场吧?作者回复: 能的。
2019-04-2931
收起评论

