

26 | Fork/Join:单机版的MapReduce

该思维导图由 AI 生成,仅供参考
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

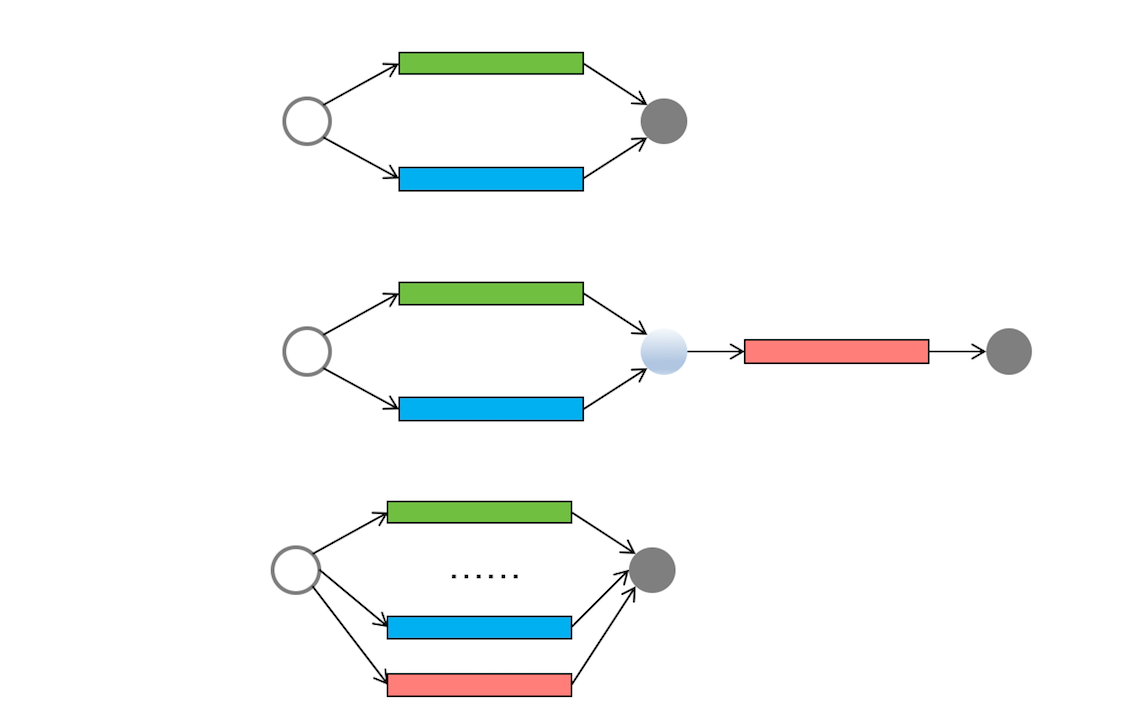
Fork/Join并行计算框架是Java中用于解决分治任务的高效工具。该框架类似于MapReduce的单机版,通过将大任务拆分成小任务并最终聚合结果来提高计算效率。文章介绍了Fork/Join的使用方法和工作原理,以及通过斐波那契数列计算示例展示了其应用。Fork/Join框架的核心组件是ForkJoinPool,支持任务窃取机制,确保线程工作负载均衡,性能优异。此外,文章还提到了Fork/Join与Stream API的关系,以及在不同类型计算任务下建议使用不同的ForkJoinPool。总的来说,Fork/Join并行计算框架适用于解决分治任务模型的并行计算问题,具有高效的任务调度和执行机制。
《Java 并发编程实战》,新⼈⾸单¥59

全部留言(57)
- 最新
- 精选
 爱吃回锅肉的瘦子https://www.liaoxuefeng.com/article/001493522711597674607c7f4f346628a76145477e2ff82000,老师,您好,我在廖雪峰网站中也看到forkjoin使用方式。讲解了,为啥不使用两次fork,分享出来给大家看看。
爱吃回锅肉的瘦子https://www.liaoxuefeng.com/article/001493522711597674607c7f4f346628a76145477e2ff82000,老师,您好,我在廖雪峰网站中也看到forkjoin使用方式。讲解了,为啥不使用两次fork,分享出来给大家看看。作者回复: 用两次fork()在join的时候,需要用这样的顺序:a.fork(); b.fork(); b.join(); a.join();这个要求在JDK官方文档里有说明。 如果是一不小心写成a.fork(); b.fork(); a.join(); b.join();就会有大神廖雪峰说的问题。 建议还是用fork()+compute(),这种方式的执行过程普通人还是能理解的,fork()+fork()内部做了很多优化,我这个普通人看的实在是头痛。 感谢分享啊。我觉得讲的挺好的。用这篇文章的例子理解fork()+compute()很到位。
2019-04-289116 锦CPU同一时间只能处理一个线程,所以理论上,纯cpu密集型计算任务单线程就够了。多线程的话,线程上下文切换带来的线程现场保存和恢复也会带来额外开销。但实际上可能要经过测试才知道。
锦CPU同一时间只能处理一个线程,所以理论上,纯cpu密集型计算任务单线程就够了。多线程的话,线程上下文切换带来的线程现场保存和恢复也会带来额外开销。但实际上可能要经过测试才知道。作者回复: 👍
2019-04-27571 尹圣看到分治任务立马就想到归并排序,用Fork/Join又重新实现了一遍, /** * Ryzen 1700 8核16线程 3.0 GHz */ @Test public void mergeSort() { long[] arrs = new long[100000000]; for (int i = 0; i < 100000000; i++) { arrs[i] = (long) (Math.random() * 100000000); } long startTime = System.currentTimeMillis(); ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors()); MergeSort mergeSort = new MergeSort(arrs); arrs = forkJoinPool.invoke(mergeSort); //传统递归 //arrs = mergeSort(arrs); long endTime = System.currentTimeMillis(); System.out.println("耗时:" + (endTime - startTime)); } /** * fork/join * 耗时:13903ms */ class MergeSort extends RecursiveTask<long[]> { long[] arrs; public MergeSort(long[] arrs) { this.arrs = arrs; } @Override protected long[] compute() { if (arrs.length < 2) return arrs; int mid = arrs.length / 2; MergeSort left = new MergeSort(Arrays.copyOfRange(arrs, 0, mid)); left.fork(); MergeSort right = new MergeSort(Arrays.copyOfRange(arrs, mid, arrs.length)); return merge(right.compute(), left.join()); } } /** * 传统递归 * 耗时:30508ms */ public static long[] mergeSort(long[] arrs) { if (arrs.length < 2) return arrs; int mid = arrs.length / 2; long[] left = Arrays.copyOfRange(arrs, 0, mid); long[] right = Arrays.copyOfRange(arrs, mid, arrs.length); return merge(mergeSort(left), mergeSort(right)); } public static long[] merge(long[] left, long[] right) { long[] result = new long[left.length + right.length]; for (int i = 0, m = 0, j = 0; m < result.length; m++) { if (i >= left.length) { result[m] = right[j++]; } else if (j >= right.length) { result[m] = left[i++]; } else if (left[i] > right[j]) { result[m] = right[j++]; } else result[m] = left[i++]; } return result; }
尹圣看到分治任务立马就想到归并排序,用Fork/Join又重新实现了一遍, /** * Ryzen 1700 8核16线程 3.0 GHz */ @Test public void mergeSort() { long[] arrs = new long[100000000]; for (int i = 0; i < 100000000; i++) { arrs[i] = (long) (Math.random() * 100000000); } long startTime = System.currentTimeMillis(); ForkJoinPool forkJoinPool = new ForkJoinPool(Runtime.getRuntime().availableProcessors()); MergeSort mergeSort = new MergeSort(arrs); arrs = forkJoinPool.invoke(mergeSort); //传统递归 //arrs = mergeSort(arrs); long endTime = System.currentTimeMillis(); System.out.println("耗时:" + (endTime - startTime)); } /** * fork/join * 耗时:13903ms */ class MergeSort extends RecursiveTask<long[]> { long[] arrs; public MergeSort(long[] arrs) { this.arrs = arrs; } @Override protected long[] compute() { if (arrs.length < 2) return arrs; int mid = arrs.length / 2; MergeSort left = new MergeSort(Arrays.copyOfRange(arrs, 0, mid)); left.fork(); MergeSort right = new MergeSort(Arrays.copyOfRange(arrs, mid, arrs.length)); return merge(right.compute(), left.join()); } } /** * 传统递归 * 耗时:30508ms */ public static long[] mergeSort(long[] arrs) { if (arrs.length < 2) return arrs; int mid = arrs.length / 2; long[] left = Arrays.copyOfRange(arrs, 0, mid); long[] right = Arrays.copyOfRange(arrs, mid, arrs.length); return merge(mergeSort(left), mergeSort(right)); } public static long[] merge(long[] left, long[] right) { long[] result = new long[left.length + right.length]; for (int i = 0, m = 0, j = 0; m < result.length; m++) { if (i >= left.length) { result[m] = right[j++]; } else if (j >= right.length) { result[m] = left[i++]; } else if (left[i] > right[j]) { result[m] = right[j++]; } else result[m] = left[i++]; } return result; }作者回复: 👍👍👍举一反三了😄
2019-04-29644 QQ怪学习了老师的分享,现在就已经在工作用到了,的确是在同事面前好好装了一次逼
QQ怪学习了老师的分享,现在就已经在工作用到了,的确是在同事面前好好装了一次逼作者回复: 👍说明你很有悟性😄
2019-05-2436 linqw以前在面蚂蚁金服时,也做过类似的题目,从一个目录中,找出所有文件里面单词出现的top100,那时也是使用服务提供者,从目录中找出一个或者多个文件(防止所有文件一次性加载内存溢出,也为了防止文件内容过小,所以每次都确保读出的行数10万行左右),然后使用fork/join进行单词的统计处理,设置处理的阈值为20000。 课后习题:单核的话,使用单线程会比多线程快,线程的切换,恢复等都会耗时,并且要是机器不允许,单线程可以保证安全,可见性(cpu缓存,单个CPU数据可见),线程切换(单线程不会出现原子性)
linqw以前在面蚂蚁金服时,也做过类似的题目,从一个目录中,找出所有文件里面单词出现的top100,那时也是使用服务提供者,从目录中找出一个或者多个文件(防止所有文件一次性加载内存溢出,也为了防止文件内容过小,所以每次都确保读出的行数10万行左右),然后使用fork/join进行单词的统计处理,设置处理的阈值为20000。 课后习题:单核的话,使用单线程会比多线程快,线程的切换,恢复等都会耗时,并且要是机器不允许,单线程可以保证安全,可见性(cpu缓存,单个CPU数据可见),线程切换(单线程不会出现原子性)作者回复: 👍
2019-04-2734 右耳听海请教老师一个问题,merge函数里的mr2.compute先执行还是mr1.join先执行,这两个参数是否可交换位置
右耳听海请教老师一个问题,merge函数里的mr2.compute先执行还是mr1.join先执行,这两个参数是否可交换位置作者回复: 我觉得不可以,如果join在前面会先首先让当前线程阻塞在join()上。当join()执行完才会执行mr2.compute(),这样并行度就下来了。
2019-04-27625- Geek_ebda96如果所有的并行流计算都是 CPU 密集型计算的话,完全没有问题,但是如果存在 I/O 密集型的并行流计算,那么很可能会因为一个很慢的 I/O 计算而拖慢整个系统的性能。 老师这里的意思是不是,如果有耗时的i/o计算,需要用单独的forkjoin pool 来处理这个计算,在程序设计的时候就要跟其他cpu密集计算的任务分开处理?
作者回复: 是的
2019-05-1314  王伟老师,我现在碰到一个生产问题:用户通过微信小程序进入我们平台,我们只能需要使用用户的手机号去我们商家库中查取该用户的注册信息。在只知道用户手机号的情况下我们需要切换到所有的商家库去查询。这样非常耗时。ps:我们商家库做了分库处理而且数量很多。想请教一下您,这种查询该如何做?
王伟老师,我现在碰到一个生产问题:用户通过微信小程序进入我们平台,我们只能需要使用用户的手机号去我们商家库中查取该用户的注册信息。在只知道用户手机号的情况下我们需要切换到所有的商家库去查询。这样非常耗时。ps:我们商家库做了分库处理而且数量很多。想请教一下您,这种查询该如何做?作者回复: 可以加redis缓存看看,也可以加本地缓存。不要让流量直接打到数据库上
2019-04-2829 êwěn老师,fork是fork调用者的子任务还是表示下面new出来的任务是子任务?
êwěn老师,fork是fork调用者的子任务还是表示下面new出来的任务是子任务?作者回复: fork是fork调用者这个子任务加入到任务队列里
2019-04-277 Nick简易的MapReduce的程序跑下来不会栈溢出吗?
Nick简易的MapReduce的程序跑下来不会栈溢出吗?作者回复: 递归程序,如果语言层面没有办法优化,都会的
2019-06-056

