

26|数据库无法启动,如何读取InnoDB文件中的数据?(下)

InnoDB 中的 B+ 树
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

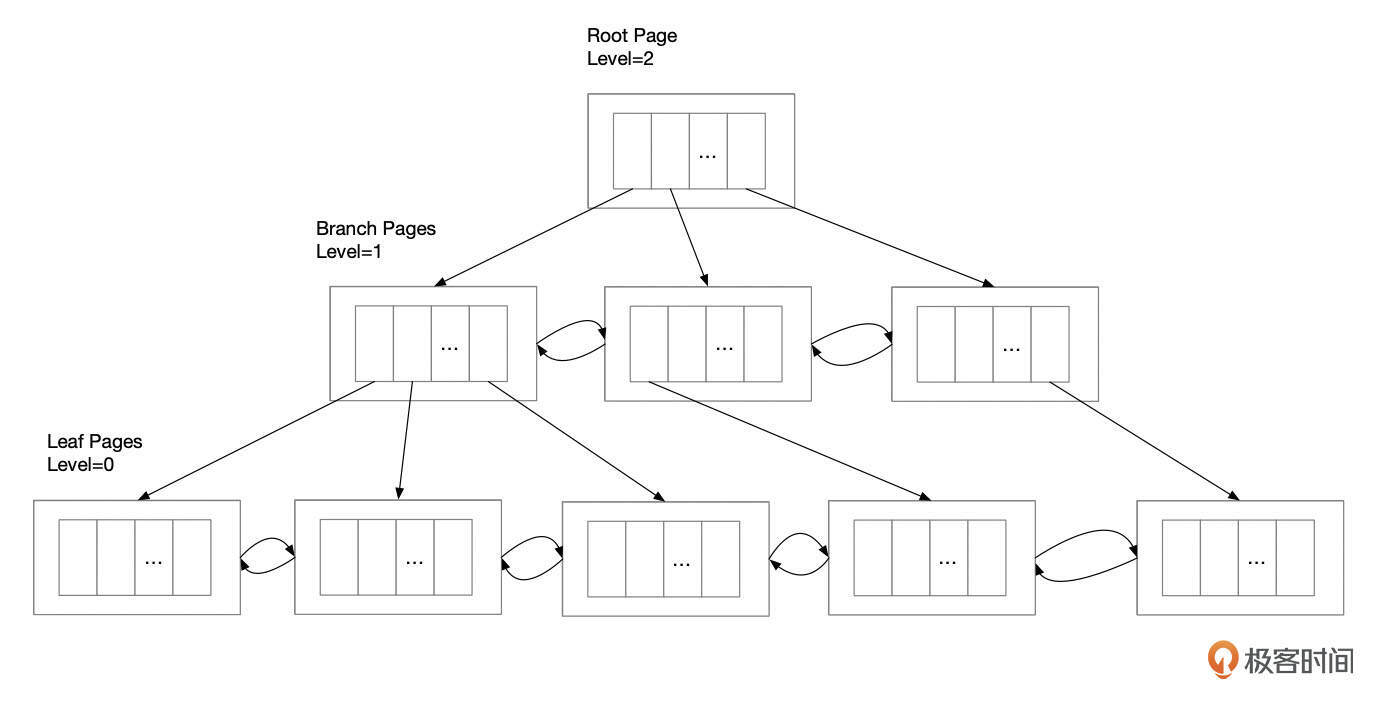
1. InnoDB中的B+树是由根节点、分支节点和叶子节点组成,每个页面包含头部信息和页面记录,分支页面中的记录指向下一个层级的页面编号,页面头部还记录了同一层级中相邻页面的编号,页面记录包含Key和Value两个部分。 2. InnoDB中的聚簇索引结构包括根页面、分支页面和叶子页面,根页面记录了索引id、树的高度、叶子页面和分支页面所在段的段描述符的地址等信息,分支页面和叶子页面分别记录了页面的级别、前后相邻页面的编号以及页面内的记录等信息。 3. InnoDB的段空间管理包括段描述符(inode)记录了段的相关信息,每个段里面的所有的区组成了3个链表:Free链表、Not Full链表和Full链表,数据文件中存在大量双向链表结构,由链表基节点和链表节点组成,记录了链表头部节点和尾部节点,所有节点通过prev和next指针连接在一起。 4. InnoDB的数据文件中存在Full链表,记录了区的状态和每一个页面的状态,一个区有64个页面,区描述符中的segment id为区的ID,prev和next指向链表中相邻的区,status是区的状态,bitmap中记录了区中每一个页面的状态。 5. InnoDB的数据文件中存在Not Full链表,记录了部分页面已经分配,其他页面是空闲的区,Full链表中的区,所有的页面都已经分配。 6. InnoDB的数据文件中存在Free链表,记录了完全空闲的区。 7. InnoDB的数据文件中的区描述符记录了区的状态和每一个页面的状态,一个区有64个页面。 8. InnoDB的数据文件中存在碎片区,碎片区的页面可以分配给不同的段使用,给段分配空间时,先会从碎片区中分配页面,这些页称为碎片页,页面编号会记录到INODE的碎片页数组中。 9. InnoDB中,表和索引数据都存储在表空间中,每个表空间都是由1个数据文件组成,数据文件有固定的格式,每个数据文件被分割为固定大小的页(Page),相邻的页组成区(Extent),表和索引的数据通过段(Segment)来组织,每个段由一些页和区组成。
《MySQL 运维实战课》,新⼈⾸单¥59

全部留言(2)
- 最新
- 精选
 叶明我觉得和系统表空间 ibdata1 有关系,系统表 mysql.indexes 在实例初始化时生成,其元数据信息(如根页面编号)可能被存储在系统表空间里,Innodb 在启动时可以直接访问这些位置,而不需要依赖数据字典。
叶明我觉得和系统表空间 ibdata1 有关系,系统表 mysql.indexes 在实例初始化时生成,其元数据信息(如根页面编号)可能被存储在系统表空间里,Innodb 在启动时可以直接访问这些位置,而不需要依赖数据字典。作者回复: 这是一个合理的猜想 :) MySQL 8启动时,会加载数据字典(mysql.ibd),数据字典中有一个mysql.dd_properties表,16讲中提到过这个表。从这个表里,能看到一些有意思的数据,包括各个数据字典表的一些内部信息。每个数据字典表索引的root页面编号,这里应该也有。 至于mysql.dd_properties的root页面号,应该是写死在代码中的。 而dd_properties的数据,是在数据库初始化(mysqld --initialize)的时候填充的。
2024-10-21归属地:江苏- binzhang为啥在二级索引的root和branch page上要存储主键列的值? 感觉没必要啊
作者回复: 这是一个很好的问题。 如果branch page上不存主键列,在key列有重复值的时候,插入一个key时应该写到那个页面中去? 假设表里已经有很多key-x的记录,在insert values ( 'key-x', 'pk-x')时,怎么定位最终要插入的那个Leaf页面? key列和主键列拼在一起后,就不会有重复的记录了,可以精确定位。
2024-10-21归属地:美国