

08|HBase如何组织与存储数据?
彭旭

你好,我是彭旭。
上节课,我们分析了云服务的数据存储需求,了解了之前基于 MySQL 的分库分表支撑海量数据的存储与读写的过程。但是,因为硬件与运维上的巨大成本,我们不得不谋求一个新的存储方案。
这两节课,我们就一起学习 HBase 的架构和原理,看看 HBase 是怎么解决之前的问题的。
今天我们会聚焦在 HBase 组织数据的方式上,解决上节课提到的运维成本问题。希望通过这节课的学习,你能了解两个关键知识点。
HBase 如何存储数据,给数据分区。在集群扩容的过程中,HBase 自动迁移分区从而实现负载均衡的过程。
HBase 物理上存储数据的方法,HBase 集群包含的组件以及组件之间的协作方式。
HBase 数据组织的逻辑模型
使用一个数据库,第一步可以去理解它的数据模型,还有它的数据是怎么组织的。
HBase 和关系型数据库一样,以数据表的形式组织数据。一张表包含多行数据,每行数据都由一个唯一的行键来标识。
数据在表中以行键的字典序排序,像这张图一样。
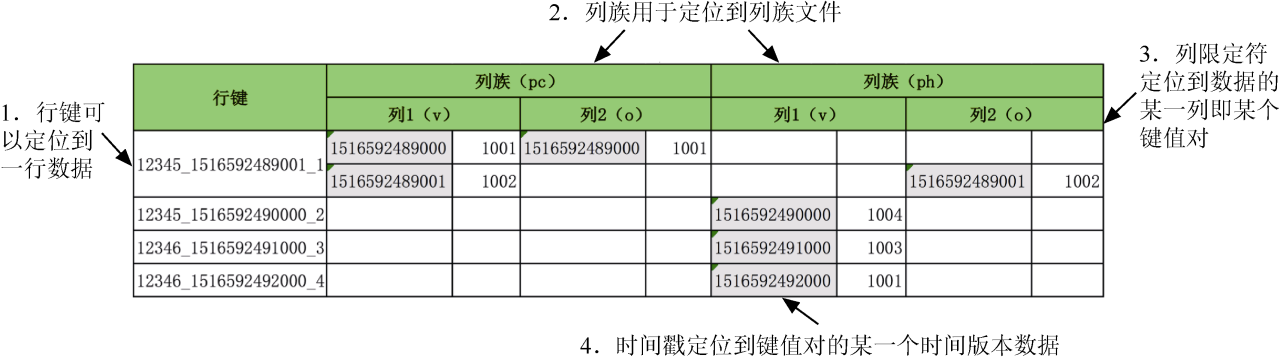
行键类似关系型数据库主键,通过行键可以定位到一行数据。对 HBase 来说,通过行键来读取单行或者多行数据最高效。当然,它也支持基于行键区间的扫描。
HBase 是一个宽列族存储数据库,数据按列族聚簇存储在一起。虽然 HBase 是列式存储数据库,但不建议一个表有多个列族。所以,在单个列族的情况下,基本上就跟行式存储类似了。
HBase 建表的时候需要至少指定一个列族,但是不需要声明列。每一行数据都可以定义属于自己的列,也就是支持动态的 Schema。但是每行的列不一定有值,所以 HBase 是一个稀疏表。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. HBase的数据模型类似一个嵌套了多层的Map,通过行键、列族、列限定符、数据版本可以找到存储的行、列的数据。 2. HBase的逻辑模型支持动态Schema,每行数据都可以定义属于自己的列,并且支持多个版本的数据,这种设计解决了兼容多版本的客户端需求。 3. HBase的分区是数据分布与负载均衡的最小单元,HBase能够自动帮助拆分、合并分区,并在集群扩容时自动迁移分区、平衡数据与请求。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《分布式数据库从入门到实战》,新⼈⾸单¥59
《分布式数据库从入门到实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
精选留言
由作者筛选后的优质留言将会公开显示,欢迎踊跃留言。
收起评论