
开篇词|玩转数据库,让数据尽在你的掌控
彭旭

讲述:彭旭大小:8.37M时长:09:09
你好,我是彭旭。欢迎和我一起玩转数据库。
先介绍一下自己吧。我是《HBase 入门与实践》的作者,曾经在东方海外、阿里巴巴、魅族任职,目前是惟客数据总架构师。
我刚毕业工作的时候就接触了 Oracle。当时我把一本《Oracle 9i & 10g 编程艺术》翻了几遍,觉得很有收获。这本书里提到的一些内容,像多版本 MVCC、Redo Undo Log、索引的调优等,在大数据时代的分布式数据库中也仍然适用。
其实,许多数据库原理是相通的。只是不同类型的数据库有不同的出发点,导致它们的设计目标有所不同。有些数据库侧重于吞吐量,有些则侧重性能;有些注重读取性能,有些则更注重写入性能。
这些年,我见证了数据库生态的各类变化。虽然现在基于 Spring Boot、Spring Cloud 微服务架构中,关系型数据库 MySQL 已经成为了标配。但是如果你的业务发展得很快,MySQL 有可能就成为了瓶颈。
这时候,你可能就得考虑引入一些分布式或者分析型数据库了。
为什么选择合适的数据库很重要?
数据库是软件系统的核心组成部分。尤其是现在的云原生时代,因为基于微服务、容器化的服务层可以无限弹性扩展,所以很多时候,软件系统的瓶颈基本都在数据库。了解不同数据库的基本原理和适用场景,对你避免瓶颈、解决瓶颈,甚至选用合适的数据库,都是很有帮助的。
我经历了很多因为各种原因需要做数据库迁移的例子。
想去 IOE 化,从商业化数据库迁移到开源数据库,所以从 Oracle、Sybase、H2 等迁移到 MySQL。
因为硬件成本、运维成本问题,从 MySQL 迁移到 HBase。
因为 Hadoop 集群过重导致硬件成本过高,从 Hive 迁移到 StarRocks。
这些数据库的迁移,不光是要将数据库中存储的海量数据迁移,有时候还需要花大力气迁移应用程序中涉及数据库方言的相关代码。
当然,市面上有很多数据迁移工具,但就算这些工具能够完美地迁移数据,你也还是得花大力气去调整程序、设计你的程序,让它在迁移的同时也能够并行运行,避免迁移出错,在回滚时手足无措。
所以,从一开始就选择好适合你业务场景的数据库,就能减少大量后续的重构和维护成本,延长软件的生命周期,体现设计的长期价值。
这里并不是说一开始的设计就一定要选用一个很高大上的数据库,或者说在业务方向与发展都不明确的情况下,选用一个“适合业务场景”但是成本很高的数据库。其实这也是一个架构,一种平衡:是牺牲扩展性来快速迭代上线,还是一开始就充分考虑扩展性,降低后续重构的成本?
而所有选择的前提,都是我们熟悉各种类型的数据库,了解它们的基础原理、设计目标以及适用于什么样的业务场景。这些内容都会在咱们的专栏里一一讲解。
我们的课程怎么安排?
我们课程一共有 5 个章节。
其中,基础篇涵盖了大部分数据库基础知识。之后我们会进入应用案例 + 实战的部分。我挑选了几个主流分布式数据库来讲解,包括 Hadoop 生态体系中实时随机存取的代表 HBase,新一代极速全场景 MPP 数据库 StarRocks,联机分析(OLAP)的列式数据库管理系统 ClickHouse。最后,还会有一个章节专门介绍 AI 时代的向量数据库。
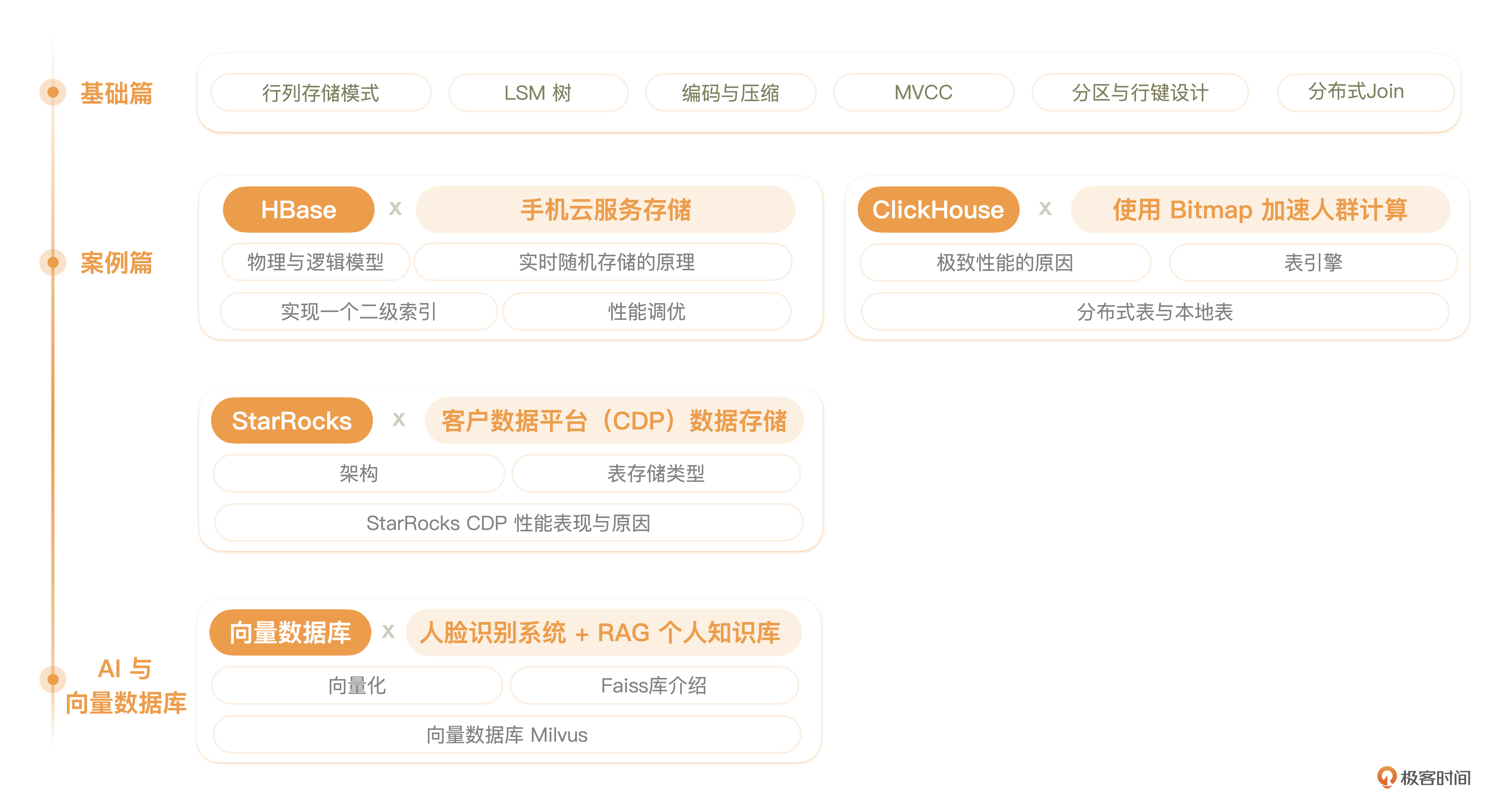
基础篇
这一章,我会带你学习数据库的基础知识,包括不同类型数据库的存储模型,编码与压缩的必要性,数据库事务的作用以及 MVCC 机制,LSM 是如何优化读写速度的,如何合适地对海量数据进行分片,以及分布式场景下表 Join 的方式等等。
在介绍这些基础知识的同时,我还会帮你对比一下课程中要学的几个数据库,看看它们在基础设计还有适用场景上有什么异同。相信这些内容一定能对你做数据库选型有不小的帮助。
HBase 篇
从这章开始,我们就要进入到具体数据库的学习了。这几章我都会秉持着案例 + 原理的思路,让你在学会原理的同时,看到它们在实际场景中发挥的作用。
HBase 篇的案例是一个手机云服务存储的需求。基于这个案例,我们会一起分析 MySQL 分库分表下运维成本、硬件成本、扩展性上的问题。
比如 HBase 如何组织数据?如何自管理数据分区?物理模型上如何满足弹性伸缩与负载均衡?我会从性能层面解释 HBase 能够在实时随机存取的需求上替换掉 MySQL 的原因,以及同时解决成本与扩展性问题的设计思路。最后,还会和你一起探索 HBase 更多的调优方法,在性能上进一步提升。
StarRocks 篇
StarRocks 的表模型与我们在做数据建模的分层架构非常类似,它也号称是一个全场景的分析型 MPP 数据库。
所以这一章我选用的是一个典型的客户数据平台 CDP 案例。通过这个案例,我会给你介绍 StarRocks 的基本架构与原理,以及基于 StarRocks 的表模型设计 CDP 相关表的方法。最后,我们还会了解 StarRocks 优化数据查询性能,实现实时更新与急速查询的具体思路。
ClickHouse 篇
ClickHouse 给人的印象是基于列式存储的极致的高性能宽表查询。在这个章节,我们会分析 ClickHouse 高性能的原理。同时沿用 CDP 的需求,看看表模型在 ClickHouse 中又应该如何设计,如何并行计算和调优。
AI 与向量数据库篇
AI 时代 ChatGPT 的大火带动了向量数据库的爆发。在这个章节,我们一起看看向量化的需求是怎么产生的。同时,我还会给你介绍向量查询引擎 Faiss 和向量数据库 Milvus,我们会尝试用向量查询引擎 Faiss 搭建一个人脸识别系统,再通过 Milvus 结合大模型搭建一个 RAG 个人知识库。
写在最后
现在很多软件的开发其实很简单,对数据库的操作可能就是一个 CRUD,而且有很多框架能够自动帮你生成这些重复性的代码。你有时是不是也会感觉数据库的原理、事务、锁之类的知识离日常工作很远?
其实不然。当你碰到线上数据库因为死锁报错、慢 SQL 导致 CPU 占用过高、一个报表运行了几个小时没有结果等等问题的时候,如果你非常熟悉数据库原理,这些问题也许可以通过较小的代价去优化解决。也许它们就是一个索引建得不合理,没有命中,也许是数据没有合理分区等等。
所以我在设计专栏的时候,专注于数据库存储引擎,同时贯穿了关系型数据库、分布式数据库、MPP 分析型数据库、向量数据库的原理和实践内容。希望能通过一个个的实际案例,和你一起观察、学习这些数据库满足业务需求的细节。
通过这些原理、案例的学习,希望你能够达到几个目标。

选型有方向。熟悉这几个典型的具有代表性的不同类型的数据库,并了解应该在什么场景下使用。
调优有思路。了解一些数据库的基本原理,读写上是如何优化的,压缩与编码又该如何使用,能够在需要的时候对系统、数据库进行调优。
问题有解法。能够在使用各种数据库的过程中预防问题、发现问题、解决问题。
让我们一起了解数据库、玩转数据库,从这门课开始,让数据尽在你的掌控。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

1. 数据库的核心作用和重要性,特别是在云原生时代中,数据库往往成为软件系统的瓶颈。 2. 选择合适的数据库对于避免瓶颈、解决瓶颈以及延长软件生命周期具有重要意义。 3. 数据库迁移的挑战和成本,以及选择适合业务场景的数据库的重要性。 4. 课程安排包括基础篇、HBase篇、StarRocks篇、ClickHouse篇和AI与向量数据库篇,涵盖了数据库的基础知识和实际应用案例。 5. 基础篇将介绍数据库的基础知识,不同类型数据库的存储模型,事务的作用,MVCC机制等,并对比不同数据库的异同。 6. HBase篇将深入案例+原理的方式介绍HBase在实际场景中的应用和性能优化。 7. StarRocks篇和ClickHouse篇将介绍这两个数据库的基本架构与原理,以及在特定案例下的表模型设计和性能优化。 8. AI与向量数据库篇将介绍向量化的需求以及向量查询引擎Faiss和向量数据库Milvus的应用。 9. 通过学习数据库的原理和实践,希望读者能够在选型、调优和问题解决方面有所收获,使数据尽在掌控。
2024-06-13给文章提建议
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《分布式数据库从入门到实战》,新⼈⾸单¥59
《分布式数据库从入门到实战》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(1)
- 最新
- 精选
 小虎子🐯终于等到啦,跟着彭老师一起掌握数据库!2024-06-13归属地:北京
小虎子🐯终于等到啦,跟着彭老师一起掌握数据库!2024-06-13归属地:北京
收起评论