

11|省下钱买显卡,如何利用开源模型节约成本?

该思维导图由 AI 生成,仅供参考
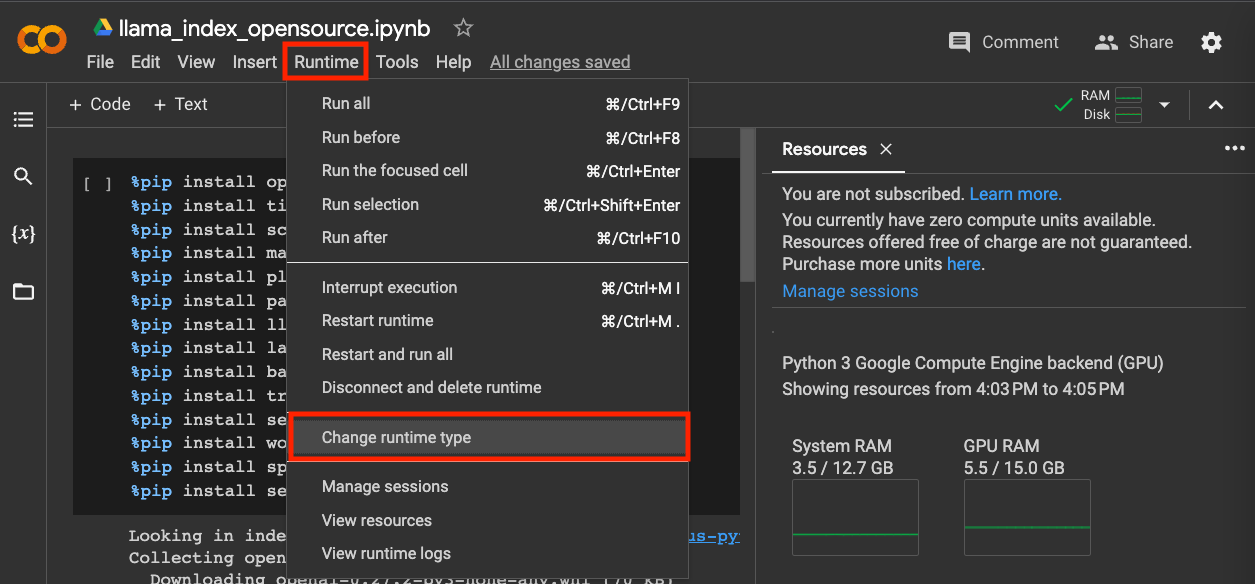
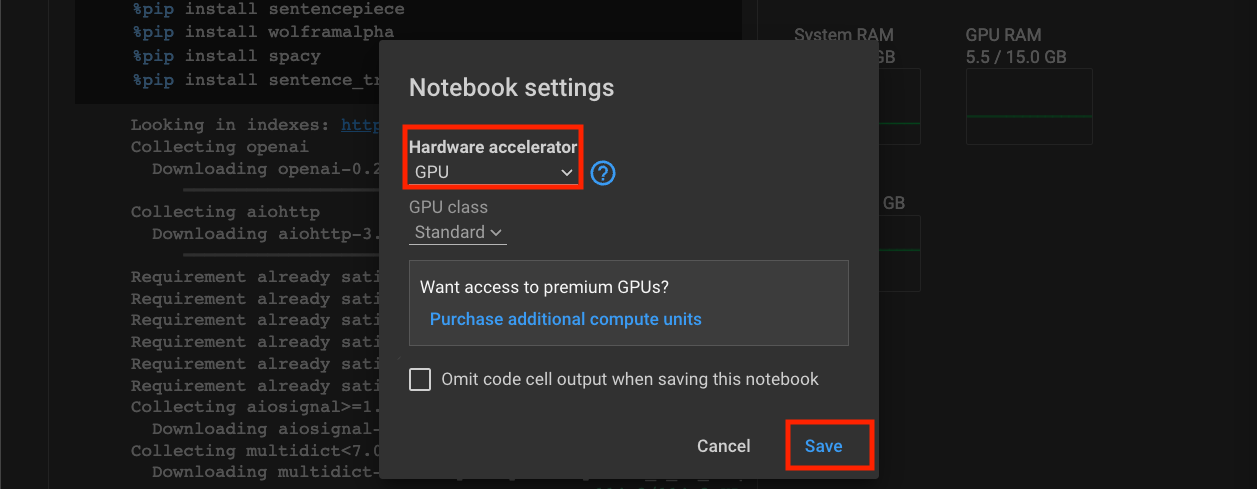
在 Colab 里使用 GPU
HuggingfaceEmbedding,你的开源伙伴
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何利用开源模型替代昂贵的显卡,从而节约成本。作者首先建议在Colab中使用GPU来运行开源模型,以节省成本。其次,介绍了HuggingfaceEmbedding作为开源伙伴,可以替代OpenAI的API,使用sentence-transformers库进行模型嵌入。文章还展示了如何使用开源模型进行FAQ问题的语义搜索,通过示例展示了AI给出的正确回答。通过这些方法,读者可以了解如何利用开源模型来替代昂贵的显卡,从而节约成本。文章还介绍了如何使用ChatGLM语言模型进行问答,展示了其基本的知识理解和推理能力。通过这些技术,读者可以了解如何利用开源模型来替代显卡,从而省下购买显卡的费用。文章还指出了开源模型的不足之处,提醒读者在使用开源模型时需要注意数据安全等问题。文章还讨论了开源模型在处理复杂问题时的局限性,以及对读者提出了思考题,鼓励读者尝试其他开源模型并分享评测结果。
《AI 大模型之美》,新⼈⾸单¥68

全部留言(37)
- 最新
- 精选
 Toni在第二讲中,用亚马逊提供的用户对一些食物评价的真实数据集进行了情感分析。当时为了避免重新调用 OpenAI 的 API 浪费钱,老师推荐使用已经计算好的含有 Embedding 的数据。用openai.embeddings_utils 中的 get_embedding (EMBEDDING_MODEL = "text-embedding-ada-002")不仅费钱还耗时。我试着跑过100个数据,好像用了20分钟,花费也不少。 本节课中老师介绍了免费的 sentence_transformers 正好可以拿来用在情感数据分析上, 选用 model = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')。同样计算1000个数据的 embedding,速度很快,且无费用,适合练手。 测试结果如下: precision recall f1-score support negative 0.77 0.78 0.77 148 positive 0.96 0.95 0.96 773 accuracy 0.93 921 macro avg 0.86 0.87 0.86 921 weighted avg 0.93 0.93 0.93 921 为了对比,将第二讲中老师用 OpenAI 的方法得到的结果放在了这里: precision recall f1-score support negative 0.98 0.73 0.84 136 positive 0.96 1.00 0.98 789 accuracy 0.96 925 macro avg 0.97 0.86 0.91 925 weighted avg 0.96 0.96 0.96 925 使用的方法不用,结果也不同。OpenAI 的准确率更高。
Toni在第二讲中,用亚马逊提供的用户对一些食物评价的真实数据集进行了情感分析。当时为了避免重新调用 OpenAI 的 API 浪费钱,老师推荐使用已经计算好的含有 Embedding 的数据。用openai.embeddings_utils 中的 get_embedding (EMBEDDING_MODEL = "text-embedding-ada-002")不仅费钱还耗时。我试着跑过100个数据,好像用了20分钟,花费也不少。 本节课中老师介绍了免费的 sentence_transformers 正好可以拿来用在情感数据分析上, 选用 model = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')。同样计算1000个数据的 embedding,速度很快,且无费用,适合练手。 测试结果如下: precision recall f1-score support negative 0.77 0.78 0.77 148 positive 0.96 0.95 0.96 773 accuracy 0.93 921 macro avg 0.86 0.87 0.86 921 weighted avg 0.93 0.93 0.93 921 为了对比,将第二讲中老师用 OpenAI 的方法得到的结果放在了这里: precision recall f1-score support negative 0.98 0.73 0.84 136 positive 0.96 1.00 0.98 789 accuracy 0.96 925 macro avg 0.97 0.86 0.91 925 weighted avg 0.96 0.96 0.96 925 使用的方法不用,结果也不同。OpenAI 的准确率更高。作者回复: 👍
2023-04-11归属地:瑞士4
 东方奇骥老师,是不是要4080显卡才跑得动?单机能跑得动吗
东方奇骥老师,是不是要4080显卡才跑得动?单机能跑得动吗作者回复: 显存需要比较大,建议在colab下运行,我给了一个可以在Colab下单独运行的Notebook。 https://github.com/xuwenhao/geektime-ai-course/blob/main/11_colab_chatglm_opensource.ipynb
2023-04-07归属地:四川34 zhihai.tu
zhihai.tu 老师,想请教一下,我发现我用colab跑了程序,如果第二天再打开这个程序,相应的已经跑过得脚本,效果都失效了,比如pip安装过的都还原了,另外磁盘目录上生成的文件夹和文件也没了。想请问下如何解决这个问题呢?不然相当的麻烦。谢谢。
老师,想请教一下,我发现我用colab跑了程序,如果第二天再打开这个程序,相应的已经跑过得脚本,效果都失效了,比如pip安装过的都还原了,另外磁盘目录上生成的文件夹和文件也没了。想请问下如何解决这个问题呢?不然相当的麻烦。谢谢。作者回复: https://ayoolafelix.hashnode.dev/how-to-permanently-install-a-module-on-google-colab-ckixqrvs40su044s187y274tc 可以把安装路径都设置到 mount的google drive里,这样以后每次都只需要配置一下路径,不需要再重新安装了。
2023-04-26归属地:上海3 胖子AttributeError Traceback (most recent call last) <ipython-input-54-086bfff09511> in <cell line: 8>() 6 Q: 你们的退货政策是怎么样的? 7 """ ----> 8 response, history = model.chat(tokenizer, question, history=[]) 9 print(response) 21 frames /usr/local/lib/python3.9/dist-packages/google/protobuf/unknown_fields.py in <module> 42 from google.protobuf.internal import api_implementation 43 ---> 44 if api_implementation._c_module is not None: # pylint: disable=protected-access 45 UnknownFieldSet = api_implementation._c_module.UnknownFieldSet # pylint: disable=protected-access 46 else: AttributeError: module 'google.protobuf.internal.api_implementation' has no attribute '_c_module' 搞不定
胖子AttributeError Traceback (most recent call last) <ipython-input-54-086bfff09511> in <cell line: 8>() 6 Q: 你们的退货政策是怎么样的? 7 """ ----> 8 response, history = model.chat(tokenizer, question, history=[]) 9 print(response) 21 frames /usr/local/lib/python3.9/dist-packages/google/protobuf/unknown_fields.py in <module> 42 from google.protobuf.internal import api_implementation 43 ---> 44 if api_implementation._c_module is not None: # pylint: disable=protected-access 45 UnknownFieldSet = api_implementation._c_module.UnknownFieldSet # pylint: disable=protected-access 46 else: AttributeError: module 'google.protobuf.internal.api_implementation' has no attribute '_c_module' 搞不定作者回复: 感觉是 protobuf 版本的问题,试试看更新一下protobuf版本? pip install --upgrade protobuf
2023-04-22归属地:中国香港52 ༺ღ天口²º²²ღ༻老师,FAQ数据在哪里?
༺ღ天口²º²²ღ༻老师,FAQ数据在哪里?作者回复: https://github.com/xuwenhao/geektime-ai-course 的 data 目录下
2023-05-06归属地:上海1 川月使用这个开源模型获取的index怎么保存啊,使用之前的方法并不行,还有生成的index可以追加吗,不然每次有新数据的时候都要重新跑一边,或者可以使用数据库存储吗,希望老师讲解一下
川月使用这个开源模型获取的index怎么保存啊,使用之前的方法并不行,还有生成的index可以追加吗,不然每次有新数据的时候都要重新跑一边,或者可以使用数据库存储吗,希望老师讲解一下作者回复: embedding可以存储到向量数据库,比如 pgvector, milvus, pinecone 等等 索引可以save下来变成json文件 更详细的手工管理索引的方式,可以看一下 llama-index 的官方文档 https://gpt-index.readthedocs.io/en/latest/
2023-04-07归属地:四川21 孟健Meta最近也开源了大语言模型,好像更好一些?
孟健Meta最近也开源了大语言模型,好像更好一些?作者回复: 目前 llama 没有公开渠道可以直接获得模型,所以不适合作为课程的一部分 目前从有限体验来看,裁剪到单机可以加载的情况下,没有觉得在中文上比 ChatGLM 好
2023-04-06归属地:广东1 地平线由于llama-index 升级,我使用的版本是0.6.8,修改了llama-index代码,程序运行没有报错,但是没有输出内容 from langchain.text_splitter import SpacyTextSplitter llm_predictor = LLMPredictor(llm=CustomLLM()) text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20) parser = SimpleNodeParser(text_splitter=text_splitter) documents = SimpleDirectoryReader('./drive/MyDrive/colab_data/faq/').load_data() nodes = parser.get_nodes_from_documents(documents) embed_model = LangchainEmbedding(HuggingFaceEmbeddings( model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2" )) service_context = ServiceContext.from_defaults(embed_model=embed_model, llm_predictor=llm_predictor) dimension = 768 faiss_index = faiss.IndexFlatIP(dimension) # index = GPTListIndex(nodes=nodes, faiss_index=faiss_index, service_context=service_context) index = GPTListIndex(nodes=nodes, service_context=service_context) from llama_index import QuestionAnswerPrompt QA_PROMPT_TMPL = ( "{context_str}" "\n\n" "根据以上信息,请回答下面的问题:\n" "Q: {query_str}\n" ) QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL) query_engine = index.as_query_engine( retriever_mode="embedding", verbose=True, text_qa_template=QA_PROMPT, ) response = query_engine.query("请问你们海南能发货吗?") print(response)
地平线由于llama-index 升级,我使用的版本是0.6.8,修改了llama-index代码,程序运行没有报错,但是没有输出内容 from langchain.text_splitter import SpacyTextSplitter llm_predictor = LLMPredictor(llm=CustomLLM()) text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=100, chunk_overlap=20) parser = SimpleNodeParser(text_splitter=text_splitter) documents = SimpleDirectoryReader('./drive/MyDrive/colab_data/faq/').load_data() nodes = parser.get_nodes_from_documents(documents) embed_model = LangchainEmbedding(HuggingFaceEmbeddings( model_name="sentence-transformers/paraphrase-multilingual-mpnet-base-v2" )) service_context = ServiceContext.from_defaults(embed_model=embed_model, llm_predictor=llm_predictor) dimension = 768 faiss_index = faiss.IndexFlatIP(dimension) # index = GPTListIndex(nodes=nodes, faiss_index=faiss_index, service_context=service_context) index = GPTListIndex(nodes=nodes, service_context=service_context) from llama_index import QuestionAnswerPrompt QA_PROMPT_TMPL = ( "{context_str}" "\n\n" "根据以上信息,请回答下面的问题:\n" "Q: {query_str}\n" ) QA_PROMPT = QuestionAnswerPrompt(QA_PROMPT_TMPL) query_engine = index.as_query_engine( retriever_mode="embedding", verbose=True, text_qa_template=QA_PROMPT, ) response = query_engine.query("请问你们海南能发货吗?") print(response)作者回复: llama index 最近又更新了大版本,接口又改了一遍。如果要立刻可以运行,可以先 pip install --force-reinstall -v "llama-index==0.5.27" 退回到 0.5 系列的版本 晚点我看一下更新代码到0.6.x 版本
2023-05-18归属地:美国2 茶桁老师,“GPTFaissIndex”这个方法似乎没有了,替换的其他方法不知道是什么,怎么用。
茶桁老师,“GPTFaissIndex”这个方法似乎没有了,替换的其他方法不知道是什么,怎么用。作者回复: llama index 最近又更新了大版本,接口又改了一遍。如果要立刻可以运行,可以先 pip install --force-reinstall -v "llama-index==0.5.27" 退回到 0.5 系列的版本 晚点我看一下更新代码到0.6.x 版本
2023-05-18归属地:上海 hornColab报错怎么回事呢 ImportError: cannot import name 'GPTFaissIndex' from 'llama_index' (/usr/local/lib/python3.10/dist-packages/llama_index/__init__.py)
hornColab报错怎么回事呢 ImportError: cannot import name 'GPTFaissIndex' from 'llama_index' (/usr/local/lib/python3.10/dist-packages/llama_index/__init__.py)作者回复: llama index 最近又更新了大版本,接口又改了一遍。如果要立刻可以运行,可以先 pip install --force-reinstall -v "llama-index==0.5.27" 退回到 0.5 系列的版本 晚点我看一下更新代码到0.6.x 版本
2023-05-15归属地:北京

