

10|AI连接外部资料库,让Llama Index带你阅读一本书

该思维导图由 AI 生成,仅供参考
大型语言模型的不足之处
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

llama_index是一个强大的Python库,可以帮助用户生成文章摘要和进行多模态信息索引。通过构建树状索引,用户可以对长文本进行分段小结,再对总结内容进行再次小结,从而生成整篇文章的摘要。文章还介绍了如何利用llama_index的GPTListIndex结构进行索引构建,并展示了如何利用ChatOpenAI模型进行文章小结。此外,文章还提到了llama_index的多模态能力,可以索引文本和图片信息,为读者展示了如何利用llama_index索引小票信息并进行查询。整体而言,本文深入浅出地介绍了llama_index库的使用方法,为读者提供了实用的技术指导,帮助他们快速了解并应用该库进行文章摘要生成和多模态信息索引。文章还提到了llama_index的快速迭代和不断发展,以及对中文支持和各种数据源格式的DataConnector。通过这篇文章,读者可以快速了解llama_index的功能和使用方法,以及如何构建自己的“第二大脑”资料库,将数据集交给AI进行索引,获得一个专属于自己的AI。同时,文章还提出了课后练习,鼓励读者深入探索llama_index的生态和功能,以及思考该库在其他领域的应用。
《AI 大模型之美》,新⼈⾸单¥68

全部留言(72)
- 最新
- 精选
 Owen置顶截止到目前,最新能运行的代码 ''' 归纳总结文章内容 ''' from langchain.chat_models import ChatOpenAI from langchain.text_splitter import SpacyTextSplitter from llama_index.core import SummaryIndex, ServiceContext, SimpleDirectoryReader from llama_index.core.node_parser import SentenceSplitter documents = SimpleDirectoryReader(input_dir="data").load_data() # 只能填写文件夹,不能具体到文件 service_context = ServiceContext.from_defaults( llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1000, n=1), node_parser=SentenceSplitter(chunk_size=512, chunk_overlap=20), ) index = SummaryIndex.from_documents(documents = documents, service_context = service_context) query_engine = index.as_query_engine() response = query_engine.query("用中文总结这个故事") print(response)2024-03-01归属地:广东2
Owen置顶截止到目前,最新能运行的代码 ''' 归纳总结文章内容 ''' from langchain.chat_models import ChatOpenAI from langchain.text_splitter import SpacyTextSplitter from llama_index.core import SummaryIndex, ServiceContext, SimpleDirectoryReader from llama_index.core.node_parser import SentenceSplitter documents = SimpleDirectoryReader(input_dir="data").load_data() # 只能填写文件夹,不能具体到文件 service_context = ServiceContext.from_defaults( llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1000, n=1), node_parser=SentenceSplitter(chunk_size=512, chunk_overlap=20), ) index = SummaryIndex.from_documents(documents = documents, service_context = service_context) query_engine = index.as_query_engine() response = query_engine.query("用中文总结这个故事") print(response)2024-03-01归属地:广东2 Penguin Shi置顶《藤野先生》输出摘要的代码,因为代码更新,有bug,参考https://gpt-index.readthedocs.io/en/latest/guides/primer/usage_pattern.html更新代码如下: from langchain.chat_models import ChatOpenAI from langchain.text_splitter import SpacyTextSplitter from llama_index import ListIndex, LLMPredictor, ServiceContext from llama_index import ( VectorStoreIndex, get_response_synthesizer, ) from llama_index.retrievers import VectorIndexRetriever from llama_index.query_engine import RetrieverQueryEngine from llama_index.node_parser import SimpleNodeParser # define LLM llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024)) text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048) parser = SimpleNodeParser(text_splitter=text_splitter) documents = SimpleDirectoryReader('./data/mr_fujino').load_data() index = ListIndex.from_documents(documents) retriever = index.as_retriever() query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='tree_summarize') response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:") print(response) 另目前文档中,"我把从网上找到的《藤野先生》这篇文章变成了一个 txt 文件,放在了 data/mr_fujino 这个目录下。我们的代码也非常简单,一共没有几行。"此文字下方代码的,第7行,index = GPTSimpleVectorIndex.from_documents(documents)中,“GPTSimpleVectorIndex”还未改成“GPTVectorStoreIndex” ;第9行,更改为index.storage_context.persist('index_mr_fujino')。 请更改,方便后续同学学习并运行代码。2023-07-09归属地:广东7
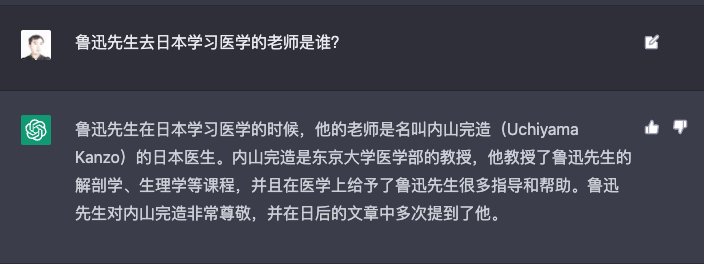
Penguin Shi置顶《藤野先生》输出摘要的代码,因为代码更新,有bug,参考https://gpt-index.readthedocs.io/en/latest/guides/primer/usage_pattern.html更新代码如下: from langchain.chat_models import ChatOpenAI from langchain.text_splitter import SpacyTextSplitter from llama_index import ListIndex, LLMPredictor, ServiceContext from llama_index import ( VectorStoreIndex, get_response_synthesizer, ) from llama_index.retrievers import VectorIndexRetriever from llama_index.query_engine import RetrieverQueryEngine from llama_index.node_parser import SimpleNodeParser # define LLM llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024)) text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048) parser = SimpleNodeParser(text_splitter=text_splitter) documents = SimpleDirectoryReader('./data/mr_fujino').load_data() index = ListIndex.from_documents(documents) retriever = index.as_retriever() query_engine = RetrieverQueryEngine.from_args(retriever, response_mode='tree_summarize') response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:") print(response) 另目前文档中,"我把从网上找到的《藤野先生》这篇文章变成了一个 txt 文件,放在了 data/mr_fujino 这个目录下。我们的代码也非常简单,一共没有几行。"此文字下方代码的,第7行,index = GPTSimpleVectorIndex.from_documents(documents)中,“GPTSimpleVectorIndex”还未改成“GPTVectorStoreIndex” ;第9行,更改为index.storage_context.persist('index_mr_fujino')。 请更改,方便后续同学学习并运行代码。2023-07-09归属地:广东7- Wise在llama_index V0.6.1 版本中,没有GPTSimpleVectorIndex 类了 import openai, os from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader os.environ["OPENAI_API_KEY"] = '' # 加载 documents documents = SimpleDirectoryReader('./data/mr_fujino').load_data() index = GPTVectorStoreIndex.from_documents(documents) index.storage_context.persist('index_mr_fujino') # 从磁盘重新加载: from llama_index import StorageContext, load_index_from_storage # rebuild storage context storage_context = StorageContext.from_defaults(persist_dir="./index_mr_fujino") # load index index = load_index_from_storage(storage_context) query_engine = index.as_query_engine() response = query_engine.query("鲁迅先生在日本学习医学的老师是谁?") print(response) 参考官方文档连接:https://gpt-index.readthedocs.io/en/latest/getting_started/starter_example.html
作者回复: 👍 如果还想要用0.5.x运行,参看以下 “llama index 最近又更新了大版本,接口又改了一遍。如果要立刻可以运行,可以先 pip install --force-reinstall -v "llama-index==0.5.27" 退回到 0.5 系列的版本” 晚点我看一下更新代码到0.6.x 版本
2023-05-07归属地:黑龙江520 - hello想请教下老师,我们喂的语料,会被其他人看到使用吗?
作者回复: 根据OpenAI的协议 1. 通过ChatGPT界面提交的会被内部看到,审核,并用于训练 2. 通过API提交的不会用于训练
2023-04-06归属地:湖南413  daz2yy老师,请问下一个问题,我把它用作 QA 系统的时候有个问题,原本 QA 就有标准的回答模版,里面包括有文档地址、操作步骤等;如果让 GPT 根据这个模版来回答问题,他会自由发挥,会漏掉一部分内容;想拥有 AI 自由对话的能力,又想有固定的回答模版这个怎么能较好的兼顾呢?
daz2yy老师,请问下一个问题,我把它用作 QA 系统的时候有个问题,原本 QA 就有标准的回答模版,里面包括有文档地址、操作步骤等;如果让 GPT 根据这个模版来回答问题,他会自由发挥,会漏掉一部分内容;想拥有 AI 自由对话的能力,又想有固定的回答模版这个怎么能较好的兼顾呢?作者回复: 可以通过Few-Shot的方式,在Prompt里面给AI一些例子,类似于下面这样,具体Prompt你自己调了多试一下。 ==== 我们的问题一般用这样的格式回答: 问题:blablabla 回答: 1. 文档地址 blabla 2. 操作步骤 blabla === 以下是上下文 {context_str} 问题:{question_str} 回答:
2023-04-04归属地:广东9 马听分享一个加载MySQL数据的例子: from llama_index import GPTSimpleVectorIndex,download_loader DatabaseReader = download_loader('DatabaseReader') reader = DatabaseReader( scheme = "mysql", # Database Scheme host = "localhost", # Database Host port = "3306", # Database Port user = "martin", # Database User password = "xxxxxx", # Database Password dbname = "martin", # Database Name ) query = f""" select * from student_info """ documents = reader.load_data(query=query) print(documents)
马听分享一个加载MySQL数据的例子: from llama_index import GPTSimpleVectorIndex,download_loader DatabaseReader = download_loader('DatabaseReader') reader = DatabaseReader( scheme = "mysql", # Database Scheme host = "localhost", # Database Host port = "3306", # Database Port user = "martin", # Database User password = "xxxxxx", # Database Password dbname = "martin", # Database Name ) query = f""" select * from student_info """ documents = reader.load_data(query=query) print(documents)作者回复: 👍
2023-04-12归属地:上海38 Terry
Terry 老师,请教一下langchain我理解也是一个LLM应用框架,它的功能和版本也更新很快。它和llama_index的区分是什么?在LLM应用开发上,我们一般怎么选择会比较好?
老师,请教一下langchain我理解也是一个LLM应用框架,它的功能和版本也更新很快。它和llama_index的区分是什么?在LLM应用开发上,我们一般怎么选择会比较好?作者回复: llama_index的重点放在了Index上,也就是通过各种方式为文本建立索引,有通过LLM的,也有很多并非和LLM相关的。 langchain的重点在 agent 和 chain 上,也就是流程组合上。 可以根据你的应用组合两个,如果你觉得问答效果不好,可以多研究一下llama-index。如果你希望有更多外部工具或者复杂流程可以用,可以多研究一下langchain。
2023-04-25归属地:浙江7 Oxygen Au 昕response = list_index.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:", response_mode="tree_summarize") print(response) 上面这段代码报错,AttributeError: 'GPTListIndex' object has no attribute 'query' , 我用的是llama-index 0.6.1 下面是正确的代码 query_engine = list_index.as_query_engine(response_mode="tree_summarize") response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:") print(response) 结果: 鲁迅先生在日本学习医学时遇到了藤野严九郎教授,他很有学问,对学生也很关心,甚至帮助鲁迅修改讲义。但鲁迅当时不够用功,有时也很任性。在学习中,他遇到了一些困难和不愉快的事情,最终决定离开医学去学习生物学。离开前,藤野先生送给他一张照片,并希望他能保持联系。鲁迅很久没有和任何人通信,但想起了这位热心的老师,他的照片挂在鲁迅的房间里,每当他疲倦时看到照片就会感到勇气和良心发现。
Oxygen Au 昕response = list_index.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:", response_mode="tree_summarize") print(response) 上面这段代码报错,AttributeError: 'GPTListIndex' object has no attribute 'query' , 我用的是llama-index 0.6.1 下面是正确的代码 query_engine = list_index.as_query_engine(response_mode="tree_summarize") response = query_engine.query("下面鲁迅先生以第一人称‘我’写的内容,请你用中文总结一下:") print(response) 结果: 鲁迅先生在日本学习医学时遇到了藤野严九郎教授,他很有学问,对学生也很关心,甚至帮助鲁迅修改讲义。但鲁迅当时不够用功,有时也很任性。在学习中,他遇到了一些困难和不愉快的事情,最终决定离开医学去学习生物学。离开前,藤野先生送给他一张照片,并希望他能保持联系。鲁迅很久没有和任何人通信,但想起了这位热心的老师,他的照片挂在鲁迅的房间里,每当他疲倦时看到照片就会感到勇气和良心发现。作者回复: llama index 最近又更新了大版本,接口又改了一遍。如果要立刻可以运行,可以先 pip install --force-reinstall -v "llama-index==0.5.27" 退回到 0.5 系列的版本 晚点我看一下更新代码到0.6.x 版本
2023-05-09归属地:美国5 勇.Max上面from llama_index import GPTSimpleVectorIndex会报错,因为现在已经改成了GPTVectorStoreIndex。 from llama_index import GPTVectorStoreIndex //老师看到后可以更新下
勇.Max上面from llama_index import GPTSimpleVectorIndex会报错,因为现在已经改成了GPTVectorStoreIndex。 from llama_index import GPTVectorStoreIndex //老师看到后可以更新下编辑回复: 收到,马上更新,感谢提醒🌹
2023-05-08归属地:北京32 Viola有同学遇到吗? type object 'GPTSimpleVectorIndex' has no attribute 'from_documents'
Viola有同学遇到吗? type object 'GPTSimpleVectorIndex' has no attribute 'from_documents'作者回复: 更新一下 llama-index 的版本,llama-index的接口从 0.4 到 0.5 做了比较大的更新。这一讲的内容,也是根据 0.5 的更新重新改过的。用最新版吧。 pip install -U llama-index
2023-04-05归属地:摩尔多瓦22

