

27|应用内存管理:Linux的应用与内存管理
LMOS

你好,我是 LMOS。
前面几节课我们学了不少内存相关的基础知识,今天我们来研究一下应用程序的内存管理。
应用程序想要使用内存,必须得先找操作系统申请,我们有必要先了解一下 Linux 内核怎么来管理内存,这样再去分析应用程序的内存管理细节的时候,思路才更顺畅。
之后,我还选择了现在最流行的 Golang 语言作为参考,带你梳理内存管理中各式各样的数据结构,为你揭秘 Golang 为什么能够实现高效、自动化地管理内存。
这节课的配套代码,你可以从这里下载。让我们进入正题吧!
硬件架构
现代计算机体系结构被称为 Non-Uniform Memory Access(NUMA),NUMA 下物理内存是分布式的,由多个计算节点组成,每个 CPU 核都会有自己的本地内存。CPU 在访问它的本地内存的时候就比较快,访问其他 CPU 核内存的时候就比较慢。
我们最熟悉的 PC 机和手机,就可以看作是只有一个计算节点的 NUMA,这算是 NUMA 中的特例,我来为你画一幅逻辑视图,你一看就明白了,如下图所示:
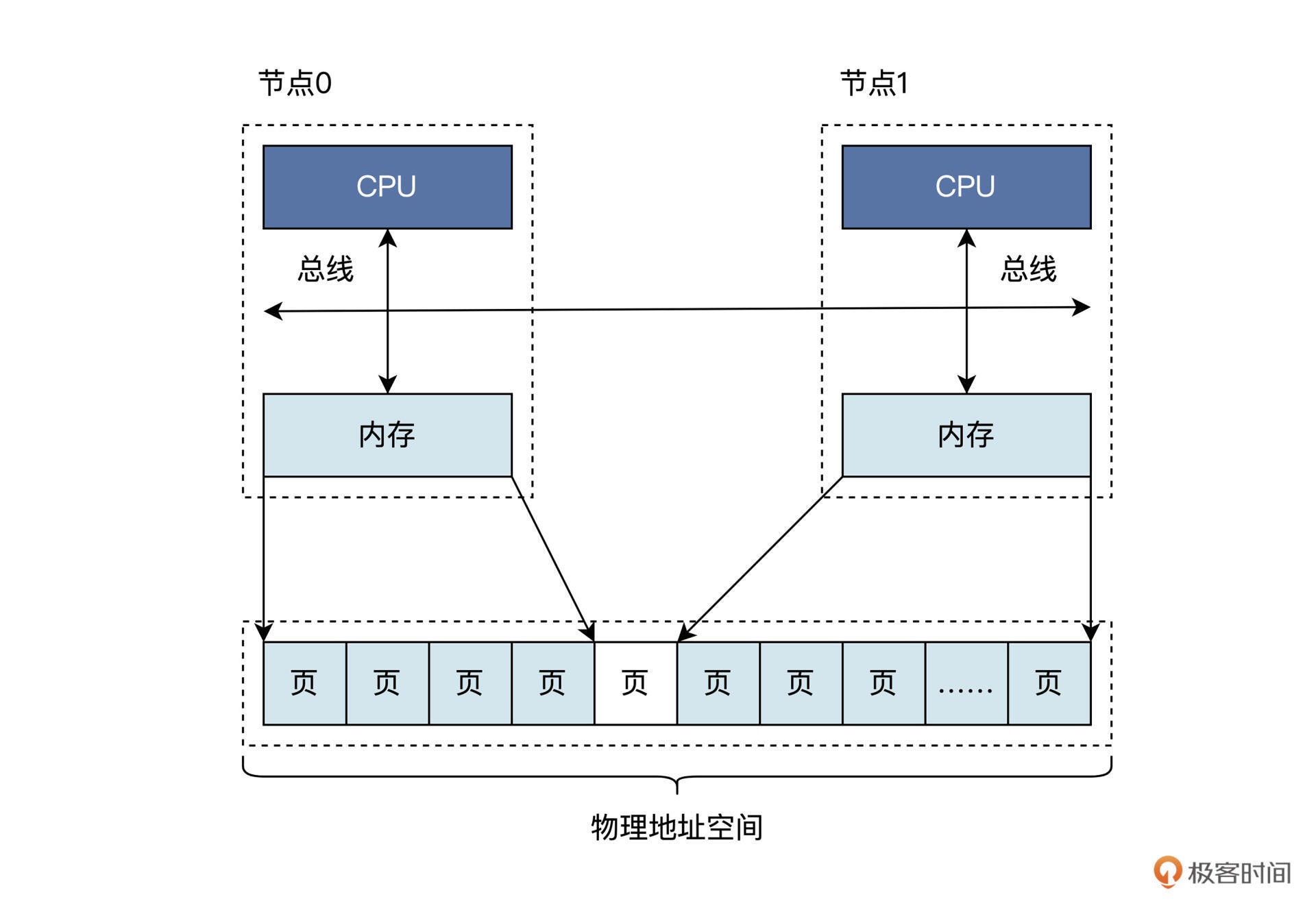
我们看到每个节点都是由 CPU、总线、内存组成的。节点之间的内存大小可能不同,但是这些内存都是统一编址到同一个物理地址空间中的,即无论是节点 0 的内存还是节点 1 的内存都有唯一的物理地址,在一个节点内部的物理内存之间可能存在空洞,节点和节点间的物理内存页可能有空洞。何谓地址空洞?就是这一段地址是不对应到内存单元里的。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了Linux和Golang的内存管理,重点介绍了Linux在NUMA硬件架构上的物理内存管理和Golang内存管理的相关数据结构。文章首先解释了NUMA架构的节点内存和节点间内存的访问速度差异,然后详细讨论了Linux的物理内存管理,包括pglist_data、zone、free_area等数据结构的使用和内存分配释放过程。接着,文章介绍了Golang语言的基本情况和历史,并解释了Golang运行时的内存空间结构和内存管理数据结构,如mheap、heapArena、mcentral、mcache、mspan等。通过代码示例展示了Golang运行时对内存的管理过程。 文章重点介绍了Golang运行时内存管理的基本单元mspan的数据结构,包括其内部字段和对应的对象分配情况。通过代码示例和图示,详细解释了mspan中对象的大小、数量以及位图的使用情况。此外,还介绍了spanClass类型的数组索引和对应的对象大小、占用页面数等数据,以及一个方便观察的数据表,展示了不同对象大小对应的mspan大小、对象数量等信息。最后,提到了mcache数据结构,为读者引出了下一个问题的探索方向。 整体而言,本文对于想深入了解Linux和Golang内存管理的技术人员具有重要参考价值,尤其适合对内存管理感兴趣的读者阅读。文章通过详细的数据结构介绍和代码示例,使读者能够快速了解Golang运行时内存管理的核心概念和实现细节。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《计算机基础实战课》,新⼈⾸单¥68
《计算机基础实战课》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(6)
- 最新
- 精选
 苏流郁宓mcentral位于中心位置,资源需要加锁解锁排队等待,在单核中另不另开mcache无所谓,但是在多核中则开mcache更好(方便并发),一个操作系统中的mcentral实运行线程(协程)只有一组(存在一个线程)?但多核下mcache实运行的线程(协程)可以有多组(看有多少核)? 由于8kb组成的虚拟分页模型(形成连续页,实际内存中是把两个不靠在一起的4kb页拼接成8kb?还是需要连续分页2个4kb?)但一般操作系统4kb或2M,4M分页,go的分页基于操作系统的支持! go分页的优点是一整页数据都可以是它的,方便管理(减少cpu不同模式指令的切换),缺点是对设备的性能提出要求(虽然现在不是事,但嵌入式领域很多cpu真的垃圾,比如一些家用电器等)!还有go的分页模型不大利于对内存数据的实时动态刷新!
苏流郁宓mcentral位于中心位置,资源需要加锁解锁排队等待,在单核中另不另开mcache无所谓,但是在多核中则开mcache更好(方便并发),一个操作系统中的mcentral实运行线程(协程)只有一组(存在一个线程)?但多核下mcache实运行的线程(协程)可以有多组(看有多少核)? 由于8kb组成的虚拟分页模型(形成连续页,实际内存中是把两个不靠在一起的4kb页拼接成8kb?还是需要连续分页2个4kb?)但一般操作系统4kb或2M,4M分页,go的分页基于操作系统的支持! go分页的优点是一整页数据都可以是它的,方便管理(减少cpu不同模式指令的切换),缺点是对设备的性能提出要求(虽然现在不是事,但嵌入式领域很多cpu真的垃圾,比如一些家用电器等)!还有go的分页模型不大利于对内存数据的实时动态刷新!作者回复: 是的 你理解正确
2022-09-27归属地:湖北3
 TableBear
TableBear 课后思考题: mcentral结构是全局共享的,多协程访问需要竞争锁。mcache是P独有的结构访问时可以不需要竞争锁。mcache结构提前从mcentral中获取mspan结构,后序的分配内存操作就可以不需要竞争锁可以加快内存的分配。 问一个课程无关的问题: 老师用的画图软件是什么能分享一下名字吗😂
课后思考题: mcentral结构是全局共享的,多协程访问需要竞争锁。mcache是P独有的结构访问时可以不需要竞争锁。mcache结构提前从mcentral中获取mspan结构,后序的分配内存操作就可以不需要竞争锁可以加快内存的分配。 问一个课程无关的问题: 老师用的画图软件是什么能分享一下名字吗😂作者回复: drawio
2022-09-26归属地:湖北22 peter请教老师几个问题: Q1:NUMA是针对CPU还是CPU核? 我刚看过一篇博客,该博客多次强调NUMA是针对物理CPU,不是针对CPU核的;比如一个计算机有一个CPU,8个核,则NUMA是这对这一个CPU,而不是针对这8个核的。但本文 (第27课) 中有一句话“NUMA 下物理内存是分布式的,由多个计算节点组成,每个 CPU 核都会有自己的本地内存”,这句话强调“每个CPU核”。 Q2:单独一台电脑每个核有自己的内存吗? 单独一台计算机,比如我用的笔记本电脑,惠普笔记本,win10,只有一个CPU(Intel i7),该CPU有8核,内存16G(原配8G,后增加8G)。请问:我的笔记本,每个CPU核都有自己的本地内存吗? Q3:地址空洞的“对应”怎么理解? 文中的第一个图中,有“物理地址空间”和“内存”这两个术语;文中提到“何谓地址空洞?就是这一段地址是不对应到内存单元里的”。这个“对应”是指“物理地址空间”中的某一段地址,实际上并没有对应的“内存”,是吗? Q4:NUMA是针对CPU的个数。 情况1:如果是计算机集群,有多台计算机,肯定是多个CPU,所以是NAMA。情况2:如果是一台计算机,但是有两个或两个以上的CPU(每个CPU有多个核),则也是NUMA。情况3:如果是一台计算机,而且只有一个CPU(但有多个核),比如最常见的个人计算机,则此时不是NUMA,可以忽略NUMA,当做非NUMA处理。 我的理解是否对?(这里所说的三种情况都是用Linux) Q5:一台计算机上,每个Go应用都有一个独立的Go运行时吗? 还是说“在一台计算机上,所有的Go应用都共享同一个Go运行时”? Q6:malloc分配以后,会立即分配物理内存吗?
peter请教老师几个问题: Q1:NUMA是针对CPU还是CPU核? 我刚看过一篇博客,该博客多次强调NUMA是针对物理CPU,不是针对CPU核的;比如一个计算机有一个CPU,8个核,则NUMA是这对这一个CPU,而不是针对这8个核的。但本文 (第27课) 中有一句话“NUMA 下物理内存是分布式的,由多个计算节点组成,每个 CPU 核都会有自己的本地内存”,这句话强调“每个CPU核”。 Q2:单独一台电脑每个核有自己的内存吗? 单独一台计算机,比如我用的笔记本电脑,惠普笔记本,win10,只有一个CPU(Intel i7),该CPU有8核,内存16G(原配8G,后增加8G)。请问:我的笔记本,每个CPU核都有自己的本地内存吗? Q3:地址空洞的“对应”怎么理解? 文中的第一个图中,有“物理地址空间”和“内存”这两个术语;文中提到“何谓地址空洞?就是这一段地址是不对应到内存单元里的”。这个“对应”是指“物理地址空间”中的某一段地址,实际上并没有对应的“内存”,是吗? Q4:NUMA是针对CPU的个数。 情况1:如果是计算机集群,有多台计算机,肯定是多个CPU,所以是NAMA。情况2:如果是一台计算机,但是有两个或两个以上的CPU(每个CPU有多个核),则也是NUMA。情况3:如果是一台计算机,而且只有一个CPU(但有多个核),比如最常见的个人计算机,则此时不是NUMA,可以忽略NUMA,当做非NUMA处理。 我的理解是否对?(这里所说的三种情况都是用Linux) Q5:一台计算机上,每个Go应用都有一个独立的Go运行时吗? 还是说“在一台计算机上,所有的Go应用都共享同一个Go运行时”? Q6:malloc分配以后,会立即分配物理内存吗?作者回复: Q1 是针对 物理 CPU smp也可以是逻辑上的NUMA Q2 可以有也可以没有 Q3 是的 Q4 是对的 Q5 共享的 Q6 不 会
2022-09-27归属地:湖北2 青玉白露当初学的手写操作系统的知识,嘿嘿2023-01-25归属地:四川1
青玉白露当初学的手写操作系统的知识,嘿嘿2023-01-25归属地:四川1 blue mountain咨询下老师 1. 文章中提到的 tiny(16B) 或者 huge(32KB) 的场景,回收的时候就不是用这个垃圾回收器去回收?2023-08-18归属地:浙江
blue mountain咨询下老师 1. 文章中提到的 tiny(16B) 或者 huge(32KB) 的场景,回收的时候就不是用这个垃圾回收器去回收?2023-08-18归属地:浙江- bomberGMP 的 P 结构其实有三个队列,除了文中提到的本地和全局队列以外,还有一个最高优先级 runnext,其中三个队列其实作用和角色有些不一样. 他们三个的调度关系是依靠 schedtick 来表示当前处理的循环次数,每次循环会自增,然后 runtime 的调度器用这个值取模 61 来判断当前是否该处理 global 的 G: 1. 如果等于 0 了就会去全局队列里获取,但每次只会在全局里拿一个给 M,然后 back. 2. 如果模 61 不等于 0 就是正常流程,即判断 runnext 是否有 G,有 G 就直接执行 runnext 的然后 back. 3. 如果 runtime 没有 G 就去 local,如果 local 非空就拿一个给 M 执行,然后back. 4. 如果 local 里也是空的就去全局队列里找,如果非空会尽量拿 128 个,然后单独执行头部第一个,之后其他的放到 local 里,然后 back. 5. 如果 global 里都是空的,说明当前 P 里 runnext 和 local 以及全局都为空.此时就随机(伪随机,是在 P 总数中找一个质数,用这个质数不断地做加法来实现一个伪随机.)去其他的 P 里的 local 里的尾部直接偷一半的 G,并且从最后一个 G 开始执行,其他的 G 到自己的 local 中. 此外其实还有一个小插曲,早期版本中 time.Sleep 等待时间的实现是简单的依赖 goroutine 的,即处理 time.Sleep 的时候会作为 runnext 插入进来. 所以在 runtime.GOMAXPROCS 设置成 1,并开启尽量多的 goroutine 后(比如 for),就会一直有一部分的 goroutine 一直在等待 time.Sleep 结束让出 runnext.不过好在 1.14.x 的 go 已经不再让 time.Sleep 占用 runnext 了,如果你用的版本低于 1.14 请知悉这个问题或升级2023-02-20归属地:上海
收起评论