

06|手写CPU(一):迷你CPU架构设计与取指令实现
LMOS

你好,我是 LMOS。
经过上一节课的学习,我们已经知道了一个基于 RISC-V 指令集设计的 CPU,必须要实现哪些指令。从这节课开始,我们就可以着手设计和实现 MiniCPU 了。
我会先跟你讲讲什么是流水线,在 CPU 中使用流水线的好处是什么?然后,我们再以经典的五级流水线为例,讲解 CPU 流水线的五个阶段。接着设计出我们 MiniCPU 的总体结构,并根据规划的五级流水线,完成流水线的第一步——取指模块的设计。课程的配套代码可以从这里下载。
话不多说,让我们正式开始今天的学习吧。
什么是 CPU 流水线?
说到流水线,你是否会马上想到我们打工人的工厂流水线?没错,高大上的 CPU 流水线其实和我们打工人的流水线是一样的。
假如我们在冰墩墩工厂上班,生产流水线分为五个步骤,如下图所示:
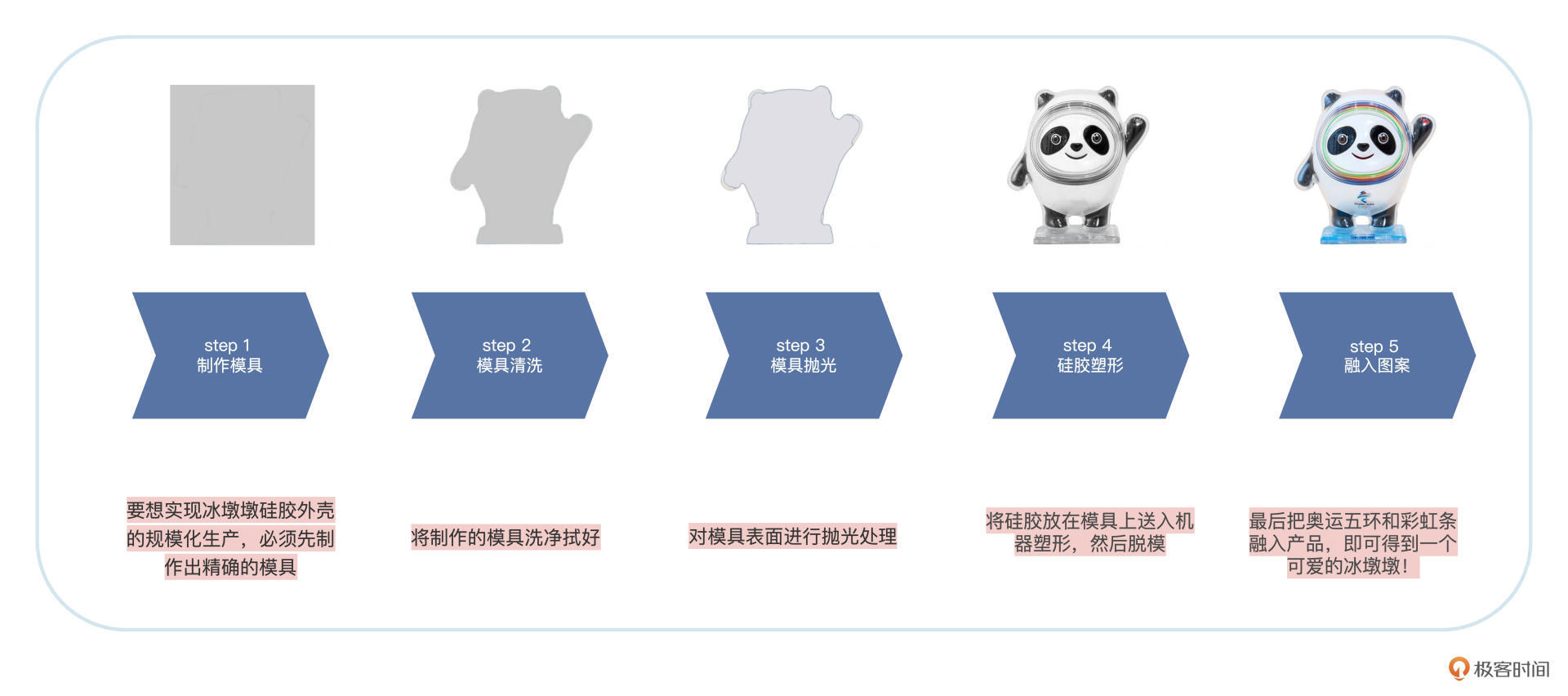
在冰墩墩生产线上需要至少五个工人,各自负责模具制作、模具清洗、模具抛光、硅胶塑形和融入图案这五个环节中的一个。最简单的方法自然是:同一时刻只有一个冰墩墩在制作。但是冬奥会的热度让市场上的冰墩墩供应不足,为了早日实现“人手一墩”的目标,有什么提升生产效率的办法呢?
稍微想想就知道,生产线上一个人在制作冰墩墩的时候,另外四个工人都处于空闲状态,显然这是对人力资源的极大浪费。想要提高效率,我们不妨在第一个冰墩墩模具制作出来进入清洗阶段的时候,马上开始进行第二个冰墩墩模具的制作,而不是等到第一个冰墩墩全部步骤做完后,才开始制作下一个。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了基于RISC-V指令集的MiniCPU的设计与实现,重点围绕CPU流水线的原理和MiniCPU的架构设计展开。文章首先解释了CPU流水线的五个阶段,并详细介绍了MiniCPU的架构设计,包括各个单元模块的功能。重点阐述了MiniCPU中体现五级流水线的主要模块,如分支预测模块、取指通路模块、译码到执行之间的模块、指令执行模块和数据写回模块。此外,还详细讲解了取指模块的设计与实现,以及取指数据通路模块的功能和代码实现。整体而言,本文适合对计算机体系结构感兴趣的读者阅读,涵盖了硬件底层的CPU设计和实现细节,具有很高的参考价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《计算机基础实战课》,新⼈⾸单¥68
《计算机基础实战课》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(21)
- 最新
- 精选
 苏流郁宓预读取指令的好处是加强分支预测能力,减少无用功,但不仅仅于此,比如某些软件代码转汇编,为了对齐会增加一些无用的指令,比如x86的nop(它有时会夹在几个其它指令中),还有 复杂的指令可以通过微码进行转换为几个简单的指令,总之,cpu不是也不应该所有的指令全部都执行 预读取指令,有利于提高cpu效率,在一开始不执行浪费的时间好过cpu做到一半,才发现是无用的指令强的啊,还有部分条件指令,可以跳过不执行(比如c语言提高if的权重,降低else if的权重就是代码优化的方法),所以提高cpu效率在软硬件结合一起努力的啊 可以直接取指然后译码再执行,但那样效率会低很多!分支预测是配合cpu流水线工作的,主要是看应用场景,电脑手机等肯定用到分支预测等,但那些老旧或简单的计算器压根分支预测用不到呀 一句话:看应用场景再决定造什么样的cpu?
苏流郁宓预读取指令的好处是加强分支预测能力,减少无用功,但不仅仅于此,比如某些软件代码转汇编,为了对齐会增加一些无用的指令,比如x86的nop(它有时会夹在几个其它指令中),还有 复杂的指令可以通过微码进行转换为几个简单的指令,总之,cpu不是也不应该所有的指令全部都执行 预读取指令,有利于提高cpu效率,在一开始不执行浪费的时间好过cpu做到一半,才发现是无用的指令强的啊,还有部分条件指令,可以跳过不执行(比如c语言提高if的权重,降低else if的权重就是代码优化的方法),所以提高cpu效率在软硬件结合一起努力的啊 可以直接取指然后译码再执行,但那样效率会低很多!分支预测是配合cpu流水线工作的,主要是看应用场景,电脑手机等肯定用到分支预测等,但那些老旧或简单的计算器压根分支预测用不到呀 一句话:看应用场景再决定造什么样的cpu?作者回复: 正确
2022-08-08归属地:湖北12 =wire [31:0] adder = is_jal ? jimm : (is_bxx & bimm[31]) ? bimm : 4; assign pre_pc = pc + adder; 在计算指令地址偏移量的时候,为什么写is_bxx & bimm[31],而不是直接写is_bxx呢?
=wire [31:0] adder = is_jal ? jimm : (is_bxx & bimm[31]) ? bimm : 4; assign pre_pc = pc + adder; 在计算指令地址偏移量的时候,为什么写is_bxx & bimm[31],而不是直接写is_bxx呢?作者回复: 向前 向后 跳转
2022-08-08归属地:湖北43 伊宝峰对指令预读取,方便形成流水线,加快执行速度,因为从存储器中直接取指令会比较慢。
伊宝峰对指令预读取,方便形成流水线,加快执行速度,因为从存储器中直接取指令会比较慢。作者回复: 是的
2022-08-13归属地:湖北2 一笑千古老师,我想问一下为什么要将立即数的最高位复制以满足32位寄存器的长度要求
一笑千古老师,我想问一下为什么要将立即数的最高位复制以满足32位寄存器的长度要求作者回复: 因为数据是有符号的
2022-12-07归属地:湖北 一个要强的男人老师,请问:对于单核cpu的流水线来说,如果在译码阶段占满了这个时钟周期,那么如何在对下一个任务进行取指呢?还是说在设计之初已经确定这个时钟周期肯定能执行完4个操作。这是我的疑问,对于单核来说,并没有像工人的流水线(有五个人在工作),这种怎么理解呀,搜索了很多资料都在拿工厂的流水线打比喻,没搞明白。
一个要强的男人老师,请问:对于单核cpu的流水线来说,如果在译码阶段占满了这个时钟周期,那么如何在对下一个任务进行取指呢?还是说在设计之初已经确定这个时钟周期肯定能执行完4个操作。这是我的疑问,对于单核来说,并没有像工人的流水线(有五个人在工作),这种怎么理解呀,搜索了很多资料都在拿工厂的流水线打比喻,没搞明白。作者回复: 单核也是一样的 一个周期分成几个节拍 工作的
2022-12-01归属地:湖北2 雨巷请问老师,jalr指令没有进行分支预测是吧?
雨巷请问老师,jalr指令没有进行分支预测是吧?作者回复: 嗯嗯
2022-11-25归属地:湖北 小傅wire [31:0] bimm = {{20{instr[31]}}, instr[7], instr[30:25], instr[11:8], 1'b0}; 这句怎么理解呢,{20{instr[31]}}这又是什么意思呢?
小傅wire [31:0] bimm = {{20{instr[31]}}, instr[7], instr[30:25], instr[11:8], 1'b0}; 这句怎么理解呢,{20{instr[31]}}这又是什么意思呢?作者回复: 你学过verilog吗
2022-11-15归属地:湖北- Geek_489363根据b型指令的格式,为什么会有得到{{20{instr[31]}}, instr[7], instr[30:25], instr[11:8], 1'b0}?不是很理解
作者回复: b指令的数据格式 就是这样啊
2022-11-08归属地:湖北  吴建平确实少了一段代码,下面这部分,gitee也没有。而且输入in_pc_next也没有在模块定义里看到。我的理解是,pre_id是if_id的伴生电路,他们俩其实都属于取指阶段,逻辑上属于同一个时钟周期。正常情况下(流水线正常运作),每次时钟跳变,根据next读取新的指令,pre_id就算出下一条指令地址,此时if_id就用此输出作为in_pc_next输入。所以pre_id比if_id要快半个周期。 //下一条指令的PC always @(posedge clock) begin if (reset) begin reg_pc_next <= 32'h0; end else if (flush) begin reg_pc_next <= 32'h0; end else if (valid) begin reg_pc_next <= in_pc_next; end end
吴建平确实少了一段代码,下面这部分,gitee也没有。而且输入in_pc_next也没有在模块定义里看到。我的理解是,pre_id是if_id的伴生电路,他们俩其实都属于取指阶段,逻辑上属于同一个时钟周期。正常情况下(流水线正常运作),每次时钟跳变,根据next读取新的指令,pre_id就算出下一条指令地址,此时if_id就用此输出作为in_pc_next输入。所以pre_id比if_id要快半个周期。 //下一条指令的PC always @(posedge clock) begin if (reset) begin reg_pc_next <= 32'h0; end else if (flush) begin reg_pc_next <= 32'h0; end else if (valid) begin reg_pc_next <= in_pc_next; end end编辑回复: 你的留言我们已经收到,已经跟LMOS确认啦。if_id模块的设计,老师考虑到代码简洁一些有助于初学用户理解,最新一版Gitee代码里已经把这段删掉了,且并不影响整体的功能。你可以拉取一下最新的代码。
2022-08-23- 吴建平确实是少了一段代码,gitee下载的代码也没有。是reg_pc_next这部分,其输入不是out_pc_next
作者回复: 我看看
2022-08-23归属地:湖北
收起评论