

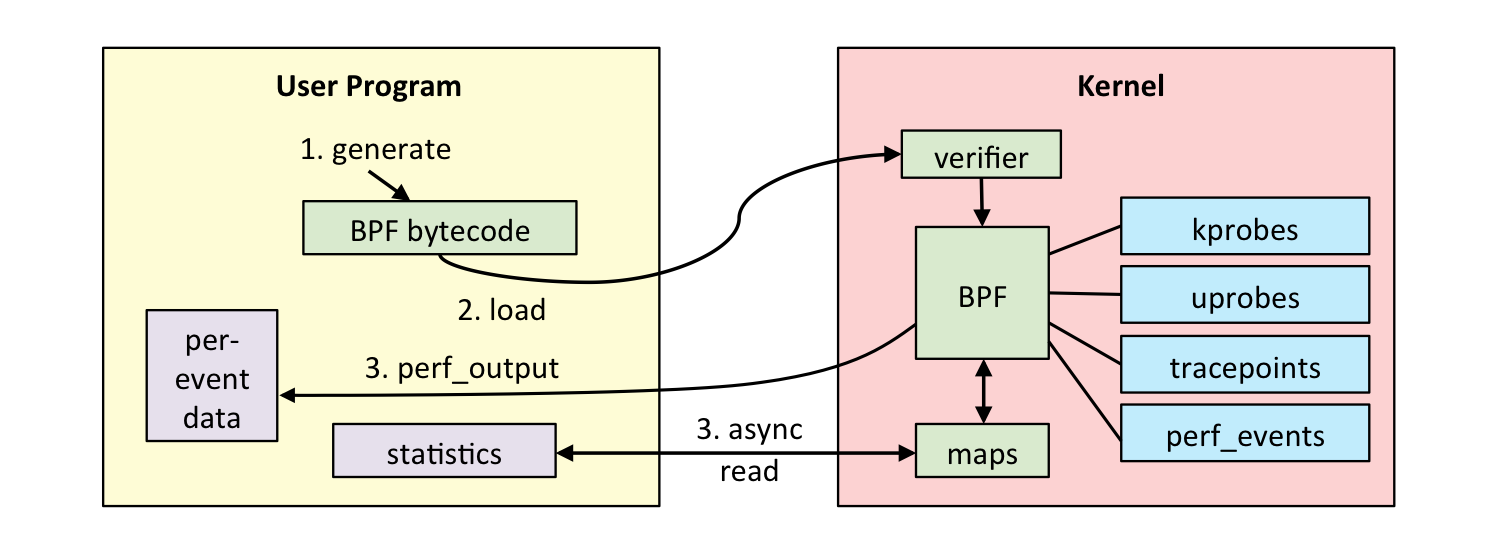
05 | 编程接口:eBPF程序是怎么跟内核进行交互的?

BPF 系统调用
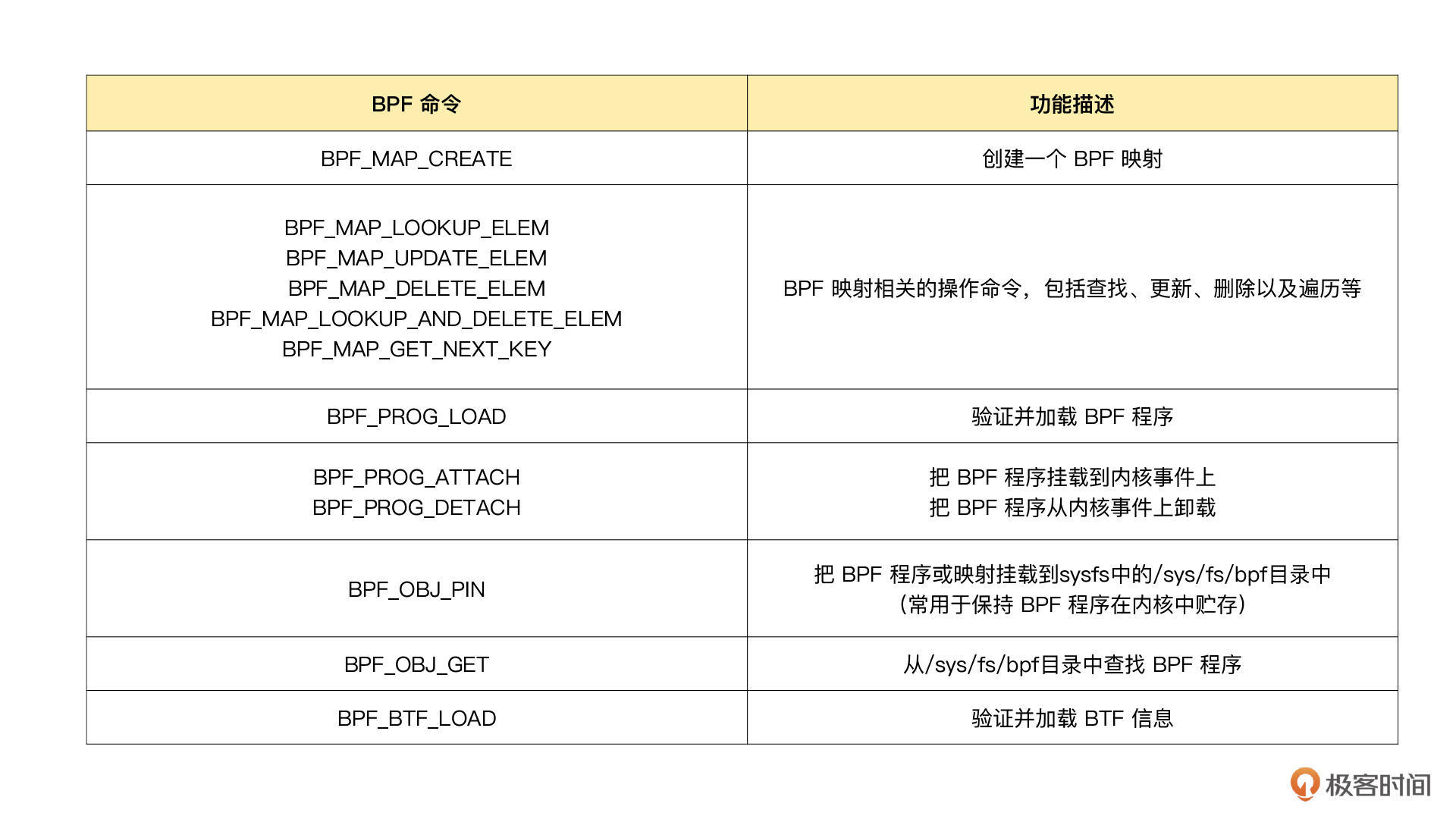
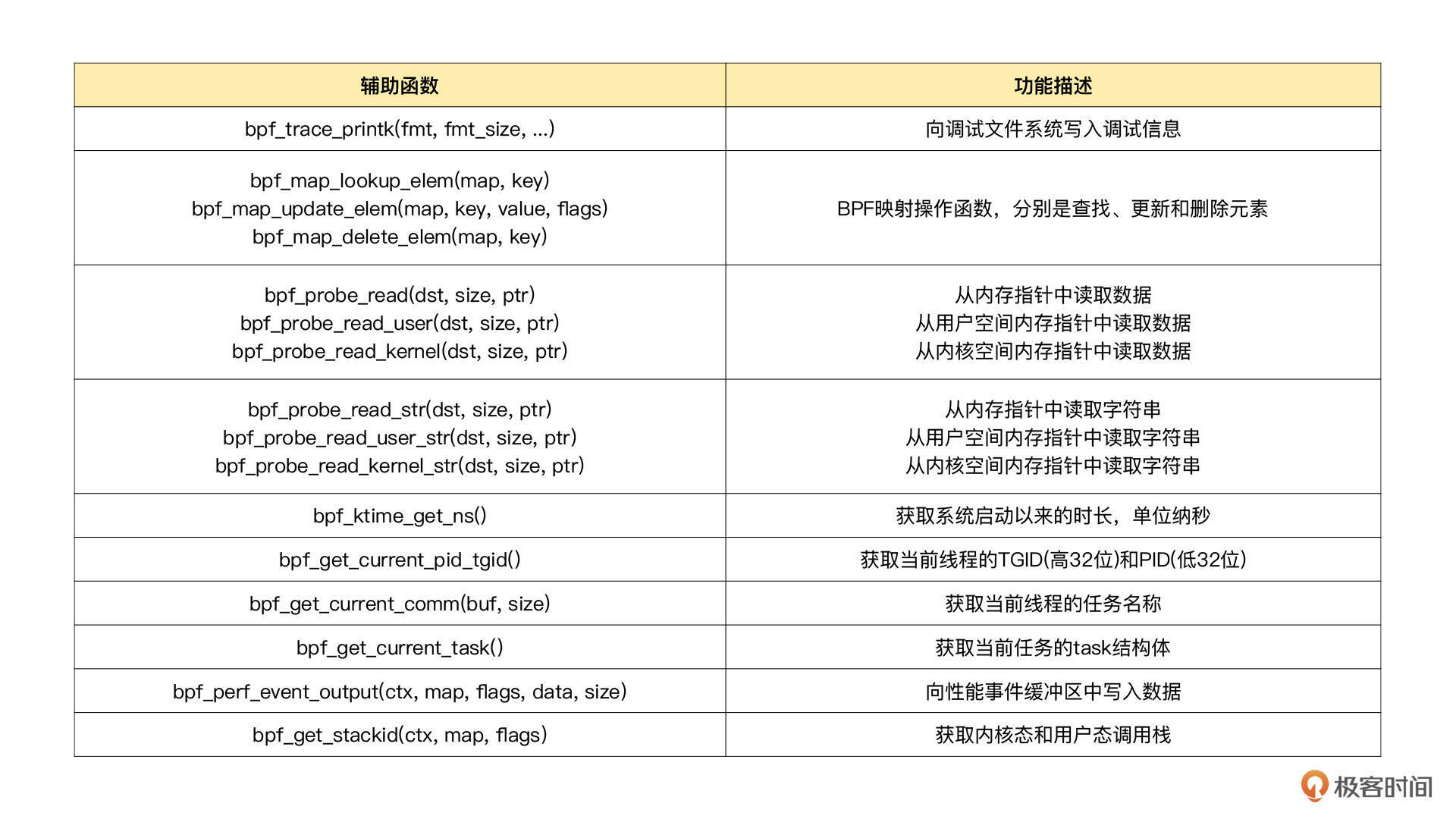
BPF 辅助函数
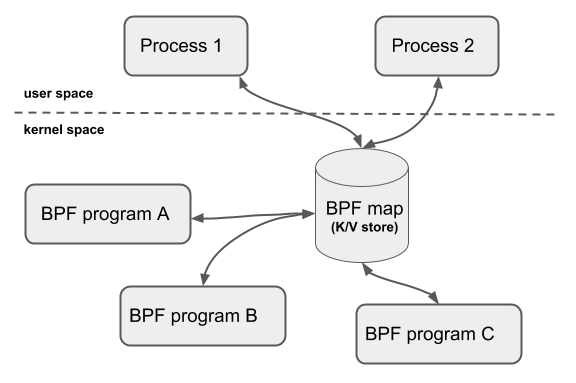
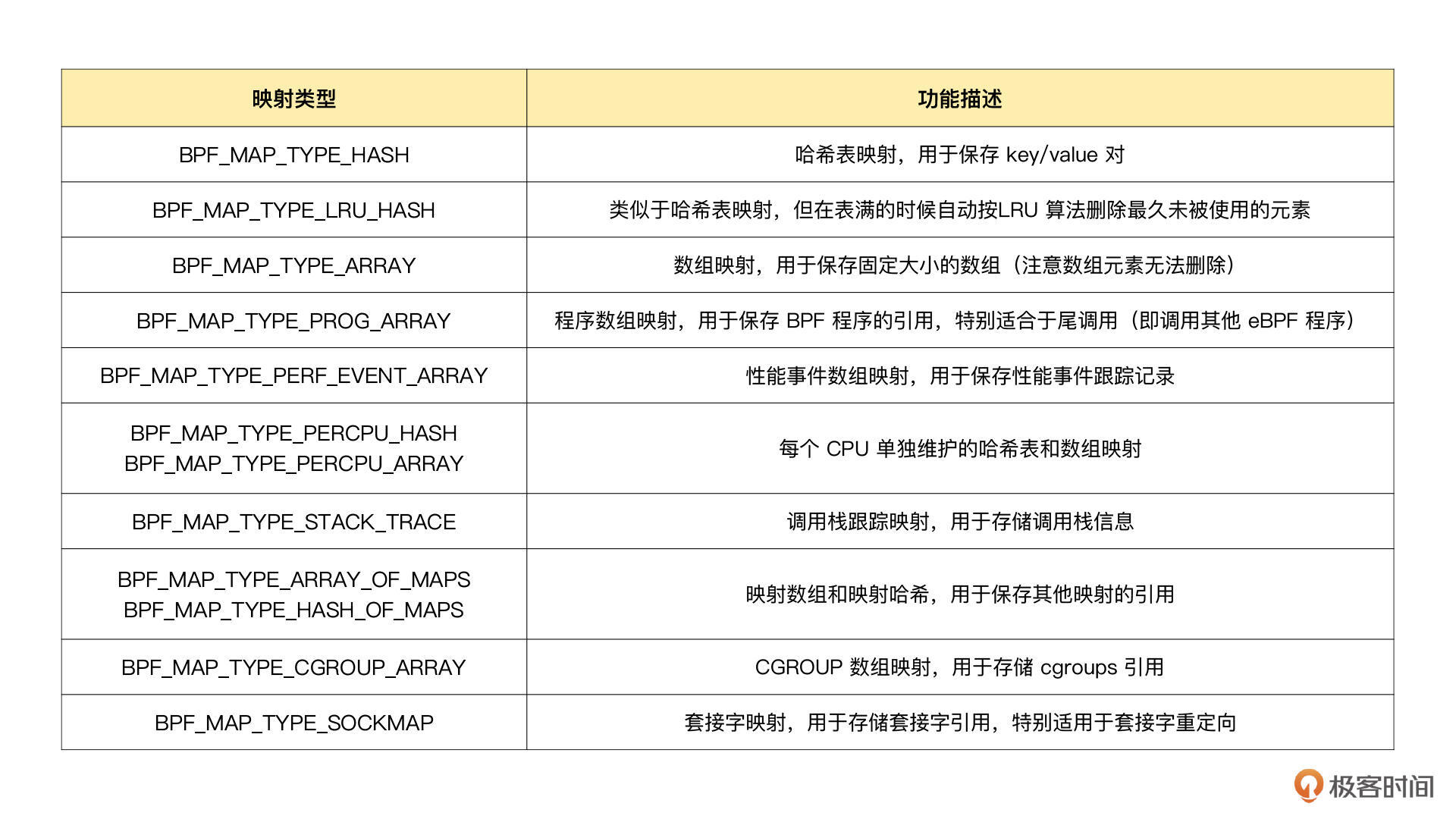
BPF 映射
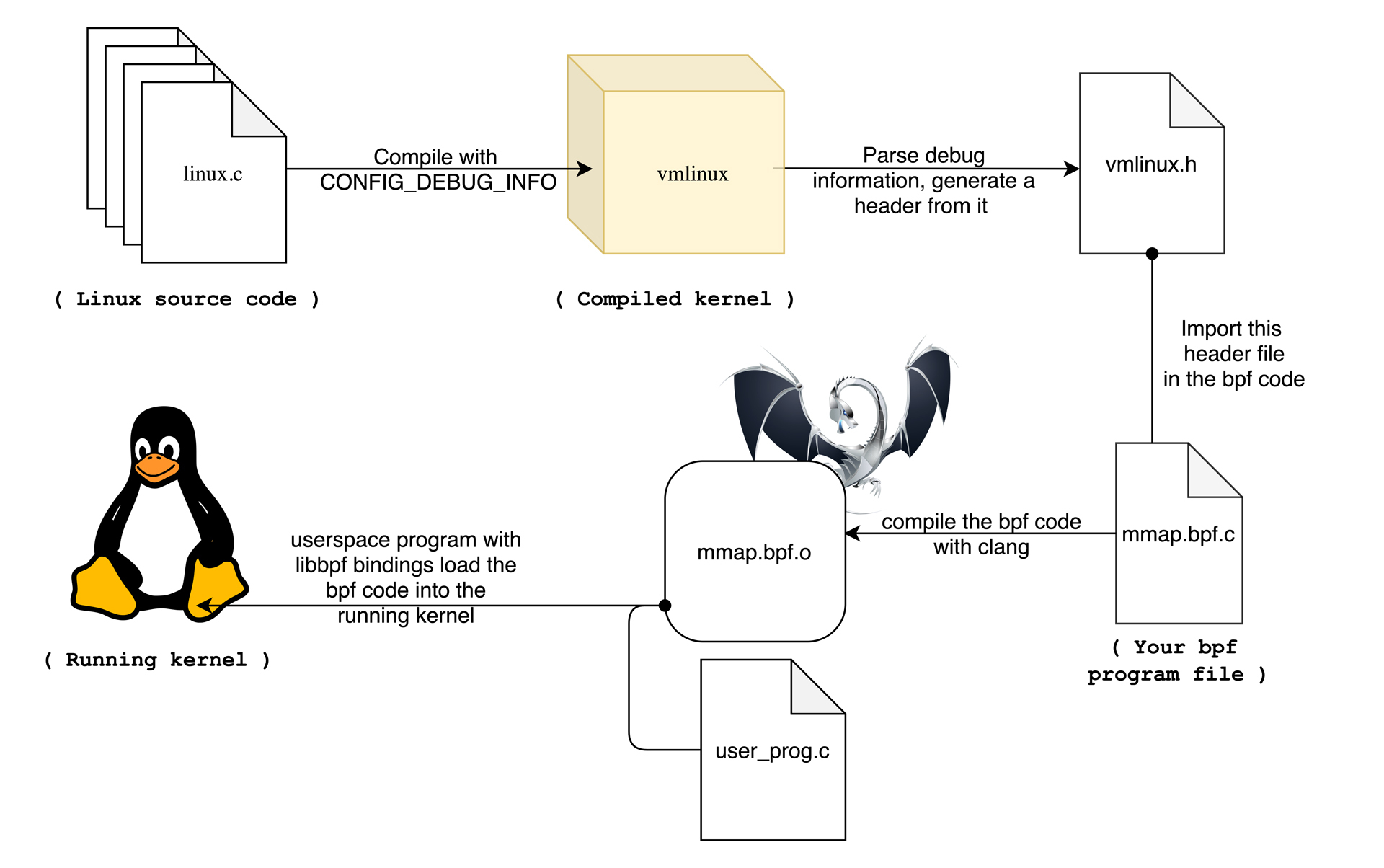
BPF 类型格式 (BTF)
小结
思考题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

eBPF程序与内核交互的编程接口是通过BPF系统调用和BPF辅助函数实现的。通过BPF系统调用,eBPF程序可以与内核进行交互,常用命令包括BPF_PROG_LOAD等。同时,内核定义了一系列辅助函数,如bpf_trace_printk(),用于eBPF程序与内核其他模块进行交互。此外,从内核5.13版本开始,部分内核函数也可以被BPF程序直接调用。然而,并非所有辅助函数都可以在eBPF程序中随意使用,不同类型的eBPF程序支持的辅助函数也不同。特别需要注意的是以bpf_probe_read开头的一系列函数,用于访问内核空间或用户空间地址。另外,当eBPF程序需要大块存储时,必须通过BPF映射(BPF Map)来完成。BPF映射用于提供大块的键值存储,这些存储可被用户空间程序访问,进而获取eBPF程序的运行状态。eBPF程序最多可以访问64个不同的BPF映射,并且不同的eBPF程序也可以通过相同的BPF映射来共享它们的状态。此外,文章还介绍了BPF类型格式(BTF)的作用,以及BTF和一次编译到处执行(CO-RE)项目对解决内核数据结构定义和兼容性问题的重要性。通过BTF,开发者可以更方便地获取内核数据结构的定义,而CO-RE项目则使得eBPF程序可以适配不同版本的内核。总的来说,本文通过介绍eBPF程序的编程接口,帮助读者快速了解eBPF程序与内核的交互方式,以及解决内核数据结构定义和兼容性问题的新方法。
2022-01-2616人觉得很赞给文章提建议
《eBPF 核心技术与实战》,新⼈⾸单¥59

全部留言(15)
- 最新
- 精选
 莫名倪老师留的思考题比较基础,尝试从另一个角度做下觉得有趣的对比: 1、bpf 系统调用一定程度上参考了 perf_event_open 设计,bpf_attr、perf_event_attr 均包含了大量 union,用于适配不同的 cmd 或者性能监控事件类型。因此,bpf、perf_event_open 接口看似简单,其实是大杂烩。 bpf(int cmd, union bpf_attr *attr, ...) perf_event_open(struct perf_event_attr *attr, ...) 2、bpftool 命令设计风格重度参考了 iproute2 软件包中的 ip 命令,用法基本上一致。 Usage: bpftool [OPTIONS] OBJECT { COMMAND | help } Usage: ip [ OPTIONS ] OBJECT { COMMAND | help } 无论内核开发还是工具开发,都可以看到设计思路借鉴的影子。工作之余不妨多些学习与思考,也许就可以把大师们比较好的设计思路随手用于手头的任务之中。
莫名倪老师留的思考题比较基础,尝试从另一个角度做下觉得有趣的对比: 1、bpf 系统调用一定程度上参考了 perf_event_open 设计,bpf_attr、perf_event_attr 均包含了大量 union,用于适配不同的 cmd 或者性能监控事件类型。因此,bpf、perf_event_open 接口看似简单,其实是大杂烩。 bpf(int cmd, union bpf_attr *attr, ...) perf_event_open(struct perf_event_attr *attr, ...) 2、bpftool 命令设计风格重度参考了 iproute2 软件包中的 ip 命令,用法基本上一致。 Usage: bpftool [OPTIONS] OBJECT { COMMAND | help } Usage: ip [ OPTIONS ] OBJECT { COMMAND | help } 无论内核开发还是工具开发,都可以看到设计思路借鉴的影子。工作之余不妨多些学习与思考,也许就可以把大师们比较好的设计思路随手用于手头的任务之中。作者回复: 非常棒的思考思路👍
2022-01-26232- Geek_e8988c飞哥,你好,看完前两章感觉比较迷糊。没能做到学以致用,或者说举一反三。 例如第一个ebpf程序,通过trace open系统调用来监控应用的open动作。 那我实际中,有没有什么快速的方案/套路来完成一些其他的trace,例如我想知道监控那些程序使用了socket/bind(尤其适用于有些短暂进程使用udp发送了一些报文就立马退出了)。 当我想新增一个trace事件,我的.c需要去包含那些头文件,我的.py需要跟踪那个系统调用。 这些头文件与系统调用在哪可以找到,如果去找? 希望飞哥大佬能给个大体的框架,思路,谢谢
作者回复: 非常欣慰你在看到一个入门示例就能思考这么多的问题。基础入门篇的内容主要侧重在 eBPF 本身,而其应用的方法都包含在实战进阶篇(其实看看目录就知道这些问题都包含在实战进阶篇中)。 不过既然问到了,我就提前先给你介绍一个方便的工具 https://github.com/iovisor/bpftrace。想你问到的查询跟踪点函数、查询系统调用格式、快速跟踪一个系统调用、网络socket的跟踪等等它都是支持的,并且用起来就像SHELL脚本一样方便。你可以先学习一下,我们后面的案例中还会讲到它的详细使用方法。
2022-01-268  写点啥呢想请教下老师关于bpf内核态程序的成名周期,比如前几节课的例子,如果我通过ctrl-c终端用户态程序的时候在bpf虚拟机会发生什么呢?我理解应该会结束已经加载的bpf指令,清理map之类的资源等等,具体会有哪些,这些操作是如何在我们程序中自动插入和实现,请老师指点下。
写点啥呢想请教下老师关于bpf内核态程序的成名周期,比如前几节课的例子,如果我通过ctrl-c终端用户态程序的时候在bpf虚拟机会发生什么呢?我理解应该会结束已经加载的bpf指令,清理map之类的资源等等,具体会有哪些,这些操作是如何在我们程序中自动插入和实现,请老师指点下。作者回复: 非常好的问题。ctrl-c其实终止的是用户空间的程序,终止后所有的文件描述符都会释放掉,对应的map和ebpf程序引用都会减到0,进而它们也就被自动回收了。这些都是自动的,不需要在程序里面增加额外的处理逻辑。 当然,在需要长久保持eBPF程序的情境中(比如XDP和TC程序),eBPF程序和map的生命周期是可以在程序内控制的,比如通过 tc、ip 以及 bpftool 等工具(当然它们也都有相应的系统调用)。我们课程后面还会讲到相关的案例。
2022-01-294 不了峰BPF 系统调用 --> 发生在 用户态 BPF 辅助函数 --> 内核态 --- root@ubuntu-impish:/proc# bpftool perf pid 38110 fd 6: prog_id 572 kprobe func do_sys_openat2 offset 0 root@ubuntu-impish:/proc# ps -ef|grep 38110 root 38110 38109 0 03:41 pts/2 00:00:02 python3 ./trace_open.py
不了峰BPF 系统调用 --> 发生在 用户态 BPF 辅助函数 --> 内核态 --- root@ubuntu-impish:/proc# bpftool perf pid 38110 fd 6: prog_id 572 kprobe func do_sys_openat2 offset 0 root@ubuntu-impish:/proc# ps -ef|grep 38110 root 38110 38109 0 03:41 pts/2 00:00:02 python3 ./trace_open.py作者回复: 不错的总结👍
2022-01-282
 piboye老师, bpf 的 map 怎么移除啊? 没看到 bpftools 的命令
piboye老师, bpf 的 map 怎么移除啊? 没看到 bpftools 的命令作者回复: map是自动删除的,跟它关联的文件描述符关闭后就会删除
2022-03-1531- Geek_59a6f9在高版本内核编译运行的ebpf程序,移植到低版本也能直接运行吗?低版本的libbpf 如何感知到高版本内核的修改,从而预定义不同内核版本的数据结构吗?
作者回复: 从低版本到高版本的兼容性可以用CO-RE解决(CO-RE只在新版本内核才支持),而反过来就需要在eBPF内部加上额外的代码来处理了。比如根据内核版本作条件编译,低版本内核执行不同的逻辑。
2022-02-041  │.Sk倪老师好, 想请教一下,在支持 BTF 的内核中,利用 CO-RE 编译出的 ebpf 程序可执行文件,直接 copy 到低版本不支持 BTF 的内核版本的系统上能正常运行吗? 谢谢!
│.Sk倪老师好, 想请教一下,在支持 BTF 的内核中,利用 CO-RE 编译出的 ebpf 程序可执行文件,直接 copy 到低版本不支持 BTF 的内核版本的系统上能正常运行吗? 谢谢!作者回复: 不行的,它需要运行的内核也支持BTF。 不过现在最新的bpftool已经支持导出BTF,跟eBPF程序一通分发后也可以执行了。具体可以参考这个博客 https://www.inspektor-gadget.io//blog/2022/03/btfgen-one-step-closer-to-truly-portable-ebpf-programs/
2022-12-31归属地:上海 MoGeJiEr🐔BTF那块是不是没说完阿?不是只介绍了可以使用bpftool生成vmlinux.h头文件嘛? 怎么后面CO-RE就可以借助BTF的调试信息?这个调试信息哪里来?一头雾水。2022-08-15归属地:江苏1
MoGeJiEr🐔BTF那块是不是没说完阿?不是只介绍了可以使用bpftool生成vmlinux.h头文件嘛? 怎么后面CO-RE就可以借助BTF的调试信息?这个调试信息哪里来?一头雾水。2022-08-15归属地:江苏1- woJA1wCgAAbjKldokPvO1h9ZEJTUP8...老师,结构化的数据需要怎么看,bpftool map dump id mapid和bpftool map dump name mapname结果都是一样的16进制数2022-04-211
- Geek_94444c"eBPF 程序最多可以访问 64 个不同的 BPF 映射" 1. 这句话的意思是单个用户态的ebpf程序能创建64个map,还是主机上所有ebpf程序加起来可以创建64个内核态的ebpf程序? 2. 用户态的ebpf程序怎么绑定这些map的,有实例吗?2023-12-12归属地:四川

