

03 | 初窥门径:开发并运行你的第一个eBPF程序

如何选择 eBPF 开发环境?
如何搭建 eBPF 开发环境?
如何开发第一个 eBPF 程序?
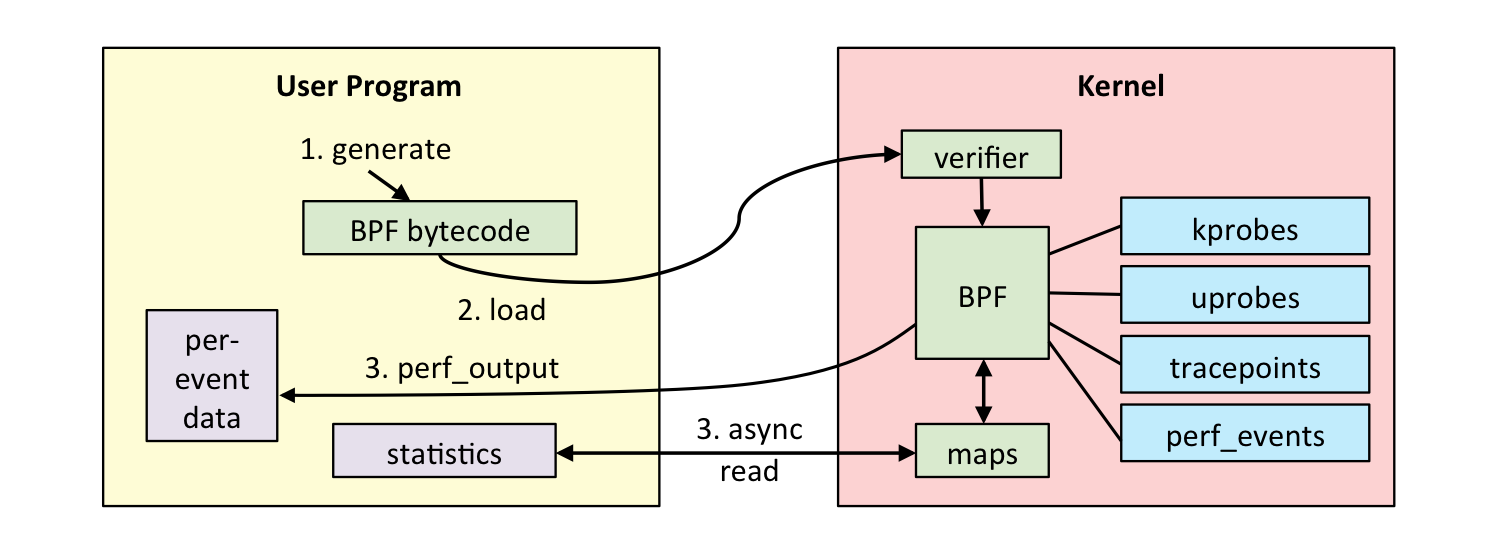
第一步:使用 C 开发一个 eBPF 程序
第二步:使用 Python 和 BCC 库开发一个用户态程序
第三步:执行 eBPF 程序
如何改进第一个 eBPF 程序?
小结
思考题
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

本文介绍了如何开发并运行第一个eBPF程序。作者建议使用更新的5.x内核来稳定运行eBPF程序,并推荐了几个发行版作为开发环境。文章详细介绍了搭建eBPF开发环境所需的开发工具,并提供了针对不同发行版的安装命令。接着,作者解释了eBPF程序的开发和执行过程,包括使用C语言开发eBPF程序、使用Python和BCC库开发用户态程序以及执行eBPF程序的步骤。最后,作者提出了对第一个eBPF程序的改进方向,以解决当前程序存在的一些缺点。文章内容详实,适合初学者快速了解eBPF程序的开发和运行流程。文章还介绍了如何利用BPF映射进行数据存储,以及如何从用户态读取BPF映射内容并输出到标准输出。通过实例演示,读者可以了解如何开发完整的eBPF程序,并在日常工作中应用这些技术。
2022-01-2139人觉得很赞给文章提建议
《eBPF 核心技术与实战》,新⼈⾸单¥59

全部留言(64)
- 最新
- 精选
 莫名置顶给倪老师的 Github 仓库里面的这个小程序挑个🐛: 1、b = BPF(src_file="trace-open.c"),trace-open.c -> trace_open.c 2、依赖了 openat2.h 头文件,openat2 系统调用自 5.6 版本才出现,低于这个版本无法运行 trace_open.py,建议用 openat 系统调用,有比较好的版本兼容性。
莫名置顶给倪老师的 Github 仓库里面的这个小程序挑个🐛: 1、b = BPF(src_file="trace-open.c"),trace-open.c -> trace_open.c 2、依赖了 openat2.h 头文件,openat2 系统调用自 5.6 版本才出现,低于这个版本无法运行 trace_open.py,建议用 openat 系统调用,有比较好的版本兼容性。作者回复: 1. 谢谢指出,已经修复了。 2. 是的,但我们专栏还是希望使用新版本的内核来学习,这样一方面能体验最新的特性,另一方面不需要等后面需要用到新特性的时候再重新配置开发环境。
2022-01-2138- 莫名置顶追踪文件打开事件,采用场景大致有: 1、查看某个程序启动时加载了哪些配置文件,便于确认是否加载了正确的配置文件。对于允许自定义配置文件路径的程序尤其有用,例如 MySQL、PostgreSQL。 2、查看是否存在频繁或周期性打开某些文件的情况,考虑是否存在优化可能。比如周期性打开某个极少变化的文件,可以一次性读取,且监听文件变动事件,避免多次打开读取。 3、分析依赖 /proc、/sys 等虚拟文件系统的 Linux 工具大致工作原理。比如执行 vmstat,,可以通过追踪文件打开事件看到至少打开了 /proc/meminfo、/proc/stat、/proc/vmstat 这几个文件,帮助你更好的理解工具的数据源与实现原理。 4、分析 K8s、Docker 等 cgroup 相关操作。比如 docker run xxx 时,可以看到 /sys/fs/cgroup/cpuset/docker/xxx/cpuset.cpus、/sys/fs/cgroup/cpuset/docker/xxx/cpuset.mems 等 cgroup 文件被打开,也可以查看 kube-proxy 在周期性刷新 cgroup 相关文件。 5、....
作者回复: 太赞了👍 感谢分享追踪文件打开的这些应用场景
2022-01-21364  JUNLONG习惯用docker的同学可以试下 这个镜像,github地址:github.com/Jun10ng/ebpf-for-desktop 用docker可以用vscode编辑会高效点。如果喜欢的话就来个start吧 谢谢
JUNLONG习惯用docker的同学可以试下 这个镜像,github地址:github.com/Jun10ng/ebpf-for-desktop 用docker可以用vscode编辑会高效点。如果喜欢的话就来个start吧 谢谢作者回复: 👍谢谢分享!我通常还是使用虚拟机作为开发环境,只在部署的时候才用容器。
2022-01-2329 jssfy请问这种对open系统调用的截获会影响用户文件打开的性能不? 影响到什么程度呢?
jssfy请问这种对open系统调用的截获会影响用户文件打开的性能不? 影响到什么程度呢?作者回复: 对大部分应用来说,性能损失基本可以忽略。但如果应用对性能有比较极致的敏感,比如到了纳秒或者指令集,那就需要考虑eBPF的性能损耗了。 给你分享一个eBPF性能评估的演讲,希望有所帮助:https://ebpf.io/summit-2020-slides/eBPF_Summit_2020-Lightning-Bryce_Kahle-How_and_When_You_Should_Measure_CPU_Overhead_of_eBPF_Programs.pdf。
2022-02-086- ThinkerWalker有个Python语法的疑问:trace_open.py中,print_event被调用的时候【28行,b["events"].open_perf_buffer(print_event)】是如何传入三个参数(cpu, data, size)呢?
作者回复: 这些参数都是由BCC框架默认提供的,不需要使用的时候再额外传入。
2022-01-2136  不了峰原来这个 trace_open.py 就是一个「简化」版的 opensnoop-bpfcc 工具呀。 我为了更清晰更简单的打印出 trace_open.py 的输出把一些服务都关了 :) systemctl stop multipathd systemctl stop snapd systemctl stop irqbalance
不了峰原来这个 trace_open.py 就是一个「简化」版的 opensnoop-bpfcc 工具呀。 我为了更清晰更简单的打印出 trace_open.py 的输出把一些服务都关了 :) systemctl stop multipathd systemctl stop snapd systemctl stop irqbalance作者回复: 看来你已经对BCC比较熟悉了😊
2022-01-255- Geek_5aa343老师,您好,有几个问题请教下: 1. "do_sys_openat2() 是系统调用 openat() 在内核中的实现" 怎么去找到一个系统调用在内核中的实现呢? 2. 使用BPF map获取openat的打开文件名这里,// 定义数据结构struct data_t { u32 pid; u64 ts; char comm[TASK_COMM_LEN]; char fname[NAME_MAX];}; 这个的格式为啥是这样呢,就是有具体每个探针的map说明文档嘛 多谢老师
作者回复: 1. 每个系统调用在内核中都有类似 sys_xxx 的实现函数,我们后面课程会讲到怎么查询内核中的跟踪点,根据名字去过滤就可以找到实现函数的名字。当然,如果你要看具体的实现步骤,就得需要去看看内核的源码了。 2. 没有固定的格式,这个数据结构其实就是你想在用户态中获取的数据,不同的程序需要的数据是不同的。
2022-01-2135 - Geek_b85295老师,我的环境是ubuntu20.04,内核5.4.0-92-generic,把环境依赖都正常安装好后,执行python3 hello.py 出现错误 Failed to attach BPF program b'hello_world' to kprobe b'do_sys_openat2',网上没找到解决方法,可以帮忙看看嘛
作者回复: 嗯,碰到这种问题最好的方法是去查man手册。比如,你可以在 https://man7.org/linux/man-pages/man2/openat2.2.html#VERSIONS 看到,openat2 是 5.6 内核才支持的。所以,对旧的内核来说,就需要替换成 openat 系统调用。
2022-02-0853  写点啥呢有几个问题想请教老师: 1. perf_buffer_poll方法是非阻塞的么 2. bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename); 这里filename指针的内存大小是否也是NAME_MAX,不然读取应该会导致非法访问 3. hello_world方法的几个形参是什么含义,感觉ctx是bpf固定的,后面dfd, filename和open_how是openat2的参数,请问是否编写bpf函数都是可以在ctx后面加入对应系统调用接口的入参,然后bpf会在执行时候自动进行参数绑定? 4. perf_submit函数传入的c struct在bcc脚本中看上去可以通过event方法自动转化为python对象? 谢谢老师
写点啥呢有几个问题想请教老师: 1. perf_buffer_poll方法是非阻塞的么 2. bpf_probe_read(&data.fname, sizeof(data.fname), (void *)filename); 这里filename指针的内存大小是否也是NAME_MAX,不然读取应该会导致非法访问 3. hello_world方法的几个形参是什么含义,感觉ctx是bpf固定的,后面dfd, filename和open_how是openat2的参数,请问是否编写bpf函数都是可以在ctx后面加入对应系统调用接口的入参,然后bpf会在执行时候自动进行参数绑定? 4. perf_submit函数传入的c struct在bcc脚本中看上去可以通过event方法自动转化为python对象? 谢谢老师作者回复: 不错的问题,看来是深入学习了,赞一个👍 1. 这个函数实际上对所有的perf缓冲区调用它们的回调函数,然后就结束了(所以外层还有一个while循环)。 2. 不是的,过长的filename会截断。 3和4的理解都是对的。
2022-01-2823 waterjiao还有几个问题咨询下老师 1. perf缓存区大小如何查看 2.如果缓存区满了,后续数据会覆盖之前的数据吗?open_perf_buffer是阻塞的么 3. libbpf是怎么做到co-re的
waterjiao还有几个问题咨询下老师 1. perf缓存区大小如何查看 2.如果缓存区满了,后续数据会覆盖之前的数据吗?open_perf_buffer是阻塞的么 3. libbpf是怎么做到co-re的作者回复: 这个时候就需要去看文档了。比如前两个问题的答案都在 https://github.com/iovisor/bcc/blob/23a21423a31719bd79e9e975b8f6dca8f7a331e5/docs/reference_guide.md#2-open_perf_buffer: https://github.com/iovisor/bcc/blob/23a21423a31719bd79e9e975b8f6dca8f7a331e5/docs/reference_guide.md#2-open_perf_buffer 对于CO-RE的原理,可以看一下 https://nakryiko.com/posts/bpf-core-reference-guide/
2022-02-172

