

16 | 内存模型:有了MESI为什么还需要内存屏障?

严守 MESI 协议的 CPU 会有啥问题?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

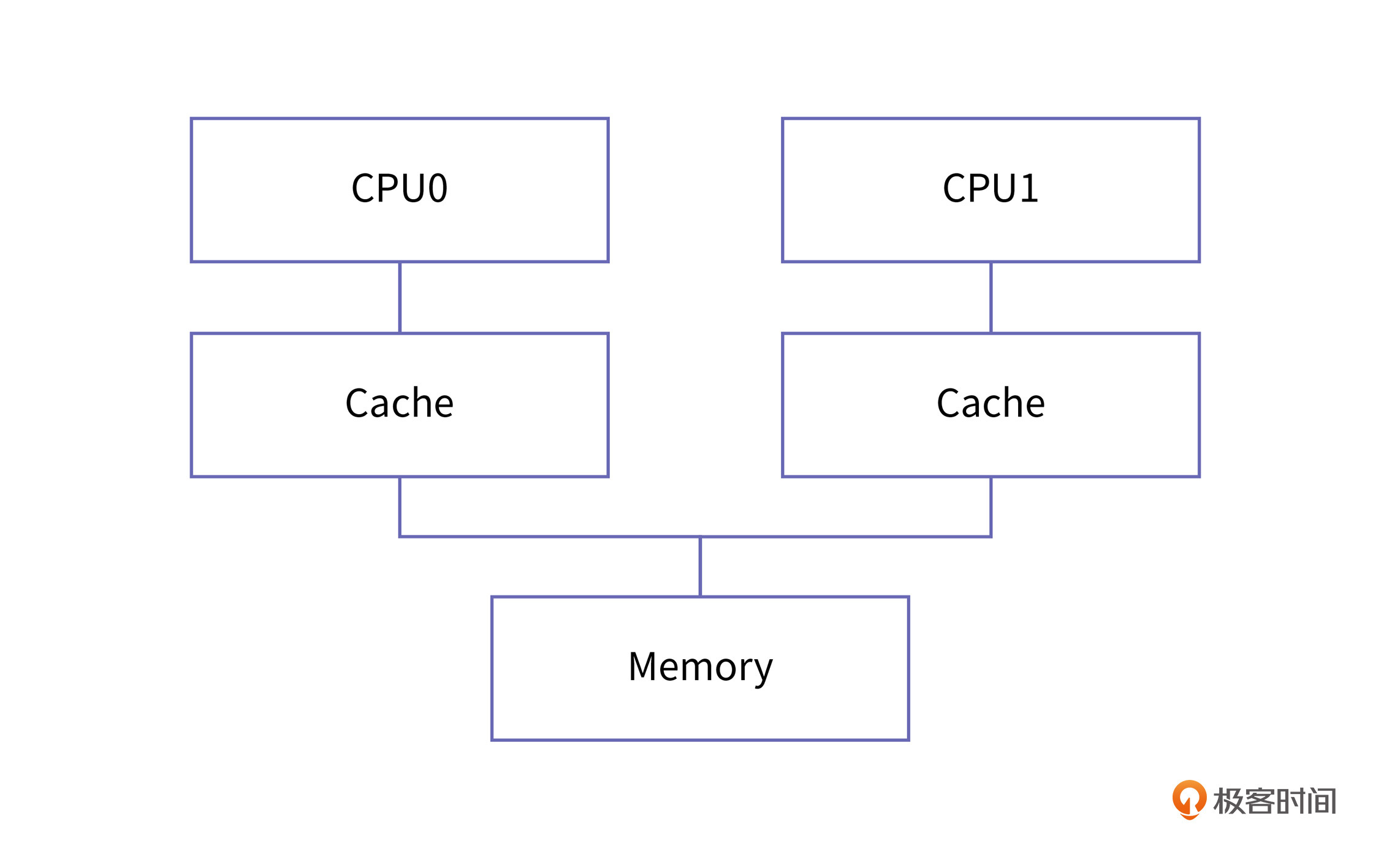
多核CPU之间的缓存一致性问题一直是一个重要挑战,而MESI协议和store buffer结构在解决这一问题中发挥了关键作用。然而,严格遵守MESI协议可能会影响CPU性能,因此引入了弱缓存一致性和内存屏障来解决缓存顺序一致性的问题。此外,失效队列和读写屏障的引入进一步提升了CPU的响应速度和缓存顺序一致性。文章还介绍了单向屏障的概念,以及在不同体系结构下的应用。这些技术特点对于理解并发问题和内存模型具有重要意义。 在CPU的具体实现中,通过放宽MESI协议的限制来获得性能提升。具体来说,引入了store buffer和invalid queue,它们采用放宽MESI协议要求的办法,提升了写缓存核间同步的速度,从而提升了程序整体的运行速度。然而,放宽协议也带来了新的问题,即一个CPU的读写操作在其他CPU看来出现了乱序,需要加入内存屏障来解决这个问题。最后,学习了读写屏障分离和单向屏障,以及如何正确地使用内存屏障。 文章还提出了一个思考题,讨论了在Java代码中使用fullFence是否合理,以及可能的替代方案。除此之外,还提示了使用volatile关键字的改法,并鼓励读者在留言区分享想法。 总的来说,本文深入探讨了多核CPU之间的缓存一致性问题以及相关解决方案,对于对MESI协议和内存屏障感兴趣的读者具有很高的参考价值。
《编程高手必学的内存知识》,新⼈⾸单¥59

全部留言(24)
- 最新
- 精选
 sc
sc CPU 从单核发展为多核,增加缓存,导致出现了多个核间的缓存一致性问题 --> 为了解决缓存一致性问题,提出了 MESI 协议 --> 完全遵守 MESI 又会给 CPU 带来性能问题 --> CPU 设计者又增加 store buffer 和 invalid queue --> 又导致了缓存的顺序一致性变为了弱缓存一致性 --> 需要缓存的顺序一致性的,就需要软件工程师自己在合适的地方添加内存屏障
CPU 从单核发展为多核,增加缓存,导致出现了多个核间的缓存一致性问题 --> 为了解决缓存一致性问题,提出了 MESI 协议 --> 完全遵守 MESI 又会给 CPU 带来性能问题 --> CPU 设计者又增加 store buffer 和 invalid queue --> 又导致了缓存的顺序一致性变为了弱缓存一致性 --> 需要缓存的顺序一致性的,就需要软件工程师自己在合适的地方添加内存屏障作者回复: 总结得很好呀。这就是整个硬件篇的内在逻辑。感动~
2021-12-10223 .我看了一些文献关于X86(total store ordering )加上自己的理解: 1)由于不存在invalidate queue且读和读之间不会重排序切读线程会先读取store buffer,因此LoadLoad屏障在x86是无用的 2)由于store buffers是采用队列且不同地址的写是不会重排序因此StoreStore 可不存在 3)读可以与之前同位置排序,但不能与非同位置重排序(我在wiki搜不到这个屏障多线程问题,关于这个多线程实际应用场景不明确) LoadStore也没有了意义 4)但是写可能与之前的读重排序因此需要特别考虑这种重排序,StoreLoad存在意义 且存在可行性问题(但是老师说TSO不存在缓存一致性我不大理解这个在StoreLoad是否也是成立)
.我看了一些文献关于X86(total store ordering )加上自己的理解: 1)由于不存在invalidate queue且读和读之间不会重排序切读线程会先读取store buffer,因此LoadLoad屏障在x86是无用的 2)由于store buffers是采用队列且不同地址的写是不会重排序因此StoreStore 可不存在 3)读可以与之前同位置排序,但不能与非同位置重排序(我在wiki搜不到这个屏障多线程问题,关于这个多线程实际应用场景不明确) LoadStore也没有了意义 4)但是写可能与之前的读重排序因此需要特别考虑这种重排序,StoreLoad存在意义 且存在可行性问题(但是老师说TSO不存在缓存一致性我不大理解这个在StoreLoad是否也是成立)作者回复: 赞!这就学得很深入了。我这里简化了描述,TSO模型唯一需要的是StoreLoad barrier,但它产生的原因不是缓存一致性。 所以x86上遇到需要StoreLoad barrier的地方,还要是正确添加才可以。
2021-12-0658 一塌糊涂必须赞,看过很多资料,唯一能讲明白的!大神推荐点资料吧。
一塌糊涂必须赞,看过很多资料,唯一能讲明白的!大神推荐点资料吧。作者回复: 多谢。这些内容是从很多文章里以及CPU源文件,还有向CPU设计者请教得到的心得。所以,我一下子也很难说得上来有什么资料。我觉得这个专栏本身可能就是目前的中文互联网上的一个比较好的资料吧。至于说这一节课的内容,核心思想是来自这篇文章:《Memory Barriers: a Hardware View for Software Hackers》,但我并不建议你去看这篇文章,因为这篇文章里在讲到MESI状态变化的时候过于复杂了。
2021-12-035- shenglin思考题实例代码使用fullFence()正确性是可以保证的,只是性能下降? // CPU0 void foo() { a = 1; unsafe.storeFence(); b = 1; } // CPU1 void bar() { while (b == 0) continue; unsafe.loadFence(); assert(a == 1); } 可以改成这样?因为由于store buffer的存在,foo()函数要a的新值写入缓存之后,b的新值才能写入,所以要使用storeFence屏障; bar()函数要读取b和a的新值,且由于invalid_queue的存在,要加入loadFence保证读取到a的新值前invalid_queue的消息已经被处理完成,即将CPU1的缓存中的a值更新。这样即保证了正确性,又兼顾了性能,不知道这样理解对不对?
作者回复: 完全正确!非常好,说明你真的掌握了!
2021-12-033  一个工匠在正常的程序中,多个 CPU 一起操作同一个变量的情况是比较少的,所以 store buffer 可以大大提升程序的运行性能。 这一块不是很理解,单个cpu操作同一个变量不就不需要mesi了么?所以mesi就是处理多核数据读写不一致问题而存在的,并且可以解决。但是优化之后,又不可以解决了,并且要让开发人员添加屏障进一步解决。那是不是可以理解mesi最后还是没完成“多核缓存一致性”工作?
一个工匠在正常的程序中,多个 CPU 一起操作同一个变量的情况是比较少的,所以 store buffer 可以大大提升程序的运行性能。 这一块不是很理解,单个cpu操作同一个变量不就不需要mesi了么?所以mesi就是处理多核数据读写不一致问题而存在的,并且可以解决。但是优化之后,又不可以解决了,并且要让开发人员添加屏障进一步解决。那是不是可以理解mesi最后还是没完成“多核缓存一致性”工作?作者回复: mesi是一个协议。cpu的设计者完全遵守协议就一定能保证数据一致性。但是完全遵守协议性能低,这时候就有人想,我放松一点要求,性能就可以得到很大的提升,但需要软件工程师帮忙。总的看来这种放松是有利的。
2022-02-1421 陈狄请问老师,「内存屏障的作用是屏障前面的读写未完成,不会进行屏障后面的读写」,怎么判断store buffer,尤其是invalid queue里的数据是屏障前面未完成的读写?
陈狄请问老师,「内存屏障的作用是屏障前面的读写未完成,不会进行屏障后面的读写」,怎么判断store buffer,尤其是invalid queue里的数据是屏障前面未完成的读写?作者回复: cpu会保证的,当遇到dmb指令的时候,cpu会停下来,直到条件满足了才会继续执行。
2022-01-091- Vvin你好!请问:如果在有store buffer的情况!cup0 and cpu1都写同一个状态为shared的a变量,怎么处理?
作者回复: 总线会做裁决。总线最后看到的是谁就用谁的值。所以会有一定的随机性。
2021-12-121  BlockQuant“CPU0 在得到这个确认消息以后,就可以独占该缓存了,直接将这块缓存变为 Modified 状态,然后把 a 写入。在 a 写入以后,foo 函数中的内存屏障就可以顺利通过了,接下来就可以写入变量 b 的新值。由于 b 是 Exclusive 的” 这个 b 为啥是 E 状态,CPU1也在用,不应该是 S 吗?
BlockQuant“CPU0 在得到这个确认消息以后,就可以独占该缓存了,直接将这块缓存变为 Modified 状态,然后把 a 写入。在 a 写入以后,foo 函数中的内存屏障就可以顺利通过了,接下来就可以写入变量 b 的新值。由于 b 是 Exclusive 的” 这个 b 为啥是 E 状态,CPU1也在用,不应该是 S 吗?作者回复: 哦。这是我们假设的一种状态,比如线程1所在的CPU里早就有了b的缓存,而线程2还没得到调度,它的CPU里没有b的缓存。这几种假设状态都是有可能的。所以我们写的代码并不是一定出问题,而是有概率出问题。
2021-12-07 那时刻请问老师,内存屏障对于其它语言,比如go,是否是一致的呢? 对于其它语言,读写屏障可以保证代码的执行顺序是一致的
那时刻请问老师,内存屏障对于其它语言,比如go,是否是一致的呢? 对于其它语言,读写屏障可以保证代码的执行顺序是一致的作者回复: 这节课的内容其实和语言无关。内存屏障都是需要的,只是看这门语言是以什么样的api暴露给用户。
2021-12-07- dog_brother老师,这里说的内存屏障跟c++11的memory order是一回事么?
作者回复: acquire/release是一样的。
2021-12-06

