

32 | 数据处理:如何高效处理应用程序产生的数据?
孔令飞

该思维导图由 AI 生成,仅供参考
你好,我是孔令飞。今天我们来聊聊,如何更好地进行异步数据处理。
一个大型应用为了后期的排障、运营等,会将一些请求数据保存在存储系统中,供日后使用。例如:应用将请求日志保存到 Elasticsearch 中,方便排障;网关将 API 请求次数、请求消息体等数据保存在数据库中,供控制台查询展示。
为了满足这些需求,我们需要进行数据采集,数据采集在大型应用中很常见,但我发现不少开发者设计的数据采集服务,通常会存在下面这些问题:
采集服务只针对某个采集需求开发,如果采集需求有变,需要修改主代码逻辑,代码改动势必会带来潜在的 Bug,增加开发测试工作量。
数据采集服务会导致已有的服务请求延时变高。
采集数据性能差,需要较长时间才能采集完一批数据。
启停服务时,会导致采集的数据丢失。
这一讲,我就来详细教你如何设计和落地一个数据采集服务,解决上面这些问题。
数据采集方式的分类
首先,你需要知道当前数据采集有哪些方式,以便更好地理解异步数据处理方案。
目前,数据采集主要有两种方式,分别是同步采集和异步采集。二者的概念和优缺点如下表所示:
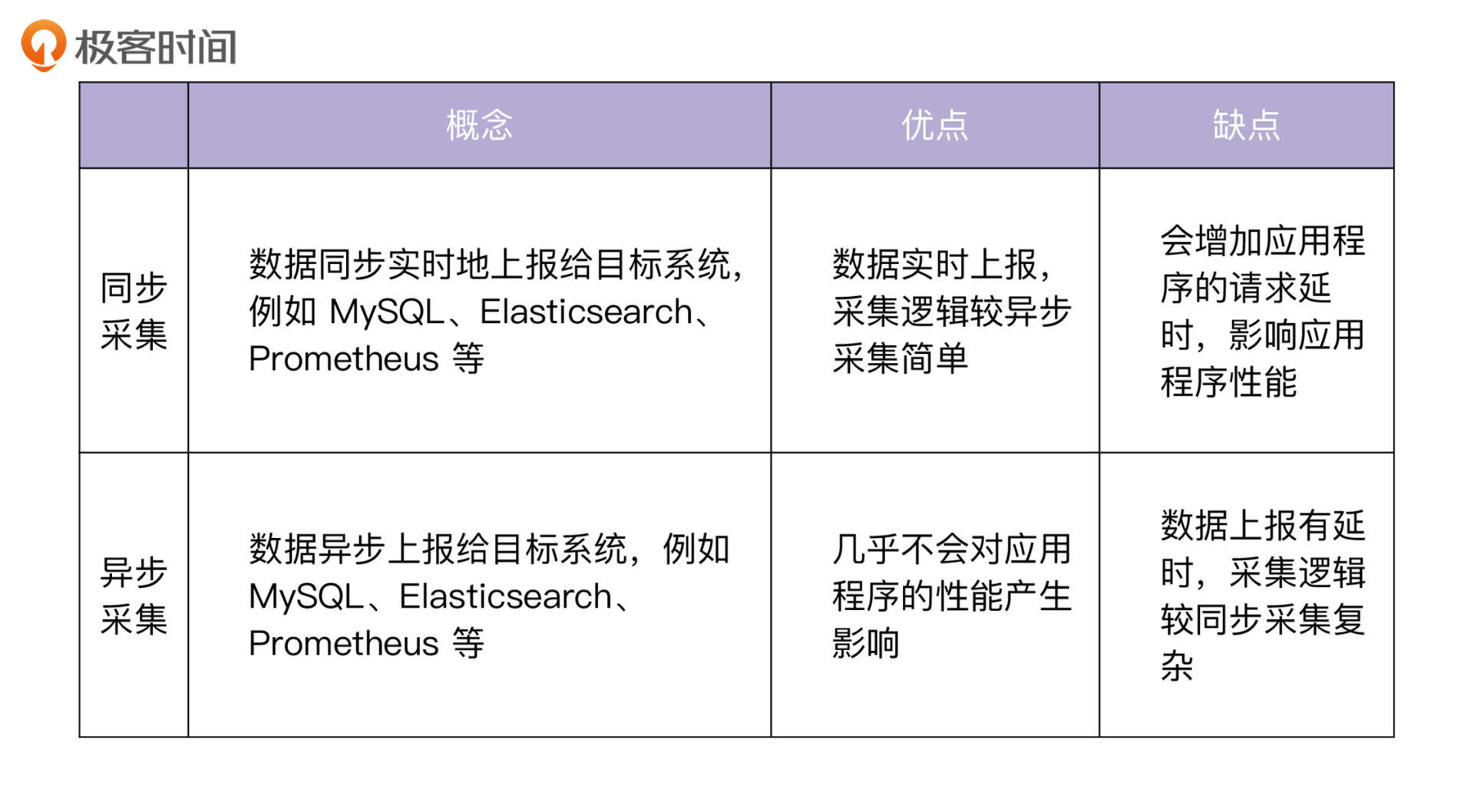
现代应用对性能的要求越来越高,而异步采集对应用程序的性能影响更小,因此异步采集更受开发者欢迎,得到了大规模的应用。接下来,我要介绍的 IAM Pump Server 服务,采用的就是异步采集的方式。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入探讨了设计和落地高效数据采集服务的关键要点。强调了异步采集在现代应用中的重要性,并详细介绍了数据采集系统的设计要点和应用模型的绘制。通过模型化设计和插件化架构,解决了数据采集中的性能、数据堆积和多样化需求等问题。文章突出了异步数据处理的重要性,以及如何通过模型化设计和插件化架构来解决数据采集中的性能、数据堆积和多样化需求等问题。读者可以从中学习到如何设计和实现一个高效的数据采集系统,为应用程序产生的数据提供更好的处理方式。文章还介绍了iam-pump组件的设计要点和核心代码,以及如何实现数据采集插件定义、初始化和健康检查等功能。最后,作者建议将一些功能抽象成通用模型,并为该模型实现基本框架,然后将需要定制化的部分插件化,以设计出一个高扩展的服务,满足现在和未来的需求。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《Go 语言项目开发实战》,新⼈⾸单¥68
《Go 语言项目开发实战》,新⼈⾸单¥68
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(9)
- 最新
- 精选
 Sch0ng数据采集服务分数据上报和数据采集,先做拆分再有针对性达成目标性能。 把功能抽象成模型,再把实现封装成独立的模块,应用依赖模型的接口,不依赖具体的实现。
Sch0ng数据采集服务分数据上报和数据采集,先做拆分再有针对性达成目标性能。 把功能抽象成模型,再把实现封装成独立的模块,应用依赖模型的接口,不依赖具体的实现。作者回复: 到位!
2021-08-1625 Vackinepump如果中途退出了,会记录已经消费的位置么?
Vackinepump如果中途退出了,会记录已经消费的位置么?作者回复: 这里暂时不支持。 老哥,可以尝试将redis切换成kafka,kafka可以记录消费位置
2021-08-0725 静心这个插件化的pump模型抽象的真好,感觉这个pump项目完全可以用到生产了。
静心这个插件化的pump模型抽象的真好,感觉这个pump项目完全可以用到生产了。作者回复: 这个模型就是源自亿级QPS的生产项目,完全可以用到生产环境中。
2021-10-292 左耳朵东func (r *Analytics) Start() { analytics = r r.store.Connect() // start worker pool atomic.SwapUint32(&r.shouldStop, 0) for i := 0; i < r.poolSize; i++ { r.poolWg.Add(1) go r.recordWorker() } // stop analytics workers go r.Stop() } 倒数第二行代码 go r.Stop(),这里把 recordsChan 马上又关闭了?那后面还怎么给这个 channel 发消息?
左耳朵东func (r *Analytics) Start() { analytics = r r.store.Connect() // start worker pool atomic.SwapUint32(&r.shouldStop, 0) for i := 0; i < r.poolSize; i++ { r.poolWg.Add(1) go r.recordWorker() } // stop analytics workers go r.Stop() } 倒数第二行代码 go r.Stop(),这里把 recordsChan 马上又关闭了?那后面还怎么给这个 channel 发消息?作者回复: 这里是个bug哈,master分支有纠正过来,这里我让编辑改下
2022-03-141- Geek_63505f老师这句话是什么意思 viper.SetEnvKeyReplacer(strings.NewReplacer(".", "_", "-", "_")) strings.NewReplacer里面不应该是("-","_")这样吗?前面那两个字符多出来是干嘛用的?
作者回复: 将 . 也转换为_
2022-01-2221  Ethan Liu应用产生的数据放到日志中,再由数据上报服务读取至bufferd channel吗? 同步上报方式指的是rpc吗?
Ethan Liu应用产生的数据放到日志中,再由数据上报服务读取至bufferd channel吗? 同步上报方式指的是rpc吗?作者回复: 同步上报指的是:调用上报接口,并阻塞直到上报接口返回。
2021-09-091 来咯ensureConnection redis 重新连接 失败 应该需要sleep吧 不然日志写爆 CPU 也占满了
来咯ensureConnection redis 重新连接 失败 应该需要sleep吧 不然日志写爆 CPU 也占满了作者回复: 没问题的
2022-05-27归属地:广东 yandongxiao总结: 数据采集服务常见问题:不够通用化;采集服务延迟高、性能差、启停服务时会有数据丢失。 数据采集服务一般需要完成:数据上报 和 数据处理。它们一般不是同一个进程内。 数据上报:对数据压缩、支持批量上报、超时上报、优雅关停(停止接收新请求,完成服务中的请求) 数据处理:数据处理完毕后,还需要进行上报。将上报的模块做成插件化,非常重要。2021-12-041
yandongxiao总结: 数据采集服务常见问题:不够通用化;采集服务延迟高、性能差、启停服务时会有数据丢失。 数据采集服务一般需要完成:数据上报 和 数据处理。它们一般不是同一个进程内。 数据上报:对数据压缩、支持批量上报、超时上报、优雅关停(停止接收新请求,完成服务中的请求) 数据处理:数据处理完毕后,还需要进行上报。将上报的模块做成插件化,非常重要。2021-12-041 伪装成学霸的学渣我想问一下这种大文件处理方式,文中处理方式是直接把大文件上传请求数据保存在redis么? 还有既然在上报后pump做了过滤处理,是否考虑在网关上报前做过滤处理? "我之前开发过公有云的网关服务,网关服务需要把网关的请求数据转存到 MongoDB 中。我们的网关服务曾经遇到一个比较大的坑:有些用户会通过网关上传非常大的文件(百 M 级别),这些数据转存到 MongoDB 中,快速消耗了 MongoDB 的存储空间(500G 存储空间)。为了避免这个问题,在转存数据时,需要过滤掉一些比较详细的数据,所以 iam-pump 添加了 SetOmitDetailedRecording 来过滤掉详细的数据"2023-11-14归属地:芬兰
伪装成学霸的学渣我想问一下这种大文件处理方式,文中处理方式是直接把大文件上传请求数据保存在redis么? 还有既然在上报后pump做了过滤处理,是否考虑在网关上报前做过滤处理? "我之前开发过公有云的网关服务,网关服务需要把网关的请求数据转存到 MongoDB 中。我们的网关服务曾经遇到一个比较大的坑:有些用户会通过网关上传非常大的文件(百 M 级别),这些数据转存到 MongoDB 中,快速消耗了 MongoDB 的存储空间(500G 存储空间)。为了避免这个问题,在转存数据时,需要过滤掉一些比较详细的数据,所以 iam-pump 添加了 SetOmitDetailedRecording 来过滤掉详细的数据"2023-11-14归属地:芬兰
收起评论

