

07 | 工具进化:如何实现一个分布式压测平台

 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

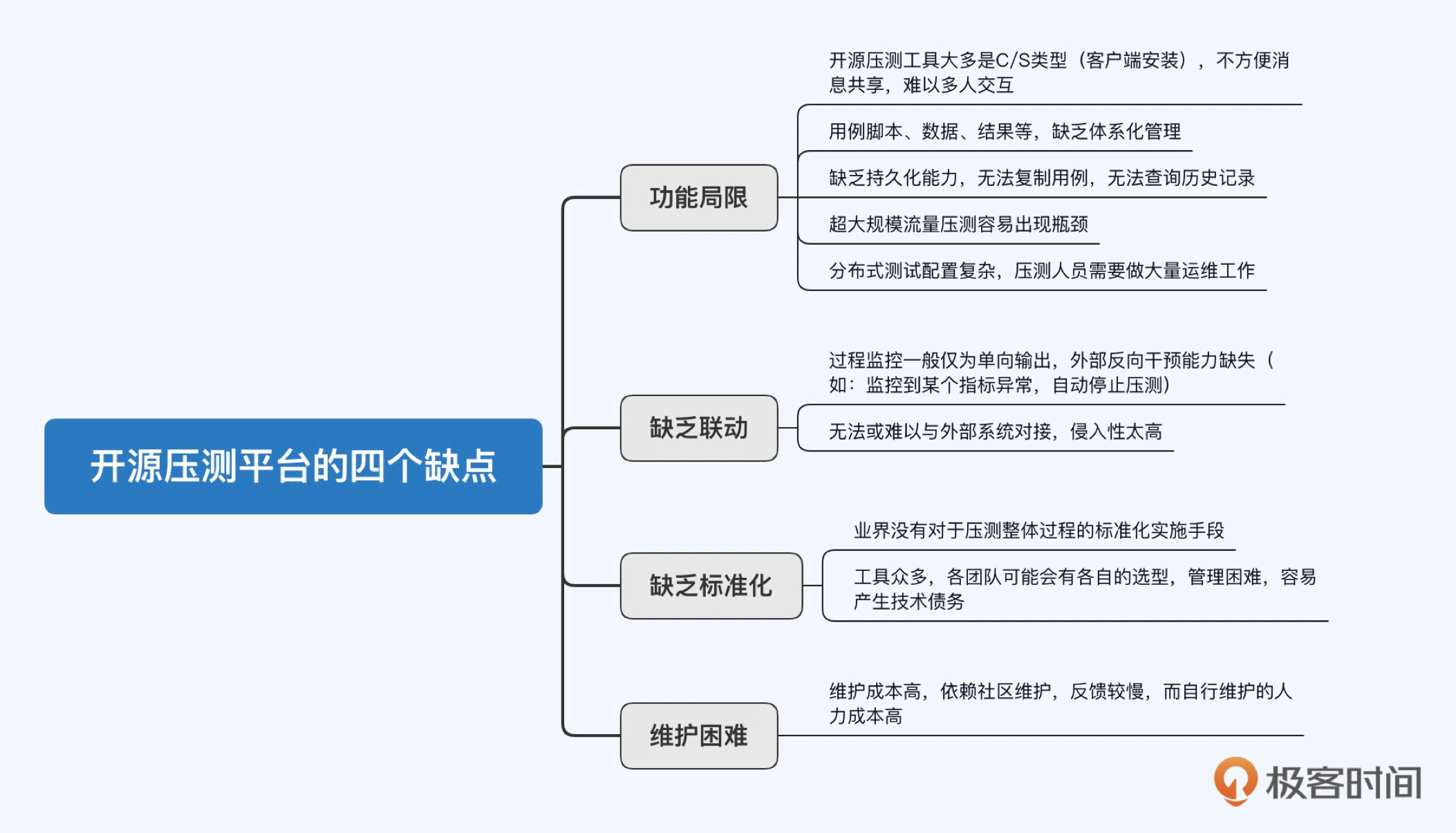
本文介绍了作者分享的如何自己实现一个分布式压测平台的经验。作者指出了市面上开源压测工具的一些缺点,并提出了企业自研压测平台需要满足的三点需求:平台化、标准化和控制成本。文章详细介绍了基于JMeter的分布式压测平台实现方案,包括架构设计思路和主要功能实现方案和原理。重点讲解了测试状态流转和如何获取和展示实时数据两个方面。此外,还介绍了结果数据的存储方式和如何进行吞吐量限制与动态调节,以及实现配置集功能。最后,文章还提到了监控模块的重要性,包括内部监控模块和外部监控模块的功能和实现方式。整体而言,本文对于想要了解如何实现分布式压测平台的读者具有一定的参考价值。
《容量保障核心技术与实战》,新⼈⾸单¥29

全部留言(9)
- 最新
- 精选
 Hale老师好,请问,使用agent是怎么判断jemter压测结束各个状态的?这块不理解
Hale老师好,请问,使用agent是怎么判断jemter压测结束各个状态的?这块不理解作者回复: 你好,我们可以回顾一下文中的状态变换表格和状态机,其中每个状态都有成功的条件和失败的条件,具体状态是保存在数据库中的,我们可以通过轮询这一状态,根据结果决定是否执行后续步骤。整个逻辑都是状态机管理的,Agent只负责执行指令。 举个例子,当用户触发一次压测,系统会同时建立三个任务:配置、执行和运行。配置任务在成功完成后会将状态置为BOOTED,失败则置为BOOTERROR。与此同时,执行任务在不断轮询状态,一旦轮询到状态为BOOTED,立刻执行触发逻辑,如果轮询到状态为BOOTERROR,则终止,并取消后续运行任务。运行任务的原理也是一样的。最后,有一个收集任务做兜底清理工作。 值得注意的是,平台的视角是压测的状态管理,并非局限于JMeter的工作状态。
2023-05-26归属地:广东 天启老师我又有问题啦,就是如果在每个压测节点部署一个压测的agent程序,假设我理解为这个是个javaweb应用程序吧,这样就相当于压测任务开始的时候一个虚拟机上有2个java进程一个是这个javaweb程序,一个是jmeter的java进程,那么会不会存在压测的时候这个jmeter进程挤占这个javaweb程序的资源,导致这个代理程序崩溃,这种有什么好办法吗,还是说2个进程都搞成容器化,可以资源独立
天启老师我又有问题啦,就是如果在每个压测节点部署一个压测的agent程序,假设我理解为这个是个javaweb应用程序吧,这样就相当于压测任务开始的时候一个虚拟机上有2个java进程一个是这个javaweb程序,一个是jmeter的java进程,那么会不会存在压测的时候这个jmeter进程挤占这个javaweb程序的资源,导致这个代理程序崩溃,这种有什么好办法吗,还是说2个进程都搞成容器化,可以资源独立作者回复: 你好,这个agent是一个用Java编写的轻量级Lib,使用Netty与服务器进行通信,自身持有的资源很少。此外,agent所做的工作是低频的,例如:每轮测试中的同一类文件只需要传输一次,各个状态变换时下发的指令也是有限的。唯一比较消耗资源的是结果文件的聚合(消耗CPU)和回传(消耗带宽),但这一操作是在压测结束后异步进行的,因此资源消耗是错时的。 另外,agent的JVM进程和JMeter的JVM进程是隔离的,两者都有自己的堆大小和栈大小控制,只要相加不超过总的内存大小,一般不会互相影响。
2023-02-20归属地:上海- 天启老师问下,最近在使用阿里pts工具的时候,发现pts有个叫采样日志率的概念,可以看到压测过程中某些请求的详细返回信息请求信息,感觉对压测问题分析挺有用的,但是参考jmeter的实现看了一圈,我想到相对2种实现方式:1.修改jmeter的properties文件,让jtl文件中展示更多的信息展示,但是这个有很多的缺点需要消耗压测节点大量的磁盘空间,且这个结果是在压测结束后才能进行处理2.第二种方式是自己写一个backendListener插件,在钩子函数中发送sampleresult,但是这个有个难点,就是样本总数在运行时无法确定,不太好实现日志采样率。所以想问下老师这块你们的压测平台有去实现吗,想借鉴下思路
作者回复: 你好,你的问题关注的是如何获取压测流量的响应信息,我们的压测平台是通过对接JMeter的“查看结果树”控件来实现的,激活“Save Response Data”,同时勾选“仅错误日志”(一般来说,只有排障时才需要关注详细的响应信息),生成的结果文件以固定的文件名保存,压测平台的服务器会在压测后统一回传至文件存储组件供下载,默认保存7天。当然,由于查看结果树的结果文件是以流的形式实时构建的,因此我们也提供了实时查看的功能,压测平台服务器提供了后端接口,将文件内容实时读取出来,前端得到结果后展示在页面上。 查看结果树本身提供了设置响应数据最大展示大小,以及最大文档大小等参数,基于这些考虑,我们并不需要以抽样的方式获得数据。
2023-02-02归属地:上海 - 天启老师你好,我想问下通过部署agent的方式来规避master-salve的痛点的话,压测机的启动方式是以jmeter-server方式的吗,还是说是用agent,动态的进行命令行方式jmeter -n xxxx动态启动压测?
作者回复: 你好,启动方式是后者。我们完全放弃了JMeter的分布式执行策略,因此也就不再使用jmeter-server的启动方式,所有JMeter节点都视为是Master由平台统一调度。
2022-09-21归属地:上海3  菜蜗牛老师,您好, 请问您的压测平台是否是开源的呢?是的话,是否可以贴一下源码地址
菜蜗牛老师,您好, 请问您的压测平台是否是开源的呢?是的话,是否可以贴一下源码地址作者回复: 你好,我确实早有开源的计划,但因为一些限制暂时无法达成,一旦能够开源,我会及时更新,感谢你的关注
2022-05-25 追风筝的人老师 你知道客户端使用mc 工具, 服务端是3个节点的minio集群 怎样做对服务端的上传 下载 性能测试? MC这个工具怎么指定并发数
追风筝的人老师 你知道客户端使用mc 工具, 服务端是3个节点的minio集群 怎样做对服务端的上传 下载 性能测试? MC这个工具怎么指定并发数作者回复: 你好,mc工具我不太熟悉,无法提供专业的指导,非常抱歉
2022-05-17 林林总总0107老师,想问下关于线程数与TPS/QPS动态设置的时候,这里面的关系应该是怎样的?比如,执行java -jar /lib/bshclient.jar localhost 9000 update.bsh <qps>,这里面只有调整QPS/TPS,但是没有线程数的调整,是不是说只需要调整<qps>,不管线程数的调整?我看到配置集功能里面的用例也有总线程数的参数项,具体执行测试的时候这个值应该怎么去调整呢
林林总总0107老师,想问下关于线程数与TPS/QPS动态设置的时候,这里面的关系应该是怎样的?比如,执行java -jar /lib/bshclient.jar localhost 9000 update.bsh <qps>,这里面只有调整QPS/TPS,但是没有线程数的调整,是不是说只需要调整<qps>,不管线程数的调整?我看到配置集功能里面的用例也有总线程数的参数项,具体执行测试的时候这个值应该怎么去调整呢作者回复: 你好,如果需要调节QPS,线程数一般适当设大点就行了(线程数是固定值),如果线程数设的太小,达不到目标QPS,那么调节也就没意义了。当然,也不要把线程数设的太夸张,一方面压测资源不一定够,另一方面JMeter是通过间隔抛弃请求达到控制QPS的效果的,线程数太大可能会造成抖动。
2021-11-18- ask001谢谢老师之前问题的答复!老师我现在还有个疑问是看jmeter自带的InfluxdbBackendListenerClient逻辑是:BackendListener会把SampleResult丢到BlockingQueue中,BackendListener也会起一个线程从BlockingQueue中取SampleResult丢给BackendListenerClient处理。InfluxdbBackendListenerClient处理SampleResult的逻辑是最终把SampleResult加到DescriptiveStatistics中,InfluxdbBackendListenerClient会起一个定时线程池,定时利用DescriptiveStatistics先计算一下在定时时间间隔段(默认值5秒)采样到的SampleResult的统计值(比如平均响应时间、总的sample、5秒内95线等)发给influxdb。所以InfluxdbBackendListenerClient其实入influxdb的值是在定时间隔段内计算后的值。老师想问下如果是多节点每个节点都是上报给influxdb,如果用jmeter自带的InfluxdbBackendListenerClient是不是不合适?还是说自己写一个InfluxdbBackendListenerClient,把原始的采样结果入influxdb,这样方便influxdb 取数据加工(根据具体指标进行求和或求平均值等),如果是原始的采样结果入influxdb我觉得jmeter每次采样数据发influxdb会是瓶颈,影响压力机资源,同时因为用的社区版influxdb,TPS大的化influxdb也可能会是瓶颈?
作者回复: 为你的认真细致点赞!我说下我个人的理解。 对于实时数据,一般来说我们其实只需要观察一个宏观的指标概要,判断压测时的大致状况,有无风险等。而对于非实时数据,则需要计算出精确的指标(如99线等),因为我们要输出结论供详细分析和其他决策参考(限流等)。 这是压测平台将数据进行冷热分离最原始的初衷,越精确的结果,必然会带来越昂贵的计算量和资源消耗,我相信JMeter的InfluxdbBackendListener的这种处理方式,肯定也有这方面的考量。 原始的采样数据,在生成的JTL文件中都有,精确到了每个请求,我们在压测后统一回传服务器做异步处理,不存在资源瓶颈问题,用户最多只需等待几分钟。
2021-07-19 - ask001问下基于获取和展示实时数据(热数据)这块,如果要用多台压测机的化也是用master-slave 这种模式吗?这种模式压测过程中slave会把采样结果传回master机器,master机器统一计算后再入influxdb(比如5秒内的所有采样结果计算下在发送到influxdb),这种模式如果tps大的化,master是不是还会有瓶颈,还是说没用master-slave这种模式的?
作者回复: 不是传统的master-slave模式。 实时数据的采样,是每个slave在压测时直接将数据上报至InfluxDB的。每一轮压测,平台都会生成一个唯一的triggerId,所有slave上报数据时均带上值为这个triggerId的TAG,以便InfluxDB聚合。 master则是直接从InfluxDB中取出数据,进行一定的加工(根据具体指标进行求和或求平均值等),再推送数据展示到前端。 显然,master的计算量不大(而且都是用了InfluxDB自带的聚合方法),所以瓶颈一般不会出现在master。反倒是slave在上报数据时,如果TPS很高可能会出现瓶颈,关于这一点可以看一下JMeter的InfluxdbBackendListener的实现,简单说,数据上报是通过消息队列异步进行的,且这个队列是有长度上限的(可以设置),通过这种方式避免过多的影响slave的压测资源消耗。
2021-07-15

