

23 | 选型:etcd/ZooKeeper/Consul等我们该如何选择?
唐聪

该思维导图由 AI 生成,仅供参考
你好,我是唐聪。
在软件开发过程中,当我们需要解决配置、服务发现、分布式锁等业务痛点,在面对etcd、ZooKeeper、Consul、Nacos等一系列候选开源项目时,我们应该如何结合自己的业务场景,选择合适的分布式协调服务呢?
今天,我就和你聊聊主要分布式协调服务的对比。我将从基本架构、共识算法、数据模型、重点特性、容灾能力等维度出发,带你了解主要分布式协调服务的基本原理和彼此之间的差异性。
希望通过这节课,让你对 etcd、ZooKeeper、Consul 原理和特性有一定的理解,帮助你选型适合业务场景的配置系统、服务发现组件。
基本架构及原理
在详细和你介绍对比 etcd、ZooKeeper、Consul 特性之前,我们先从整体架构上来了解一下各开源项目的核心架构及原理。
etcd 架构及原理
首先是 etcd,etcd 我们知道它是基于复制状态机实现的分布式协调服务。如下图所示,由 Raft 共识模块、日志模块、基于 boltdb 持久化存储的状态机组成。
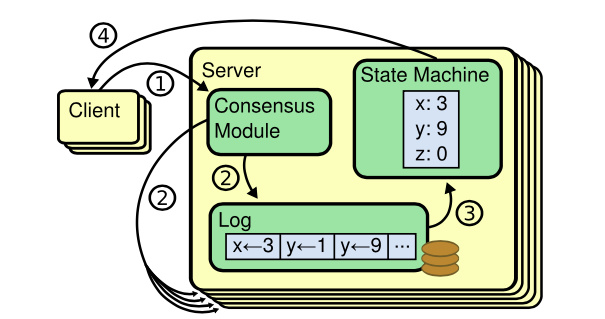
以下是 etcd 基于复制状态机模型的写请求流程:
client 发起一个写请求(put x = 3);
etcdserver 模块向 Raft 共识模块提交请求,共识模块生成一个写提案日志条目。若 server 是 Leader,则把日志条目广播给其他节点,并持久化日志条目到 WAL 中;
当一半以上节点持久化日志条目后,Leader 的共识模块将此日志条目标记为已提交(committed),并通知其他节点提交;
etcdserver 模块从 Raft 共识模块获取已经提交的日志条目,异步应用到 boltdb 状态机存储中,然后返回给 client。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

分布式协调服务是构建分布式系统的关键组件,选择合适的服务对业务至关重要。本文从多个维度对比了etcd、ZooKeeper、Consul这三种服务的架构、原理和功能特性。在共识算法方面,etcd基于Raft算法确保数据一致性,Consul采用Gossip协议和Raft共识算法,支持多数据中心容灾,而ZooKeeper使用Zab协议可能返回stale data。在并发原语、健康检查、服务发现、数据模型、Watch特性、多数据中心等方面,三者也有各自的特点和限制。Consul提供了原生的分布式锁、健康检查、服务发现机制支持,对多数据中心的支持也是其亮点。最后,根据业务需求和技术特点选择合适的分布式协调服务至关重要。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《etcd 实战课》,新⼈⾸单¥59
《etcd 实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(8)
- 最新
- 精选
 金时线性读和强一致读有什么区别?
金时线性读和强一致读有什么区别?作者回复: 没区别,强一致性也叫线性一致性
2021-09-012 kkxue
kkxue 我觉得pingcap的这个方案可行: https://github.com/etcd-io/etcd/issues/11357 https://pingcap.com/blog-cn/geographic-data-distribution-traffic-and-latency-halved/ "这里我们引入了一个新概念 Group,每一个 Raft 节点都有一个对应的 Group ID,拥有相同 Group ID 的节点即在同一个数据中心中。既然有了每个 Raft 节点的 Group 信息,Leader 就可以在广播消息时在每一个 Group 中选择一个代理人节点(我们称为 Follower Delegate),将整个 Group 成员所需要的信息发给这个代理人,代理人负责将数据同步给 Group 内的其他成员"2021-03-1510
我觉得pingcap的这个方案可行: https://github.com/etcd-io/etcd/issues/11357 https://pingcap.com/blog-cn/geographic-data-distribution-traffic-and-latency-halved/ "这里我们引入了一个新概念 Group,每一个 Raft 节点都有一个对应的 Group ID,拥有相同 Group ID 的节点即在同一个数据中心中。既然有了每个 Raft 节点的 Group 信息,Leader 就可以在广播消息时在每一个 Group 中选择一个代理人节点(我们称为 Follower Delegate),将整个 Group 成员所需要的信息发给这个代理人,代理人负责将数据同步给 Group 内的其他成员"2021-03-1510 骑着🚀看银河按照这个比较ETCD并没有胜出啊,反而Consul是最佳选择,哈哈哈2022-03-1715
骑着🚀看银河按照这个比较ETCD并没有胜出啊,反而Consul是最佳选择,哈哈哈2022-03-1715- 残天噬魂额,老师这么一比较,我感觉除了语言契合度之外,consul就应该是第一选择啊,哈哈2021-12-313
- kkxue还有这个方案就是直接将不同数据中心的延时降低!如同local datacenter,传闻google做到了2021-03-1522
 初学者关于同城双az高可用,有一些问题想和老师探讨一下: 如果我想采用2+2部署方案,也就一个集群4个节点平均部署到两个机房,这样的好处是一个az跪了,能保证另一个az肯定有节点上的数据是完整的,坏处是任何一个az挂了,服务就立即不可用,要有一个手动恢复的流程,我这里想请教一下老师,当前etcd只发现一种通过force-new-cluster的参数也通过某一个节点的数据恢复集群,有什么优雅的方式知道正常的az中两个节点中哪个节点数据最新? 像zk这种,我完全可以在正常az中新扩容一个新节点,修改集群member配置信息,然后在正常的az中恢复出一个3节点的集群,而且也只能新扩容的节点需要复制集群数据,etcd好像不支持这种玩法。2021-12-091
初学者关于同城双az高可用,有一些问题想和老师探讨一下: 如果我想采用2+2部署方案,也就一个集群4个节点平均部署到两个机房,这样的好处是一个az跪了,能保证另一个az肯定有节点上的数据是完整的,坏处是任何一个az挂了,服务就立即不可用,要有一个手动恢复的流程,我这里想请教一下老师,当前etcd只发现一种通过force-new-cluster的参数也通过某一个节点的数据恢复集群,有什么优雅的方式知道正常的az中两个节点中哪个节点数据最新? 像zk这种,我完全可以在正常az中新扩容一个新节点,修改集群member配置信息,然后在正常的az中恢复出一个3节点的集群,而且也只能新扩容的节点需要复制集群数据,etcd好像不支持这种玩法。2021-12-091 Fis.3AZ的或者3地域的直接跨区域部署就行了,就是时延需要考虑及优化,双AZ的比较复杂。 方案1:etcd集群2+1部署,引入全局仲裁服务,自己做一个agent,根据仲裁服务的信息,管理etcd节点升主或降备,破坏了原有raft协议 方案2:两个etcd集群,开发专门的数据同步工具或者开源make mirror,主备集群模式。两个集群revision无法一致 方案3:区域1主集群,区域2部署3个learner,故障时区域2升主。 上面几种方案那种更好呢?还有其他好的方案吗?2021-12-24
Fis.3AZ的或者3地域的直接跨区域部署就行了,就是时延需要考虑及优化,双AZ的比较复杂。 方案1:etcd集群2+1部署,引入全局仲裁服务,自己做一个agent,根据仲裁服务的信息,管理etcd节点升主或降备,破坏了原有raft协议 方案2:两个etcd集群,开发专门的数据同步工具或者开源make mirror,主备集群模式。两个集群revision无法一致 方案3:区域1主集群,区域2部署3个learner,故障时区域2升主。 上面几种方案那种更好呢?还有其他好的方案吗?2021-12-24 mckeeetcd一般可以采用同一个region下跨可用区部署,最好每个可用区部署一台2021-11-17
mckeeetcd一般可以采用同一个region下跨可用区部署,最好每个可用区部署一台2021-11-17
收起评论

