

13 | db大小:为什么etcd社区建议db大小不超过8G?

该思维导图由 AI 生成,仅供参考
分析整体思路
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

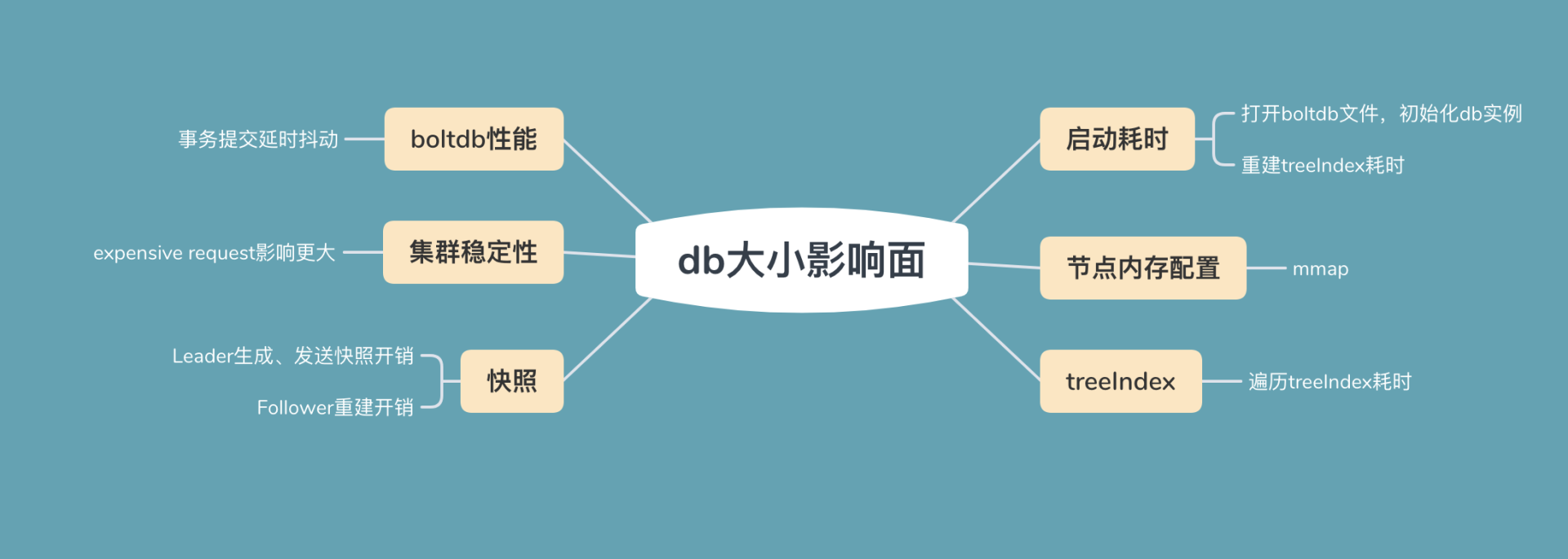
etcd数据库大小对集群性能的影响 etcd数据库大小对集群性能的影响是一个重要的技术议题。根据etcd社区的建议,将数据库大小限制在8G以内可以避免对集群性能和稳定性造成影响。文章通过分析大数据量etcd集群的案例,探讨了数据库大小对集群性能的影响。大数据库文件会导致etcd启动耗时增加,可能引起缺页文件中断,影响服务稳定性和性能。此外,大数据库文件还会影响treeIndex索引性能、boltdb性能、集群稳定性和快照生成等方面。文章还介绍了构造大数据量集群的过程,并分析了启动耗时、节点内存配置和treeIndex的影响。另外,文章还介绍了boltdb性能、集群稳定性和快照生成等方面的影响。文章提到了etcd社区在bbolt项目中实现了基于hashmap来管理freelist,以优化boltdb事务提交的性能。此外,文章还介绍了expensive request对集群稳定性的影响,以及大数据库文件对快照功能的影响。总的来说,大数据库文件会影响etcd集群的启动耗时、节点内存配置、treeIndex的性能、boltdb性能、集群稳定性和快照生成速度。文章内容丰富,深入探讨了etcd数据库大小对集群性能的多方面影响,对于使用etcd的技术人员具有重要的参考价值。
《etcd 实战课》,新⼈⾸单¥59

全部留言(12)
- 最新
- 精选
 雾雾glu请教一下老师: 看到阿里贡献的 cncf 博客中提到了,优化了算法后可以将存储提升至 100G: https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/#Conclusion 但是在官方文档中,还是写着的是 8G,不确定这个数据是否是最新的?
雾雾glu请教一下老师: 看到阿里贡献的 cncf 博客中提到了,优化了算法后可以将存储提升至 100G: https://www.cncf.io/blog/2019/05/09/performance-optimization-of-etcd-in-web-scale-data-scenario/#Conclusion 但是在官方文档中,还是写着的是 8G,不确定这个数据是否是最新的?作者回复: 目前依然是8G,阿里提的PR就是文中说的使用hashmap来管理boltdb freelist, 它解决了boltdb文件特别大(>20G)场景下的freelist管理瓶颈。除了boltdb本身瓶颈,文中我给出了很多其他影响面,比如etcd启动耗时,一个14G,100万的key就启动接近2分钟,还有expensive request对大数据量etcd集群影响特别大, 因为etcd存储的key-value数据都是在一个bucket里面,目前etcd没有任何QoS机制,一旦不小心发起一个遍历大量key的查询就容易出现各种稳定性问题了。
2021-02-25210- fran712请问老师: etcd的数据容量是直接查看数据目录的大小?还是通过prometheus等监控手段查看?还是通过API或命令查看?
作者回复: 一般我们都是通过prometheus采集etcd metrics,配置grafana视图查看的,db 大小的metrics是这个etcd_debugging_mvcc_db_total_size_in_bytes
2021-02-2229  冬至未至求教大佬: “将 limit 参数下推到了索引层,实现查询性能百倍提升” 这个下推到索引层,具体是怎么样的操作呢?
冬至未至求教大佬: “将 limit 参数下推到了索引层,实现查询性能百倍提升” 这个下推到索引层,具体是怎么样的操作呢?作者回复: 是这样的,我举个例子,没这个优化之前,如果你有1百万的key,你查询个limit 1,treeIndex也会返回上百万的key给上层,如果把这个limit参数下推到treeIndex模块后,找到满足条件的limt数就直接返回了。
2021-02-2524 写点啥呢请问下老师: 1. etcd启动时候构建treeindex为什么需要加锁?如果构建时候是单goroutine是否可以避免加锁操作? 2. ./benchmark put --key-size 32 --val-size 10240 --total 1000000 --key-space-size 2000000 --clients 50 --conns 50 这个命令total参数是1个M,为啥会插入1.2M个key呢?
写点啥呢请问下老师: 1. etcd启动时候构建treeindex为什么需要加锁?如果构建时候是单goroutine是否可以避免加锁操作? 2. ./benchmark put --key-size 32 --val-size 10240 --total 1000000 --key-space-size 2000000 --clients 50 --conns 50 这个命令total参数是1个M,为啥会插入1.2M个key呢?作者回复: 1. treeIndex在启动时和运行过程中,可能存在多个goroutine并发访问的情况下,比如还有compaction异步任务也会操作它。我这里说的阻塞在锁上,实际上是我之前尝试将构建treeIndex改成并行,因为默认只有1个goroutine串行构建的,发现效果依然不佳,我完善下描述。 2. 下面写了会执行一系列这样的命令,value也有变化,直到压测到14Gdb大小左右,key 1.2M个。
2021-02-1721 @%初%@请问老师: 在提到提交事务延迟过高,有freelist的原因,原因是申请n个page会增加耗时,我没理解的是: freelist本就是空闲列表,直接取n个就可以了,为什么会增加耗时呢?难道是申请n个连续的内存?
@%初%@请问老师: 在提到提交事务延迟过高,有freelist的原因,原因是申请n个page会增加耗时,我没理解的是: freelist本就是空闲列表,直接取n个就可以了,为什么会增加耗时呢?难道是申请n个连续的内存?作者回复: 嗯,是的,是申请连续的若干个空闲page
2021-03-302 lidabai如何查看etcd中db的大小?2022-06-2511
lidabai如何查看etcd中db的大小?2022-06-2511 int8长事务导致db增大是因为长事务可能会阻塞压缩任务的执行么?2021-06-181
int8长事务导致db增大是因为长事务可能会阻塞压缩任务的执行么?2021-06-181 愁脾气的愁妖精想问就是如果etcd有一次设置quato-backend-bytes为4G之后,是保持这个配额大小吗,还是停掉之后把这个配置删掉之后重启就又变成了2G,那如果之前内存已经是3G多呢2021-12-15
愁脾气的愁妖精想问就是如果etcd有一次设置quato-backend-bytes为4G之后,是保持这个配额大小吗,还是停掉之后把这个配置删掉之后重启就又变成了2G,那如果之前内存已经是3G多呢2021-12-15 惘 闻为什么长事务会导致db增大呢?2021-08-061
惘 闻为什么长事务会导致db增大呢?2021-08-061 天照请问唐老师是否遇到过这种情况: 当DBsize较大时,而且集群处理的写入请求较高时,要保证调用业务无损情况下,单节点重启、动态扩容操作失败2021-07-07
天照请问唐老师是否遇到过这种情况: 当DBsize较大时,而且集群处理的写入请求较高时,要保证调用业务无损情况下,单节点重启、动态扩容操作失败2021-07-07

