

02 | 基础架构:etcd一个读请求是如何执行的?

该思维导图由 AI 生成,仅供参考
基础架构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

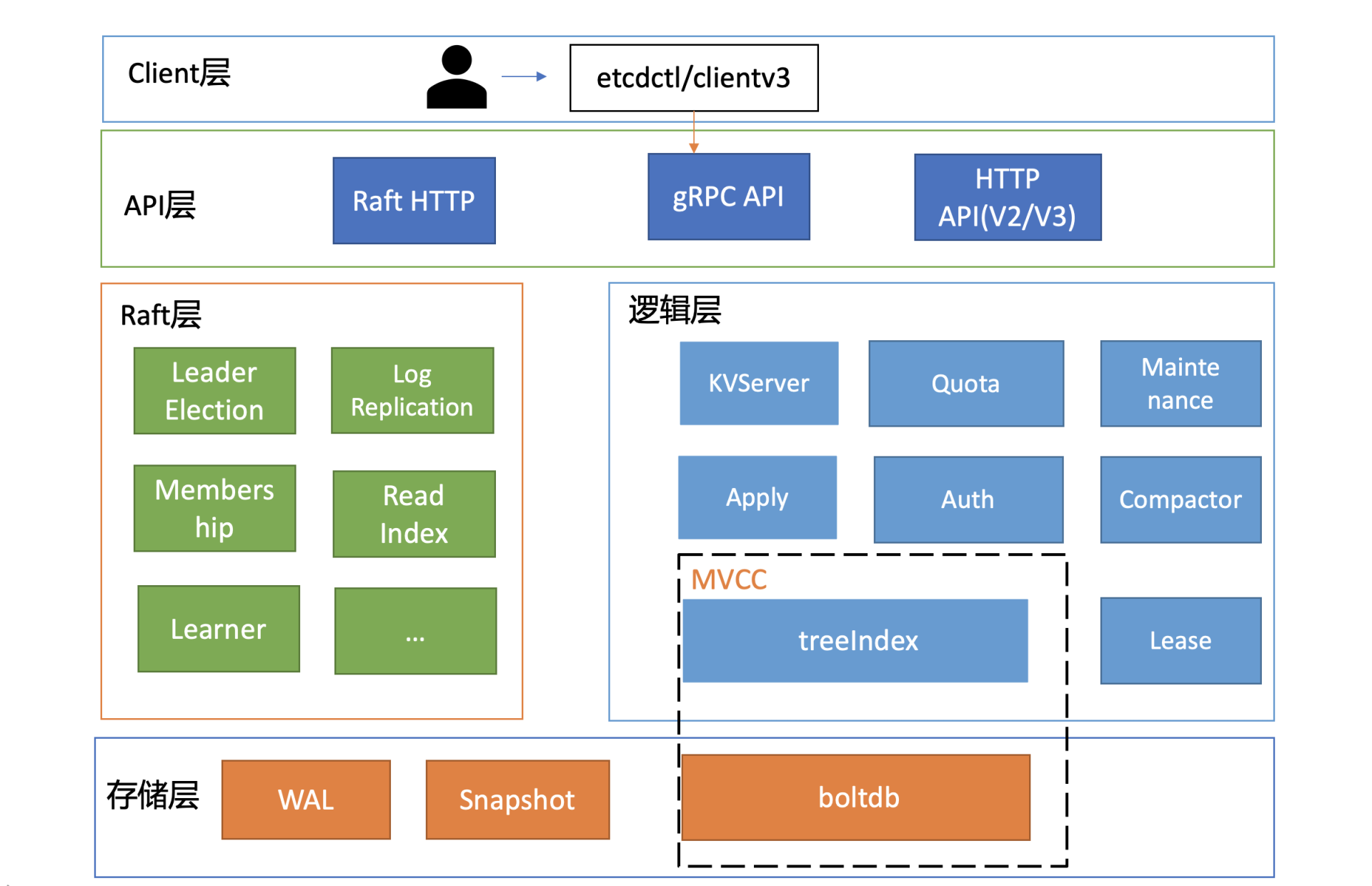
etcd v3的基础架构包括Client层、API网络层、Raft算法层、逻辑层和存储层。在读请求执行过程中,etcdctl首先解析命令参数,然后选择合适的etcd server节点进行负载均衡,使用基于HTTP/2的gRPC协议与server通信。接着进入KVServer模块,其中拦截器提供了请求前后的hook能力,实现了诸如debug日志、metrics统计、对etcd Learner节点请求接口和参数限制等特性。最后,handler将请求转发到对应的实现,通过调用KVServer模块的Range接口获取数据。整体而言,etcd v3的基础架构通过各个模块的协作,实现了高性能、低延迟的读请求执行流程。 在多节点etcd集群中,各个节点的状态机数据一致性存在差异。etcd提供了串行读和线性读两种模式,分别适用于对数据一致性要求不高和要求高的场景。线性读通过ReadIndex机制保证数据一致性,确保最新的数据已经应用到状态机中。此外,MVCC模块解决了etcd v2不支持保存key的历史版本、不支持多key事务等问题,通过内存树形索引模块和嵌入式的KV持久化存储库boltdb实现多版本并发控制。整个读请求执行流程经过多个模块的协作,保证了数据一致性和高性能。 总体而言,etcd v3的读请求执行流程经历了负载均衡、拦截器处理、Raft协议通信、数据一致性保证和多版本并发控制等环节,为用户提供了高性能、低延迟的读取体验。
《etcd 实战课》,新⼈⾸单¥59

全部留言(68)
- 最新
- 精选
- hiroshi老师,readIndex 需要请求 leader,那为啥不直接让 leader 返回读请求的结果,而要等待自己的进度赶上 leader?
作者回复: 非常好的问题,我个人认为主要还是性能因素,我记得etcd v2早期的时候如果你指定线性读/共识读,它就是直接转发给leader的。后来在etcd v3.0中实现了raft log read但是要走一遍raft log,读涉及到磁盘IO,v3.1中引入了readIndex机制,它是非常轻量级的,开销较小,相比各个follower都转发给leader会导致leader负载较高,特别是expensive request场景,性能会急剧下降,leader的内存、cpu、网络带宽资源都很容易耗尽,readIndex机制的引入,使得每个follower节点都可以处理读请求,极大扩展提升了写性能。
2021-02-16869  姜姜老师,文中有些地方不太明白: 1, KVServer中的拦截器 我认为它只是作为一个辅助的功能吧,用于实现一些观测功能。但对于一个普通的读请求,是否必须通过拦截器才能完成读取数据的操作? 2, 文中“handler 首先会将上面描述的一系列拦截器串联成一个执行” 这段话中,拦截器是一系列的,一系列是指会有多个拦截器吗?难道不是一个请求只注册一个拦截器吗,还能注册多个?为什么要注册多个? “串联成一个执行”,如何串联成一个?将多个拦截器串联成一个拦截器? 3, 串行读与线性读 这里我理解串行读是“非强一致性读”,线性读是“强一致性读”,对吗? 而且这里的“串行”总让我想到“并行/串行”的概念,不知有关系吗? 4, ReadIndex,committed index,applied index 这几种索引底层实现是一样的吗,它们的数据结构是怎样的?是对同一份数据,分别建立不同的索引?又为什么建立这么多种索引? 5,版本号 您说是一个递增的全局ID, revision{2, 0},ID指的是2还是0? 版本号的格式是怎样的,另一个数字代表什么? 6, bucket 请问一个 bucket 相当于一整个 B+ tree 索引树吗?还是相当于 B+ tree 中一个节点?
姜姜老师,文中有些地方不太明白: 1, KVServer中的拦截器 我认为它只是作为一个辅助的功能吧,用于实现一些观测功能。但对于一个普通的读请求,是否必须通过拦截器才能完成读取数据的操作? 2, 文中“handler 首先会将上面描述的一系列拦截器串联成一个执行” 这段话中,拦截器是一系列的,一系列是指会有多个拦截器吗?难道不是一个请求只注册一个拦截器吗,还能注册多个?为什么要注册多个? “串联成一个执行”,如何串联成一个?将多个拦截器串联成一个拦截器? 3, 串行读与线性读 这里我理解串行读是“非强一致性读”,线性读是“强一致性读”,对吗? 而且这里的“串行”总让我想到“并行/串行”的概念,不知有关系吗? 4, ReadIndex,committed index,applied index 这几种索引底层实现是一样的吗,它们的数据结构是怎样的?是对同一份数据,分别建立不同的索引?又为什么建立这么多种索引? 5,版本号 您说是一个递增的全局ID, revision{2, 0},ID指的是2还是0? 版本号的格式是怎样的,另一个数字代表什么? 6, bucket 请问一个 bucket 相当于一整个 B+ tree 索引树吗?还是相当于 B+ tree 中一个节点?作者回复: 谢谢你的提问,我先简单快速回答下,后面不清楚的再写答疑文章深入解答 问题1和2是gRPC拦截器相关知识我推荐你看下这篇文章https://zhuanlan.zhihu.com/p/80023990 问题3你理解串行读是“非强一致性读”,线性读是“强一致性读”没问题,至于串行含义并非你想的那样,你可以参考下维基百科的定义, 09事务篇我也会介绍事务隔离中的串行化 https://en.wikipedia.org/wiki/Serializability 问题4 建议先去阅读下04 raft篇,它本值上就是一个uint64的索引,表示日志条目序号 问题5,{2,0}={major,sub} 2是etcd mvcc事务版本号全局递增,0是事务内子版本号随修改操作递增(比如一个txn事务中多个put/delete操作,其会从0递增),07 mvcc会详细介绍 问题6,一个bucket对应一个颗B+tree
2021-01-26629- 小军请问老师,当Readindex结束并等待本节点的状态机apply的时候,key又被最新的更新请求给更新了怎么办,这个时候读取到的value是不是又是旧值了
作者回复: 线性读,读出来的值实际上是你发出读请求时间点的集群最新共识数据,在你读请求发出后,若耗时一定时间还未完成,在这过程中leader又收到了写请求更新了它, 的确你原来读出来的值相比最新的集群共识就是旧的,在实际应用中,我们一般会通过增加版本号检测识别此类问题,后面事务篇会详细和你介绍
2021-01-2624  chapin没有基础,学习这个,可能会比较吃力。
chapin没有基础,学习这个,可能会比较吃力。作者回复: 没关系的,可以先大概看一篇,了解整个流程,不懂什么地方可以等学完后面后,回过头来再看就非常亲切了,后面每节中都有etcd特性体验案例,建议你跟着我一起实际操作下,比如02你就先准备好环境,能用goreman快速启一个多节点集群,也可以自己直接二进制启动一个单节点集群,然后体验一下get,put命令,随着后面的学习你会越来越了解etcd
2021-01-2611 站在树上的松鼠老师,下面这句话没有理解到,麻烦解答下呢,谢谢! 在client 3.4之前的版本中,负载均衡算法有一个严重的Bug:如果第一个节点异常了,可能会导致你的client访问etcd server异常。 (1)这里第一个节点怎么理解呢? 是指的负载均衡刚好选中的那个etcd server节点异常吗? (2)如果访问的节点异常了,是client库中会做重试机制,还是业务代码需要做重试呢?
站在树上的松鼠老师,下面这句话没有理解到,麻烦解答下呢,谢谢! 在client 3.4之前的版本中,负载均衡算法有一个严重的Bug:如果第一个节点异常了,可能会导致你的client访问etcd server异常。 (1)这里第一个节点怎么理解呢? 是指的负载均衡刚好选中的那个etcd server节点异常吗? (2)如果访问的节点异常了,是client库中会做重试机制,还是业务代码需要做重试呢?作者回复: 感谢超凡帮忙解答第一点,第二点取决于rpc方法,range clientv3库有重试策略,参考一下这个文件clientv3/retry.go
2021-01-2247 jeffery干货太多需要慢慢消化!老师能把课程代码放到github上吗……谢谢老师
jeffery干货太多需要慢慢消化!老师能把课程代码放到github上吗……谢谢老师作者回复: 嗯,不清楚的地方不要急,后面的每节会帮助你一个个解开疑问
2021-01-227 Want less当收到一个线性读请求时,它首先会从 Leader 获取集群最新的已提交的日志索引 (committed index)。 所有的client请求不是应该都通过leader下发至follower吗?
Want less当收到一个线性读请求时,它首先会从 Leader 获取集群最新的已提交的日志索引 (committed index)。 所有的client请求不是应该都通过leader下发至follower吗?作者回复: 不是的哈,follower节点也可以处理读请求的,只是线性读时需要向leader发送readindex消息,然后确保本节点数据是最新的
2021-01-2745 Alery请教一个问题,在treeIndex中查询key对应的版本号,这里是会返回当前key的所有版本号吗?
Alery请教一个问题,在treeIndex中查询key对应的版本号,这里是会返回当前key的所有版本号吗?作者回复: 嗯,每个key在treeIndex中有一个对应的数据结构keyIndex,它保存了所有版本号(若未压缩),07讲mvcc将详细介绍
2021-01-265 yayiyaya问答: etcd 在执行读请求过程中涉及磁盘 IO 吗? 答: 涉及到磁盘, 当读请求从treeIndex获取到用户的 key 和相关版本号信息后,去查询value值时, 没有命中 buffer, 会从boltdb获取数据, 这个时候就涉及到了磁盘。
yayiyaya问答: etcd 在执行读请求过程中涉及磁盘 IO 吗? 答: 涉及到磁盘, 当读请求从treeIndex获取到用户的 key 和相关版本号信息后,去查询value值时, 没有命中 buffer, 会从boltdb获取数据, 这个时候就涉及到了磁盘。作者回复: etcd启动的时候通过mmap将db文件映射到内存,会告诉内核预读文件,下一讲给了参考答案
2021-02-0424 于途如果你的 client 版本 <= 3.3,那么当你配置多个 endpoint 时,负载均衡算法仅会从中选择一个 IP 并创建一个连接(Pinned endpoint) 请问,此句提到的负载均衡算法是否等同:随机选中某个IP?
于途如果你的 client 版本 <= 3.3,那么当你配置多个 endpoint 时,负载均衡算法仅会从中选择一个 IP 并创建一个连接(Pinned endpoint) 请问,此句提到的负载均衡算法是否等同:随机选中某个IP?作者回复: 嗯,可以理解为随机,首先它会尝试连接所有etcd节点,连接建立后选择一个固定的长连接,其他关闭
2021-01-224

