

17 | 性能及稳定性(下):如何优化及扩展etcd性能?

该思维导图由 AI 生成,仅供参考
性能分析链路
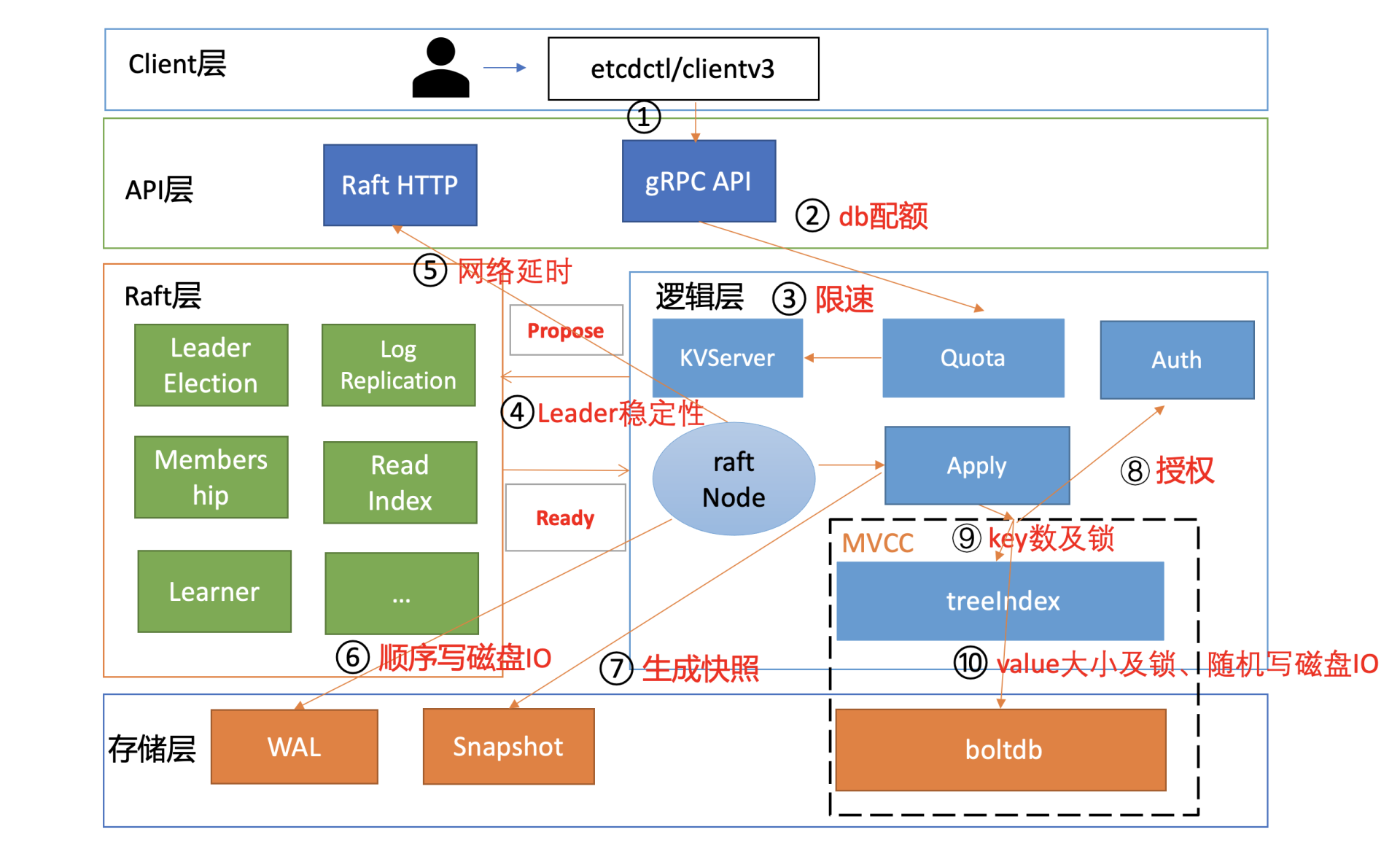
db quota
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

etcd性能优化及扩展方法 本文深入探讨了如何优化和扩展etcd性能,从多个方面提出了解决方案。首先,针对写性能,文章介绍了如何优化db quota、限速、心跳及选举参数,以及网络和磁盘IO延时,建议根据业务场景调整db quota大小,并配置合适的压缩策略,以提升写性能和稳定性。其次,针对大value的影响,建议将写入的key-value大小调整为合理范围,避免频繁更新大key,以减少内存突增和网络带宽资源瓶颈。此外,针对boltdb锁的影响,文章介绍了etcd的性能优化历史,并提出了并发读特性的核心原理,有效降低了写请求的延时。最后,针对扩展性能,文章提出了gRPC proxy组件的应用,包括扩展读、扩展watch和扩展Lease的机制,以提升etcd的读写性能和负载均衡能力。 通过深入的性能分析链路图和优化实践,为读者提供了一系列优化etcd性能的方法和建议,对于使用etcd的开发人员和系统管理员具有一定的参考价值。
《etcd 实战课》,新⼈⾸单¥59

全部留言(7)
- 最新
- 精选
 Coder老师,请问一下如果业务写多读少,有什么优化办法?难道不能用etcd
Coder老师,请问一下如果业务写多读少,有什么优化办法?难道不能用etcd作者回复: 1. 首先尽量选择高配的节点,各个节点之间尽量就近部署,使节点之间RTT延时尽量低,然后可使用本地SSD,并结合业务场景,构造一定的数据量,通过benchmark工具压测下,评估压测性能是否能满足业务诉求 2. 若无法满足,评估业务若存在多种路径的key写入,能否垂直拆分下,不同路径下的key,写入到不同etcd集群,比如kubernetes集群的主集群数据与event分离部署也是这样的思路 3. 评估业务上层能否支持多实例etcd集群,比如你要搞个任务系统,假设几十万的的节点,每个节点通过watch机制监听自己路径下的任务key,若任务系统的QPS较大,你可以通过多etcd集群来支持,一组节点分配一个etcd集群。然后你可以通过引入一个调度服务来给各个节点分配etcd集群,agent启动时,通过调度服务请求分配一个etcd集群,若未调度,则按一定的策略,比如etcd集群的负载情况分配一个负载最低给新增的agent,有了调度结果后,随后agent就知道监听哪个etcd集群了。随着节点数增多,你可以平行扩容etcd集群。 4. 确定是否真的依赖etcd的一些特性,可以在方案选型中,评估其他方案,比如redis等,写性能更好,还有底层存储引擎使用LSM实现的leveldb/rocksdb等,也是非常好的候选方案
2021-02-2717- dbo文中下面两句话里的平均延时错了,看图中的结果,应该分别是18.9ms和27.9ms。 下面是 SSD 盘集群,执行如下 benchmark 命令的压测结果,写 QPS 51298,平均延时 189ms。 下面是非 SSD 盘集群,执行同样 benchmark 命令的压测结果,写 QPS 35255,平均延时 279ms。2022-05-012
 初学者有2个问题请教一下 1. leader和follower的心跳哪些操作需要落盘操作,为什么磁盘io会影响心跳,进而影响选举? 2. 写请求给client返回成功时,我的理解是leader已经apply了这次写操作的raftlog,为啥还会出现applied index远小于committed index的情况?2021-11-3021
初学者有2个问题请教一下 1. leader和follower的心跳哪些操作需要落盘操作,为什么磁盘io会影响心跳,进而影响选举? 2. 写请求给client返回成功时,我的理解是leader已经apply了这次写操作的raftlog,为啥还会出现applied index远小于committed index的情况?2021-11-3021 jiapeish唐老师,文中提到CPU较高时会出现发送心跳的goroutine出现饥饿,这是问什么呢?按说CPU是公平调度,问什么刚好发送心跳的协程会卡呢,这个情况能用nice值之类的解决吗2021-04-0211
jiapeish唐老师,文中提到CPU较高时会出现发送心跳的goroutine出现饥饿,这是问什么呢?按说CPU是公平调度,问什么刚好发送心跳的协程会卡呢,这个情况能用nice值之类的解决吗2021-04-0211 Adam老师,gRPC proxy跟我前端用一个LB负载均衡有什么区别不?2022-03-09
Adam老师,gRPC proxy跟我前端用一个LB负载均衡有什么区别不?2022-03-09
 雄鹰老师你好,刚才的问题还没描述完,一不小心点击了“发布”,就直接给发布成功了,不好意思,忽略前一条。我重新描述一下问题。 假设有1000把锁,每把锁有10个线程争抢申请加锁,即1万并发申请加1000锁,线上使用可能短期不会出现这么高的并发量,或者场景有不合理的,请老师指点(申请加锁时,申请加锁重试时间上限时间是8秒,锁持有时间上限是2分钟),5个节点的etcd集群(云服务器,单节点配置 CPU 4核,内存8GB 磁盘是SSD,部署配置采用默认,版本是3.5.2),每十分钟执行一次1万个并发申请加锁(单个key value都不大),持续压测2个多小时,发现etcd集群leader节点内存使用明显比其他4个节点多,再持续压测1个小时左右,leader节点的内存使用耗光,开始的leader节点直接宕机了。请教老师,针对这种情况如何来详细分析及优化?非常感谢。2022-03-03
雄鹰老师你好,刚才的问题还没描述完,一不小心点击了“发布”,就直接给发布成功了,不好意思,忽略前一条。我重新描述一下问题。 假设有1000把锁,每把锁有10个线程争抢申请加锁,即1万并发申请加1000锁,线上使用可能短期不会出现这么高的并发量,或者场景有不合理的,请老师指点(申请加锁时,申请加锁重试时间上限时间是8秒,锁持有时间上限是2分钟),5个节点的etcd集群(云服务器,单节点配置 CPU 4核,内存8GB 磁盘是SSD,部署配置采用默认,版本是3.5.2),每十分钟执行一次1万个并发申请加锁(单个key value都不大),持续压测2个多小时,发现etcd集群leader节点内存使用明显比其他4个节点多,再持续压测1个小时左右,leader节点的内存使用耗光,开始的leader节点直接宕机了。请教老师,针对这种情况如何来详细分析及优化?非常感谢。2022-03-03- Turing写完之后是要触发watcher的. watcher过多, 查找, 发送event, 时间会稍微增加, 以及内存增大.2021-08-22

