

14 | 延时:为什么你的etcd请求会出现超时?
唐聪

该思维导图由 AI 生成,仅供参考
你好,我是唐聪。
在使用 etcd 的过程中,你是否被日志中的"apply request took too long"和“etcdserver: request timed out"等高延时现象困扰过?它们是由什么原因导致的呢?我们应该如何来分析这些问题?
这就是我今天要和你分享的主题:etcd 延时。希望通过这节课,帮助你掌握 etcd 延时抖动、超时背后的常见原因和分析方法,当你遇到类似问题时,能独立定位、解决。同时,帮助你在实际业务场景中,合理配置集群,遵循最佳实践,尽量减少 expensive request,避免 etcd 请求出现超时。
分析思路及工具
首先,当我们面对一个高延时的请求案例后,如何梳理问题定位思路呢?
这里我们再回顾下 03 中介绍的,Leader 收到一个写请求,将一个日志条目复制到集群多数节点并应用到存储状态机的流程(如下图所示),通过此图我们看看写流程上哪些地方可能会导致请求超时呢?
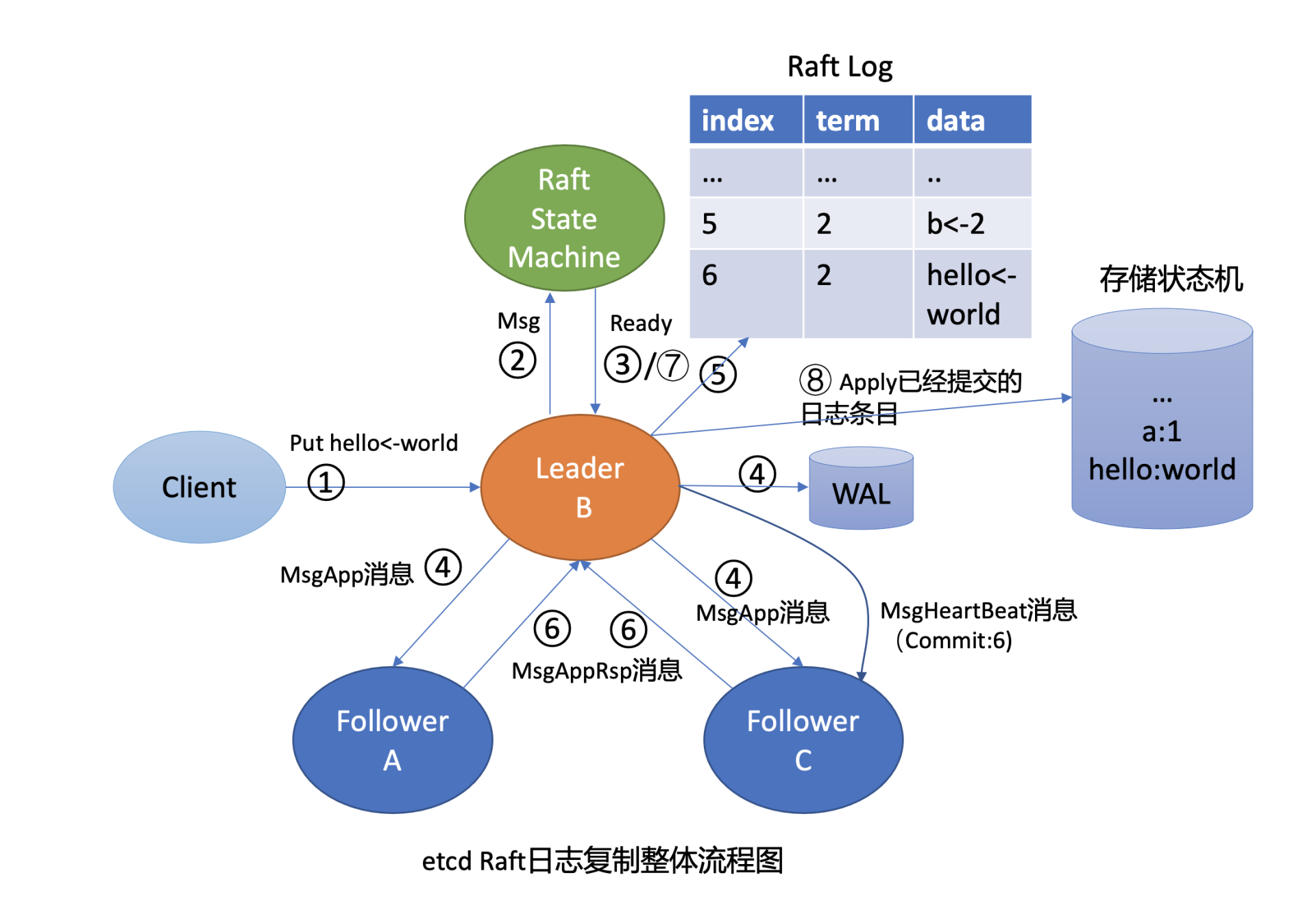
首先是流程四,一方面,Leader 需要并行将消息通过网络发送给各 Follower 节点,依赖网络性能。另一方面,Leader 需持久化日志条目到 WAL,依赖磁盘 I/O 顺序写入性能。
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入分析了etcd请求超时问题的定位方法和原因,为读者提供了解决该问题的实用指南。文章强调了了解etcd的核心链路和掌握相关工具的重要性,包括网络模块可能出现的瓶颈点、磁盘I/O对etcd性能的影响以及etcd 3.4版本后实现的trace特性。通过详细介绍网络异常导致的延时抖动的定位方法和原因,以及磁盘I/O异常的解决方法,帮助读者更好地理解和解决etcd在实际应用中可能遇到的性能问题。文章还提供了一些案例和思考题,帮助读者更好地应对etcd延时抖动。整体而言,本文为读者提供了全面的解决etcd请求超时问题的实用指南,具有很高的实用价值。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《etcd 实战课》,新⼈⾸单¥59
《etcd 实战课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(6)
- 最新
- 精选
 jeffery能规避 expensive request,大包请求导致的延迟吗
jeffery能规避 expensive request,大包请求导致的延迟吗作者回复: 没法规避,只能通过尽量高配的机器配置来缓解,业务尽量避免大量key的查询操作,建议参考kubernetes的Informer机制优化expensive request,一般情况下只需要启动的时候查询一次,后面通过watch机制实时获取数据变化就好,kubernetes节我会详细介绍下
2021-02-239 kingstone老师您好,请问关于etcd grafana监控,grafana.com上有没有比较好用的dashboards?
kingstone老师您好,请问关于etcd grafana监控,grafana.com上有没有比较好用的dashboards?作者回复: grafana官网提供了一个,你可以看看 https://grafana.com/grafana/dashboards/3070 etcd社区也提供了个 https://github.com/etcd-io/etcd/blob/v3.4.9/Documentation/op-guide/grafana.json
2021-03-192 八台上想问一下出现这个错 etcdserver: request timed out , 客户端进行重拾处理吗? 谢谢
八台上想问一下出现这个错 etcdserver: request timed out , 客户端进行重拾处理吗? 谢谢作者回复: 这个超时时间默认比较长了,最好根据内存和磁盘、grpc请求和延时监控查清楚,当时发生了什么,找到root cause。
2021-08-263 石小感谢唐老师,干货,实用。老师后期会讲etcd典型的应用场景(比如服务发现)和注意事项吗?
石小感谢唐老师,干货,实用。老师后期会讲etcd典型的应用场景(比如服务发现)和注意事项吗?作者回复: 嗯,明天21分布式锁更新会说说分布式锁常见问题
2021-03-08 宝仔老师问下,为什么磁盘IO波动会引起leader切换2022-04-133
宝仔老师问下,为什么磁盘IO波动会引起leader切换2022-04-133 柒城老师你好,我在使用集群时出现一直打印etcdserver: request timed out。然后看了一个节点坏了,但是磁盘并没有坏,除了io延时套可能造成的原因还有哪些?2021-06-22
柒城老师你好,我在使用集群时出现一直打印etcdserver: request timed out。然后看了一个节点坏了,但是磁盘并没有坏,除了io延时套可能造成的原因还有哪些?2021-06-22
收起评论

