

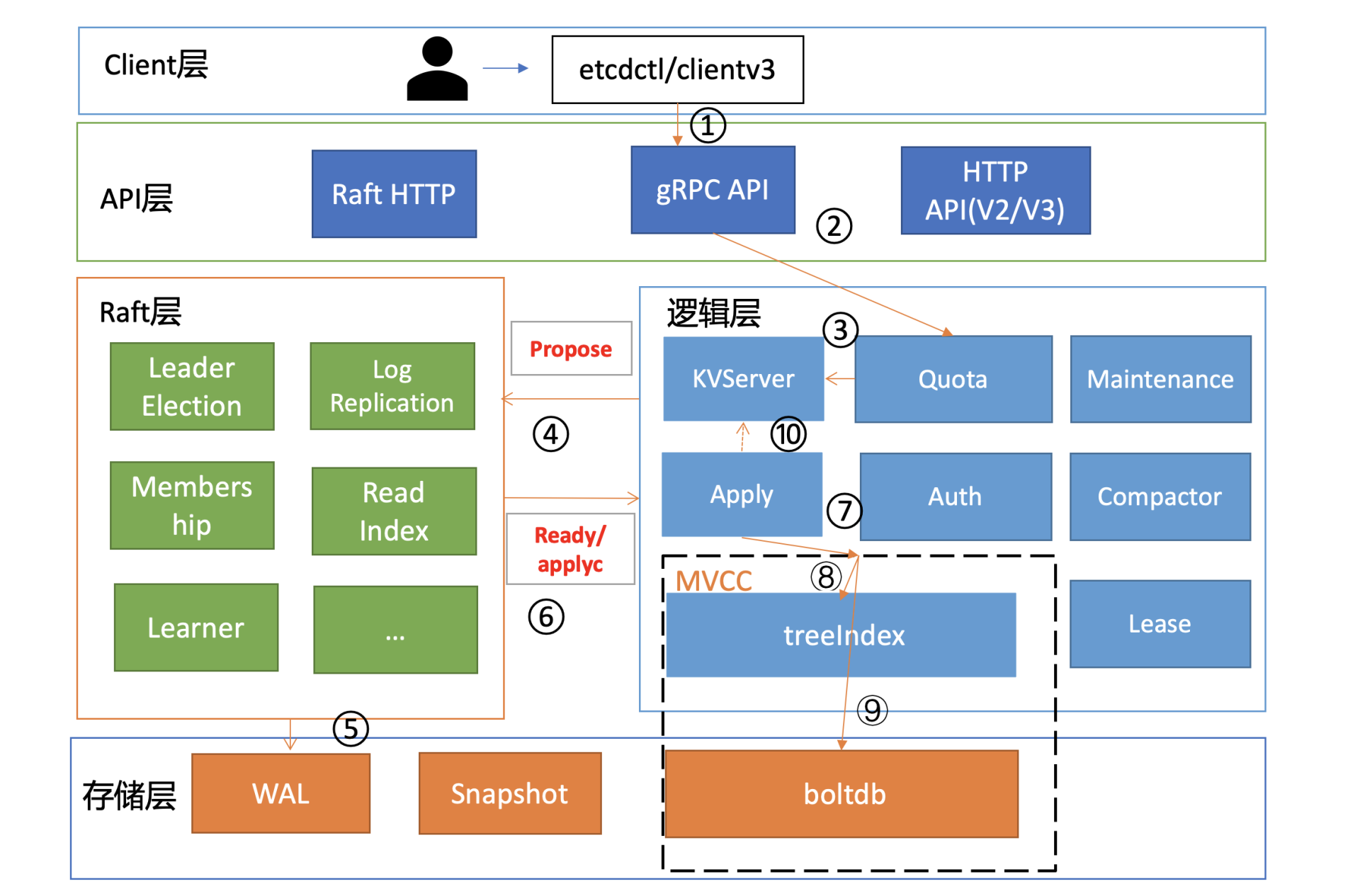
03 | 基础架构:etcd一个写请求是如何执行的?

该思维导图由 AI 生成,仅供参考
整体架构
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

etcd是一个分布式键值存储系统,本文深入分析了etcd的写请求执行流程和相关模块,为读者提供了全面的技术指导。文章首先介绍了etcd的整体架构和写请求的执行流程,重点讲解了Quota模块的作用和常见错误,并提供了解决方法。接着详细介绍了KVServer模块,包括Preflight Check和Propose两个关键步骤,以及超时处理。此外,文章还介绍了WAL模块和Apply模块,分别保证了集群的一致性和可恢复性,以及执行提案内容的幂等性和数据一致性。最后,通过讨论实际问题和解决方案,帮助读者深入了解etcd的写请求执行流程和相关模块,以及如何解决相关问题。总的来说,本文内容涵盖了技术细节和实际应用,对读者理解etcd的基础架构和写请求处理流程具有一定的指导意义。
《etcd 实战课》,新⼈⾸单¥59

全部留言(50)
- 最新
- 精选
 Index之前研究一段时间的etcd的源码,看的七七八八,现在再看这篇文章把之前的很多疑问都解答了,太棒了,etcd是个很优秀的项目,能把这么多的技术点融合在一起,实在是一个很好的开源学习项目。老师有空可以开直播,多聊聊etcd中涉及的技术点的一些学习,从源头上把知识融汇贯通,这样的学习真是酣畅淋漓
Index之前研究一段时间的etcd的源码,看的七七八八,现在再看这篇文章把之前的很多疑问都解答了,太棒了,etcd是个很优秀的项目,能把这么多的技术点融合在一起,实在是一个很好的开源学习项目。老师有空可以开直播,多聊聊etcd中涉及的技术点的一些学习,从源头上把知识融汇贯通,这样的学习真是酣畅淋漓作者回复: 好的,谢谢你的认可,一起学习加油
2021-01-2614 于途1)首先 boltdb key 是版本号,put/delete 操作时,都会基于当前版本号递增生成新的版本号,因此属于顺序写入,可以调整 boltdb 的 bucket.FillPercent 参数,使每个 page 填充更多数据,减少 page 的分裂次数并降低db空间。 此处的page 和 降低db空间不是很理解,劳烦老师解惑! 2)关于版本号(revision)的理解:假定全局版本号currentRevision=2,第一次执行 put hello world1,那么版本号为:hello:revision{2,0};第二次执行 put hello world2,此时版本号为:hello:revision{3,1};第3次执行 put hello world3,此时版本号为:hello:revision{4,2}。 不知理解是否有偏差?
于途1)首先 boltdb key 是版本号,put/delete 操作时,都会基于当前版本号递增生成新的版本号,因此属于顺序写入,可以调整 boltdb 的 bucket.FillPercent 参数,使每个 page 填充更多数据,减少 page 的分裂次数并降低db空间。 此处的page 和 降低db空间不是很理解,劳烦老师解惑! 2)关于版本号(revision)的理解:假定全局版本号currentRevision=2,第一次执行 put hello world1,那么版本号为:hello:revision{2,0};第二次执行 put hello world2,此时版本号为:hello:revision{3,1};第3次执行 put hello world3,此时版本号为:hello:revision{4,2}。 不知理解是否有偏差?作者回复: 第一个问题,10 boltdb篇会帮助你深入解答第1个问题,稍等 第二个问题,{2,0}={major,sub} 2是etcd mvcc事务版本号全局递增,0是事务内子版本号随修改操作递增(比如一个txn事务中多个put/delete操作,其会从0递增),因此第二次执行put hello world2的时候版本号应是{3,0}, 07 mvcc会详细介绍,明天更新
2021-01-2811 七里幂等部分的“原子性事务”如何实现的?
七里幂等部分的“原子性事务”如何实现的?作者回复: 就是key-value数据与consistent index在同一个boltdb事务中更新,boltdb后面会再单独介绍
2021-01-2627 TS.乔希望在后面多加一下具体设计思路,以及特性取舍的东西
TS.乔希望在后面多加一下具体设计思路,以及特性取舍的东西作者回复: 嗯,谢谢你的建议,篇幅本身比较长就没继续扩展了,比如读写原理中,treeindex为什么用b-tree而不是其他数据结构,为什么使用boltdb而不是基于lsm树的leveldb等,后面答疑和其他讲我将适当和大家一起讨论
2021-01-2627 jeffery原理讲的透彻、为啥applied index超过了 5000,返回一个"etcdserver: too many requests"错误给 client。raft源码定义的最大值吗?谢谢老师
jeffery原理讲的透彻、为啥applied index超过了 5000,返回一个"etcdserver: too many requests"错误给 client。raft源码定义的最大值吗?谢谢老师作者回复: 谢谢,这个限速不是raft模块做的,raft是个单独共识算法库,是etcd server使用raft的时候,基于raft告知的committed index,本身apply模块的applied index做的限速,默认写死了5000
2021-01-267- Geek_5a8405从节点收到Propose请求后会写wal日志吗?那如果最终并没有一半的节点成功响应,那已经写入wal的从节点怎么处理呢?
作者回复: 赞,阅读过程中有深入思考,你可以看看04节raft,其中思考题与你说的类似,05有参考答案
2021-02-105  憨憨讲的真好,干货十足
憨憨讲的真好,干货十足作者回复: 感谢认可😊
2021-02-044 花晨少年etcd 通过引入一个 consistent index 的字段,来存储系统当前已经执行过的日志条目索引,实现幂等性。 ----- consistent index 是一个全局的值吗,单调递增的?还是主要有raft日志应用到状态机,就会存储当前consistent index值吗,判断日志使用已经执行过,是需要进行key查找所有存储的consistent index值吗
花晨少年etcd 通过引入一个 consistent index 的字段,来存储系统当前已经执行过的日志条目索引,实现幂等性。 ----- consistent index 是一个全局的值吗,单调递增的?还是主要有raft日志应用到状态机,就会存储当前consistent index值吗,判断日志使用已经执行过,是需要进行key查找所有存储的consistent index值吗作者回复: 对,是一个全局单调递增的值,在boltdb中有一个key维护它,etcdserver应用已提交的raft日志条目到状态机时,会查询此日志条目的索引是否大于consistent index,如果大于则同key-value等数据在同boltdb事务中更新它,否则说明此日志条目已执行过。
2021-04-173 kingstone请问revision如果超出了上限,revision会如何接着生成?
kingstone请问revision如果超出了上限,revision会如何接着生成?作者回复: 好问题,目前etcd没处理这种情况,它的类似是int64,最大值9223372036854775807,看起来是很难达到上限的
2021-01-263- typesApply模块针对写请求,是串行执行的还是并发执行的?
作者回复: 串行
2021-09-172

