

03 | 分组与引用:如何用正则实现更复杂的查找和替换操作?
涂伟忠

该思维导图由 AI 生成,仅供参考
你好,我是伟忠。今天我打算和你聊聊分组与引用。那什么场合下会用到分组呢?
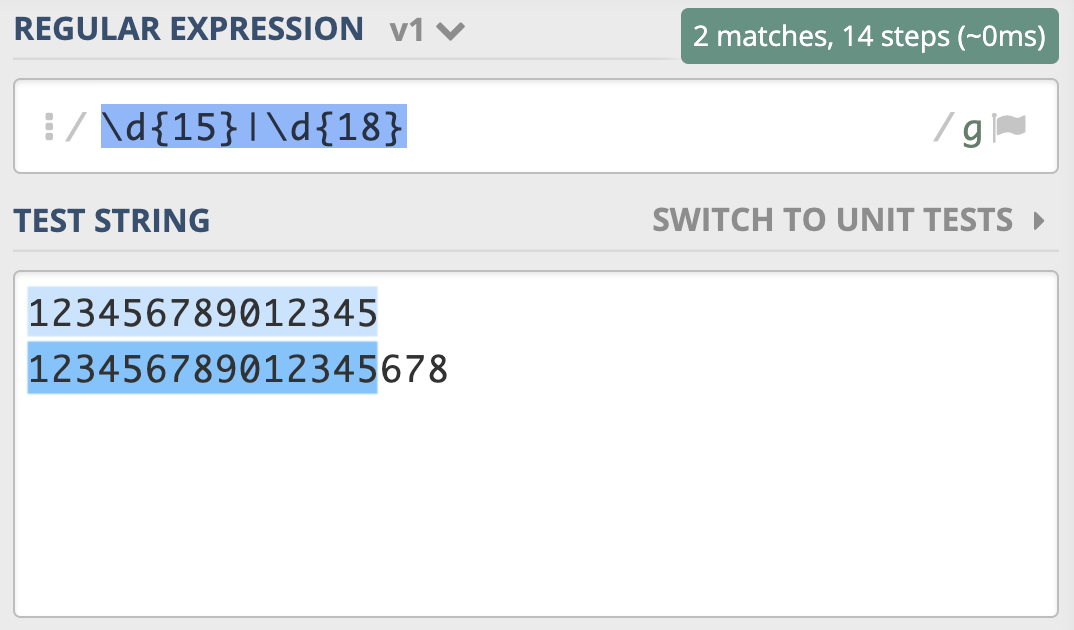
假设我们现在要去查找 15 位或 18 位数字。根据前面学习的知识,使用量词可以表示出现次数,使用管道符号可以表示多个选择,你应该很快就能写出\d{15}|\d{18}。但经过测试,你会发现,这个正则并不能很好地完成任务,因为 18 位数字也会匹配上前 15 位,具体如下图所示。
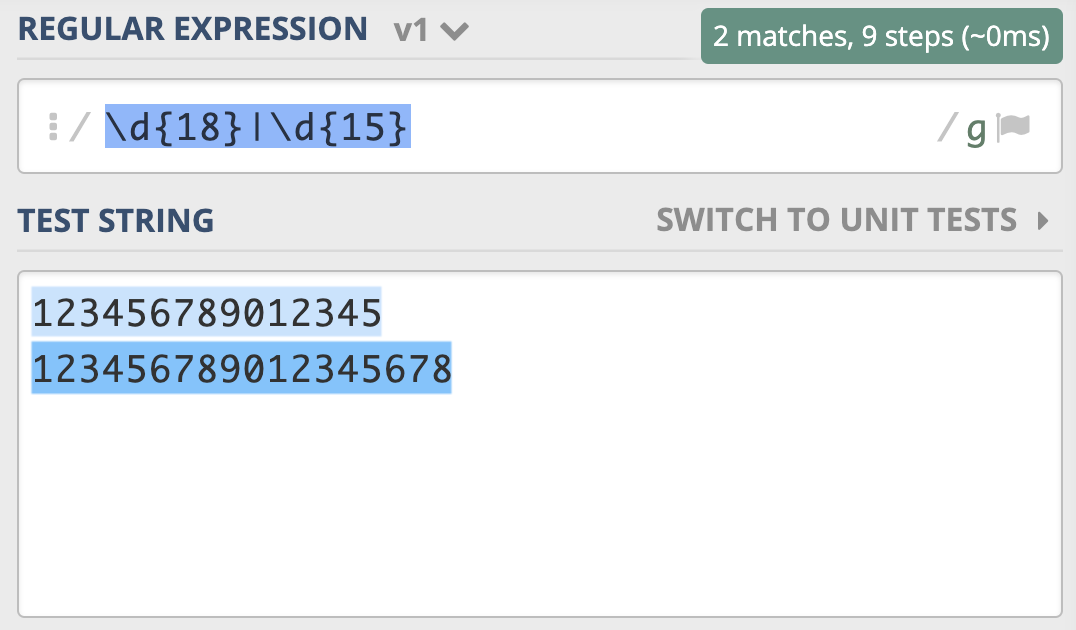
为了解决这个问题,你灵机一动,很快就想到了办法,就是把 15 和 18 调换顺序,即写成 \d{18}|\d{15}。你发现,这回符合要求了。
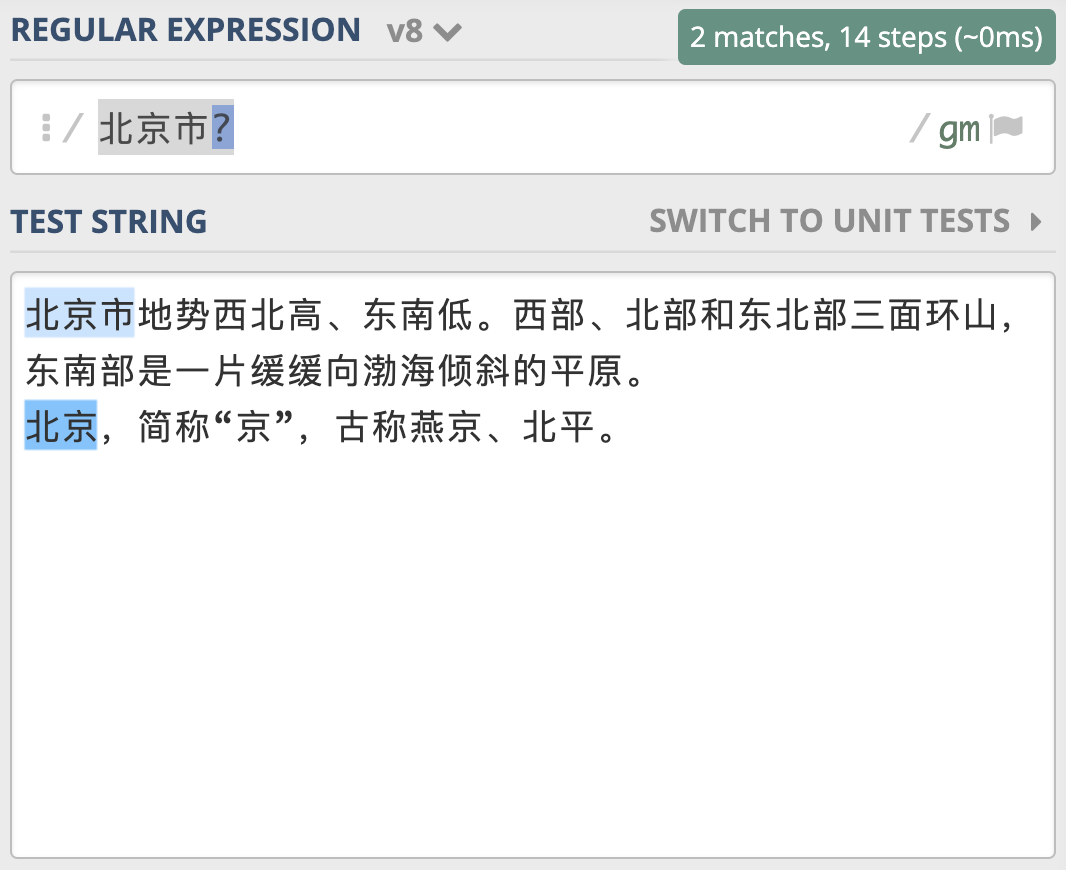
为什么会出现这种情况呢?因为在大多数正则实现中,多分支选择都是左边的优先。类似地,你可以使用 “北京市|北京” 来查找 “北京” 和 “北京市”。另外我们前面学习过,问号可以表示出现 0 次或 1 次,你发现可以使用“北京市?” 来实现来查找 “北京” 和 “北京市”。
同样,针对 15 或 18 位数字这个问题,可以看成是 15 位数字,后面 3 位数据有或者没有,你应该很快写出了 \d{15}\d{3}? 。但这样写对不对呢?我们来看一下。
在上一节我们学习了量词后面加问号表示非贪婪,而我们现在想要的是 \d{3} 出现 0 次或 1 次。
示例一:
\d{15}\d{3}? 由于 \d{3} 表示三次,加问号非贪婪还是 3 次
公开
同步至部落
取消
完成
0/2000
 荧光笔
荧光笔 直线
直线 曲线
曲线笔记
复制
AI
- 深入了解
- 翻译
- 解释
- 总结

本文深入介绍了如何使用正则表达式实现更复杂的查找和替换操作。作者首先讲解了分组与引用的概念,指出在多分支选择中左边的优先,并且介绍了问号的使用。然后详细讲解了分组与编号、不保存子组、括号嵌套以及命名分组的使用方法。接着,作者介绍了分组引用在查找和替换中的应用,以及在常见编程语言中的引用方式。最后,作者以Python3为例,给出了在编程语言中实现分组查找和替换的示例,并介绍了在文本编辑器Sublime Text 3中使用正则表达式进行查找和替换的方法。整体来说,本文内容涵盖了正则表达式的基本概念和高级应用,适合读者快速了解并掌握正则表达式的相关知识。文章还提供了在编辑器中进行正则替换的示例,以及课后思考的小练习,帮助读者更好地掌握学习的内容。通过本文,读者可以学习到如何利用正则表达式进行复杂文本的查找和替换工作,甚至在使用文本编辑器时节约开发时间。
仅可试看部分内容,如需阅读全部内容,请付费购买文章所属专栏
《正则表达式入门课》,新⼈⾸单¥59
《正则表达式入门课》,新⼈⾸单¥59
立即购买
© 版权归极客邦科技所有,未经许可不得传播售卖。 页面已增加防盗追踪,如有侵权极客邦将依法追究其法律责任。

登录 后留言
全部留言(96)
- 最新
- 精选
 前端路上的小学生思考题答案是: (\w+)(\s+\1)+ 解题的思路是:\w+ 用于选中出现一次到多次的字母,由于默认贪婪匹配最长,所以能选中每个单词,由于是要找出重复的单词,所以要用第一次匹配成功的结果即使用分组 (\w+) \1,到此可以拿到重复两次场景的结果,对于重复两次以上的结果,需要重复刚刚的行为,但是不能一直叠加 \1 ,自然想到了 +,得到了 (\w+) (\1)+,发现匹配不成功,在这里卡壳了一段时间没想明白,翻到别人的答案才猛然想起来单词之间应该有空隙,(\1)+不能表示空隙,用\s代替敲出来的空格最终得到 (\w+)(\s+\1)+ 晚上比较晚了脑子转不动了
前端路上的小学生思考题答案是: (\w+)(\s+\1)+ 解题的思路是:\w+ 用于选中出现一次到多次的字母,由于默认贪婪匹配最长,所以能选中每个单词,由于是要找出重复的单词,所以要用第一次匹配成功的结果即使用分组 (\w+) \1,到此可以拿到重复两次场景的结果,对于重复两次以上的结果,需要重复刚刚的行为,但是不能一直叠加 \1 ,自然想到了 +,得到了 (\w+) (\1)+,发现匹配不成功,在这里卡壳了一段时间没想明白,翻到别人的答案才猛然想起来单词之间应该有空隙,(\1)+不能表示空隙,用\s代替敲出来的空格最终得到 (\w+)(\s+\1)+ 晚上比较晚了脑子转不动了作者回复: 哈哈,写完了要动手试一试才知道能不能用,感谢分享。
2020-06-18521 ElliON先讲一讲(\w+) \1 为什么这能匹配出来连续重复字符? (\w+)代表分组,此时只有一个分组,“\1”代表第一个分组的内容 于是,该正则意思是:某单词+空格+某单词,这样就实现了连续重复单词的匹配 (\w+)( \1)+
ElliON先讲一讲(\w+) \1 为什么这能匹配出来连续重复字符? (\w+)代表分组,此时只有一个分组,“\1”代表第一个分组的内容 于是,该正则意思是:某单词+空格+某单词,这样就实现了连续重复单词的匹配 (\w+)( \1)+作者回复: 对的
2020-07-07311 Zion W.综合了大家的以后写出的 查找:/(\b\w+)(?:\s+\1)+/g 替换:\1
Zion W.综合了大家的以后写出的 查找:/(\b\w+)(?:\s+\1)+/g 替换:\1作者回复: 没问题,多看大家的答案有时候会有意想不到的收获
2020-06-2838
 William老师,纠正一个错误。 JavaScript中,查找时必须用 \ 引用,替换时用 $。 node 和 Chrome中均是这样,查找时用 $ 无效。 let str = `the little cat cat is in the hat hat hat, we like it.` let res = str.replace(/(\w+)(\s$1)+/g, '$1') console.log(res)
William老师,纠正一个错误。 JavaScript中,查找时必须用 \ 引用,替换时用 $。 node 和 Chrome中均是这样,查找时用 $ 无效。 let str = `the little cat cat is in the hat hat hat, we like it.` let res = str.replace(/(\w+)(\s$1)+/g, '$1') console.log(res)作者回复: 感谢指出,我更正下
2020-06-2357 Robot课后思考: /(\b\w+)(\s\1)+/g
Robot课后思考: /(\b\w+)(\s\1)+/g作者回复: 赞,一看就是有经验,断言单词边界都用上了
2020-06-1836 furuhata课后思考题: 正则:(\w+)(\s\1)+ 替换:\1
furuhata课后思考题: 正则:(\w+)(\s\1)+ 替换:\1作者回复: 没问题
2020-06-1736 虹炎(\w+) (\s+\1)+ \1 我的答案。连续出现多次单词,可能有多个空格,所以用了\s+
虹炎(\w+) (\s+\1)+ \1 我的答案。连续出现多次单词,可能有多个空格,所以用了\s+作者回复: 赞,考虑的很全面
2020-06-172 Johnson正则查找部分:(\w+)(.\1)+ 正则替换部分:\1 初学者学习中,请老师多多指教。
Johnson正则查找部分:(\w+)(.\1)+ 正则替换部分:\1 初学者学习中,请老师多多指教。作者回复: 没问题,空格可以用\s,尽量不用点,因为匹配的内容不精确。
2020-06-172 JuntíngJavaScript 使用引用编号查找时, \number 和 $number 两者引用方式都可以,替换时用的是 $number 的方式。regex101 网站上 ECMAScript 模式下查找引用方式 $number 就不能使用了。 let reg = /(\w+) \1/gm; let reg1 = /(\w+) $1/gm; 'the little cat cat is in the hat hat, we like it.'.replace(reg, '$1'); 'the little cat cat is in the hat hat, we like it.'.replace(reg1, '$1');
JuntíngJavaScript 使用引用编号查找时, \number 和 $number 两者引用方式都可以,替换时用的是 $number 的方式。regex101 网站上 ECMAScript 模式下查找引用方式 $number 就不能使用了。 let reg = /(\w+) \1/gm; let reg1 = /(\w+) $1/gm; 'the little cat cat is in the hat hat, we like it.'.replace(reg, '$1'); 'the little cat cat is in the hat hat, we like it.'.replace(reg1, '$1');作者回复: 动手练习点赞,感谢分享
2020-06-1831 唐龙匹配:`<(\w+)(?:\s\1)+>` 替换:`\1` 顺便吐槽一下vim末行模式的正则,可读性贼差,它有些符号要在前面加上反斜杠`\`,还有一些细节也不太一样。最后写完了大概长这样: ```:%s/\<\(\w\+\)\%(\s\1\)\+\>/\1/g``` 前两个正斜杠`/`中间的是匹配的内容,后两个正斜杠`/`中间的是替换后的内容。 其中`\%(`表示`(?:`,其余的就是各种符号要多一个反斜杠`\`,脑阔痛。
唐龙匹配:`<(\w+)(?:\s\1)+>` 替换:`\1` 顺便吐槽一下vim末行模式的正则,可读性贼差,它有些符号要在前面加上反斜杠`\`,还有一些细节也不太一样。最后写完了大概长这样: ```:%s/\<\(\w\+\)\%(\s\1\)\+\>/\1/g``` 前两个正斜杠`/`中间的是匹配的内容,后两个正斜杠`/`中间的是替换后的内容。 其中`\%(`表示`(?:`,其余的就是各种符号要多一个反斜杠`\`,脑阔痛。作者回复: 感谢分享,多加练习才能更好地掌握。 转义确实非常让人头痛,很麻烦
2020-06-1731
收起评论