

02丨量词与贪婪:小小的正则,也可能把CPU拖垮!

该思维导图由 AI 生成,仅供参考
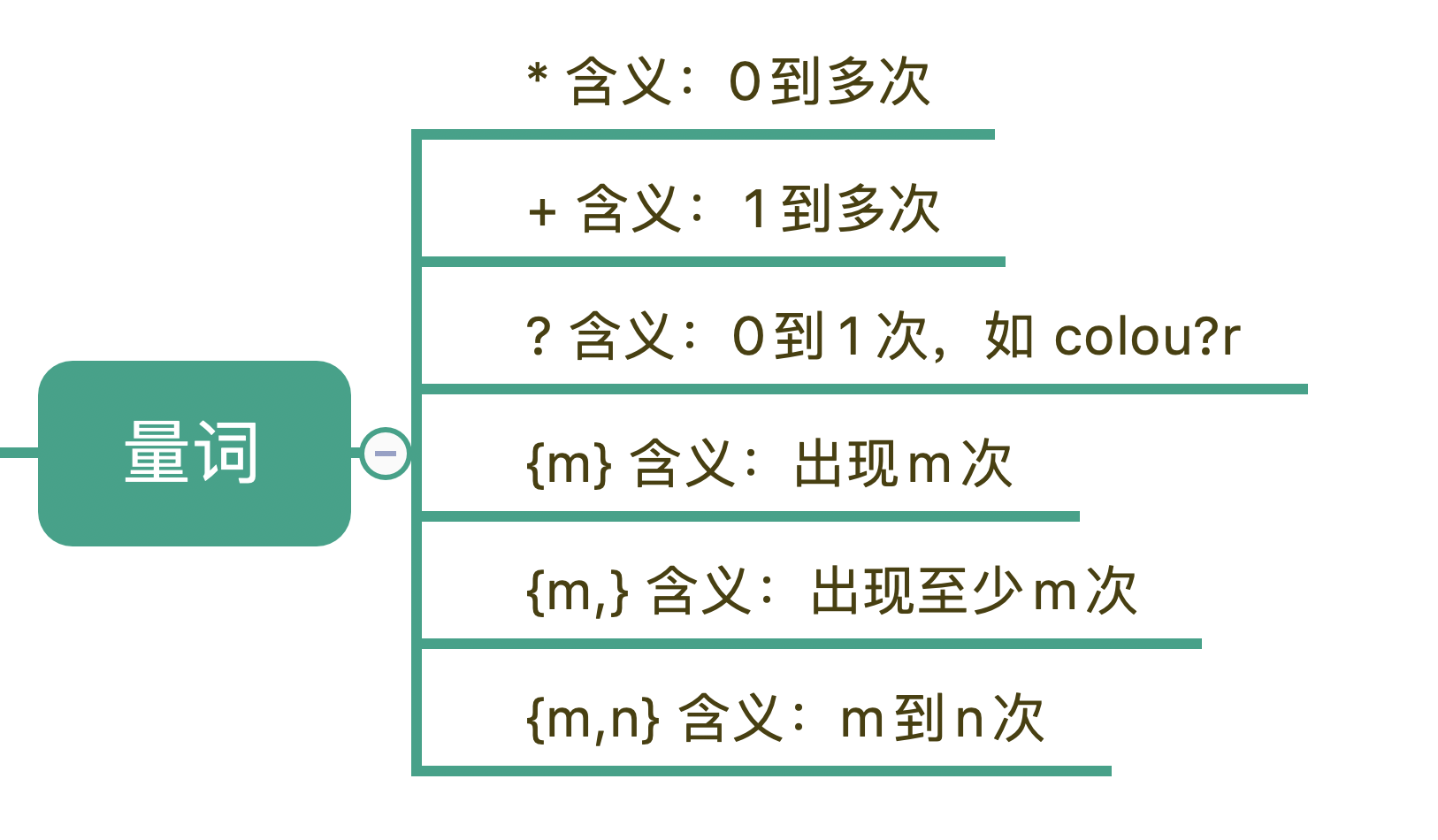
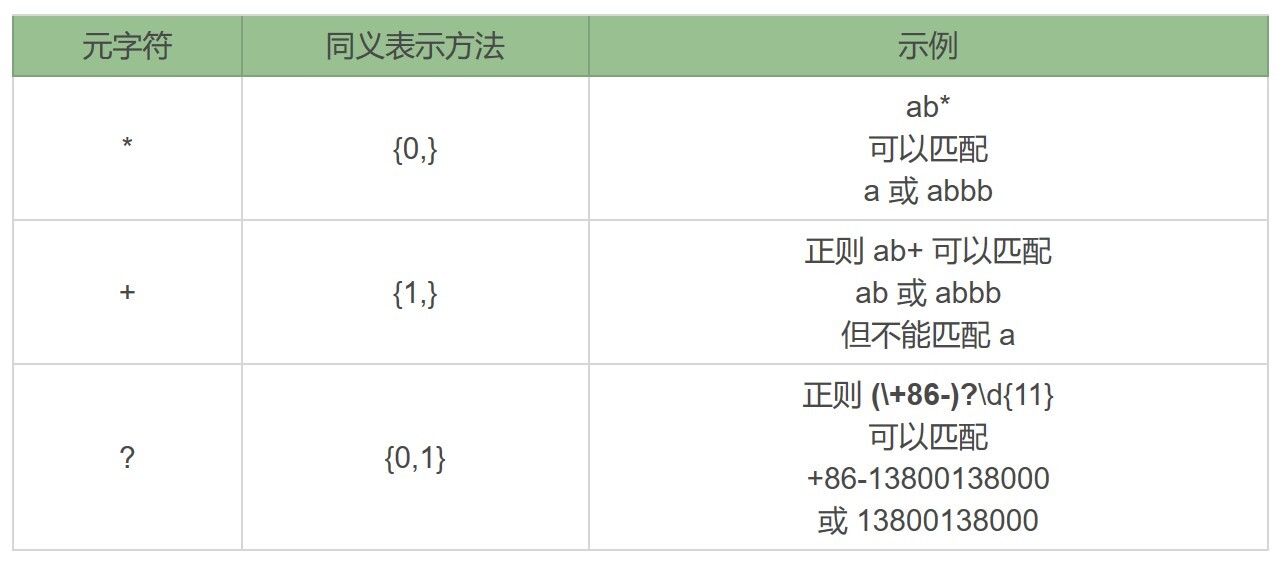
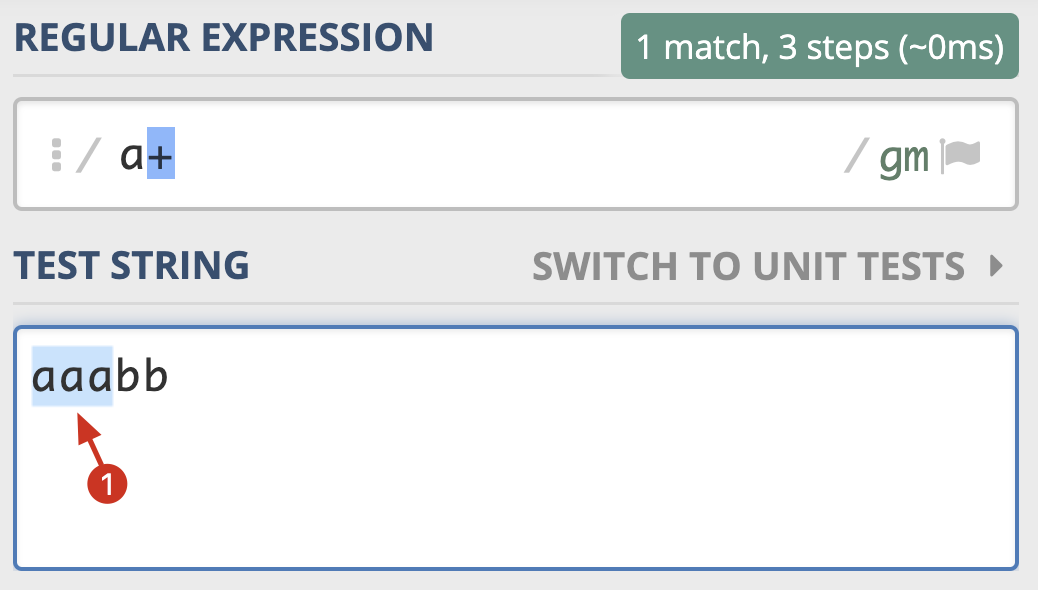
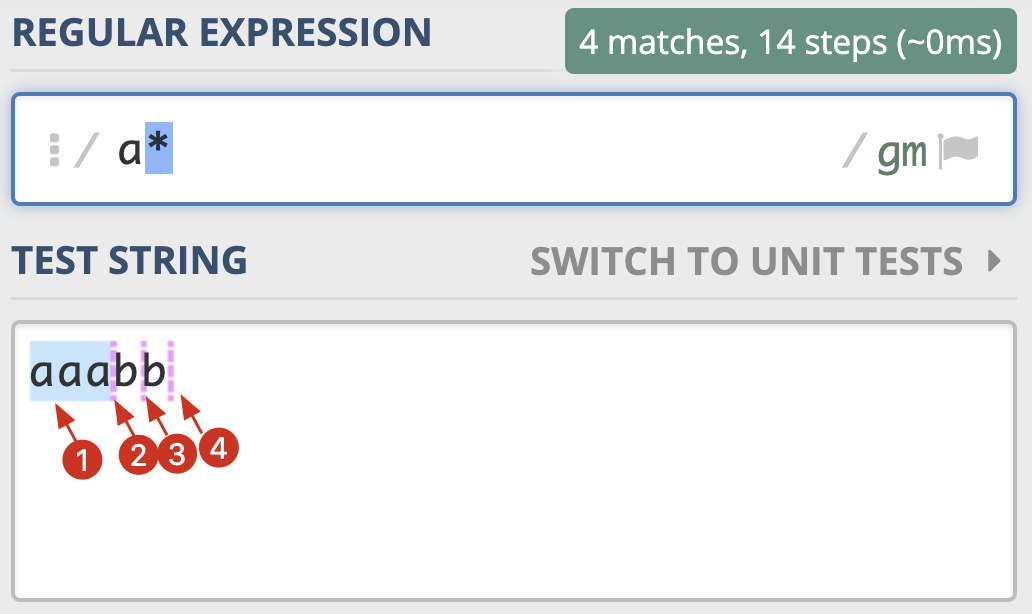
为什么会有贪婪与非贪婪模式?
 荧光笔
荧光笔 直线
直线 曲线
曲线- 深入了解
- 翻译
- 解释
- 总结

正则表达式在编程中扮演着重要角色,但在使用过程中可能遇到贪婪匹配、非贪婪匹配和独占模式等问题。本文深入介绍了这三种模式的概念和使用方法,以及它们在正则表达式中的作用。贪婪匹配追求最大长度匹配,而非贪婪匹配则寻求最短匹配。另外,独占模式在匹配过程中不会发生回溯,因此在某些情况下性能更佳。文章通过具体示例和代码演示了这三种模式的使用方法和效果,帮助读者更好地理解和掌握正则表达式中的量词匹配行为。同时,还提到了一些语言和库对独占模式的支持情况,让读者了解在实际应用中需要考虑的因素。通过本文的总结,读者可以快速了解正则表达式中贪婪匹配、非贪婪匹配和独占模式的特点和用法,为他们在实际编程中更好地应用正则表达式提供了指导和帮助。文章深入浅出,通过实例和技术讨论,使读者对正则表达式的匹配行为有了更清晰的认识,为他们在实际编程中更好地应用正则表达式提供了指导和帮助。
《正则表达式入门课》,新⼈⾸单¥59

全部留言(135)
- 最新
- 精选
 Geek.S.以前只知道贪婪模式和懒惰模式,原来还有一个独占模式,贪婪和非贪婪都会发生回溯,结合文中给的案例链接,知道了 NFA 和 DFA (这个老师应该在后面讲匹配原理时会讲到)。难怪余晟老师说学会正则后务必要学会克制。 如果只是判断文本是否符合规则,则可以使用独占模式; 如果需要获取匹配的结果,则根据需要使用贪婪或非贪婪。 作业题: (这里需要获取单词,不能使用独占模式) \w+|“[^”]+” (注意: 例句中的双引号是中文状态下的) 结果(10 次匹配, 48 步): ['we', 'found', '"the little cat"', 'is', 'in', 'the', 'hat', 'we', 'like', '"the little cat"'] 相应的 Python 代码: >>> import re >>> text = '''we found “the little cat” is in the hat, we like “the little cat”''' # 注意: 例句中的双引号是中文状态下的 >>> pattern = re.compile(r'''\w+|“[^”]+”''') >>> pattern.findall(text) ['we', 'found', '"the little cat"', 'is', 'in', 'the', 'hat', 'we', 'like', '"the little cat"'] 示例: https://regex101.com/r/l8hkqi/1
Geek.S.以前只知道贪婪模式和懒惰模式,原来还有一个独占模式,贪婪和非贪婪都会发生回溯,结合文中给的案例链接,知道了 NFA 和 DFA (这个老师应该在后面讲匹配原理时会讲到)。难怪余晟老师说学会正则后务必要学会克制。 如果只是判断文本是否符合规则,则可以使用独占模式; 如果需要获取匹配的结果,则根据需要使用贪婪或非贪婪。 作业题: (这里需要获取单词,不能使用独占模式) \w+|“[^”]+” (注意: 例句中的双引号是中文状态下的) 结果(10 次匹配, 48 步): ['we', 'found', '"the little cat"', 'is', 'in', 'the', 'hat', 'we', 'like', '"the little cat"'] 相应的 Python 代码: >>> import re >>> text = '''we found “the little cat” is in the hat, we like “the little cat”''' # 注意: 例句中的双引号是中文状态下的 >>> pattern = re.compile(r'''\w+|“[^”]+”''') >>> pattern.findall(text) ['we', 'found', '"the little cat"', 'is', 'in', 'the', 'hat', 'we', 'like', '"the little cat"'] 示例: https://regex101.com/r/l8hkqi/1作者回复: 对的,务必克制,搞懂原理才能用的更好。 答案是对的👍🏻
2020-06-15946 奕老师,对于文中的这个语句 regex.findall(r'xy{1,3}+z', 'xyyz') 这里是独占模式,不进行回溯。这里在尽可能多的匹配第三个 y的时候匹配失败,不应该是直接匹配失败 返回空数组吗? 怎么是返回 xyyz 呢? 如果返回 xyyz 不就进行回溯了吗?
奕老师,对于文中的这个语句 regex.findall(r'xy{1,3}+z', 'xyyz') 这里是独占模式,不进行回溯。这里在尽可能多的匹配第三个 y的时候匹配失败,不应该是直接匹配失败 返回空数组吗? 怎么是返回 xyyz 呢? 如果返回 xyyz 不就进行回溯了吗?作者回复: y出现一到三次,匹配量词以后,没有y了,就接着用正则中的z去匹配,没有回溯。如果+后面还有个y就会匹配不上,如果是贪婪或非贪婪就可以匹配上。 独占模式不回溯这个说法其实不够准确,可以理解成“独占模式不会交还已经匹配上的字符”,这样应该就能理解了。 独占模式比较复杂,实际场景中用的其实不多,先了解就好了
2020-06-15517 BillionY\w+|“[^”]*” \w+|“[\w\s]+? \w+|“.+?” 还有第四种方法吗?
BillionY\w+|“[^”]*” \w+|“[\w\s]+? \w+|“.+?” 还有第四种方法吗?作者回复: 建议第一种,写得方式有很多,但思路都是一样的
2020-06-15613 苦行僧w+|“[^”]+”, w+ 看懂了, 但 后面的没看懂?
苦行僧w+|“[^”]+”, w+ 看懂了, 但 后面的没看懂?作者回复: 引号里面是非引号出现一到多次
2020-08-1337
 Williamjs版 ```javascript let str = `we found "the little cat" is in the hat, we like "the little cat"` let re = new RegExp(/"[^"]+"|\w+/, 'g') let res = str.match(re) console.log(res) ```
Williamjs版 ```javascript let str = `we found "the little cat" is in the hat, we like "the little cat"` let re = new RegExp(/"[^"]+"|\w+/, 'g') let res = str.match(re) console.log(res) ```作者回复: 没问题,认真学习的同学,赞,多动手练习才能更好地掌握
2020-06-235- pyhhou思考题: ".+?"|[^\s|,]+ 关于回溯,是不是就是递归调用函数栈的原理?拿 xy{1,3}z 匹配 xyyz 举例,步骤如下: 1. 正则中的 x 入栈,匹配上 text 的第一个字符 x 2. 正则中的 y 入栈,匹配上 text 中的第二个字符 y 3. 因为这里没有加问号,属于贪婪匹配,正则中的 y 继续入栈,匹配上 text 中的第三个字符 y 4. 正则中的 y 继续入栈,但是这个时候 y 和 z 不匹配,执行回溯,就是当前正则的第三个 y 出栈 5. 用范围量词后的字符 z 继续入栈匹配,匹配上 text 的最后一个字符,完成匹配
作者回复: 👍🏻思路很新颖,你说的是匹配的过程,并不是回溯的过程,正则回溯是基于状态机的
2020-06-155  Robot建议老师统一下正则的运行环境。
Robot建议老师统一下正则的运行环境。作者回复: 文章中用的都是Python3,毕竟2已经不维护了
2020-06-164 飞[a-z]+|“[^“]+”
飞[a-z]+|“[^“]+”作者回复: 思路没问题,可以再考虑下单词中有大写字母呢?尽量考虑全面些
2020-06-1523 中年男子还有就是文章中的例子: xy{1,3}+yz 去匹配 xyyz,我的理解是用y{1,3}尽可能多的去匹配, 也就是 xyy之后,用第三个y 去匹配z,因为不回溯,到这里就失败了, 还没到正则中z前面那个y。 还请解惑。
中年男子还有就是文章中的例子: xy{1,3}+yz 去匹配 xyyz,我的理解是用y{1,3}尽可能多的去匹配, 也就是 xyy之后,用第三个y 去匹配z,因为不回溯,到这里就失败了, 还没到正则中z前面那个y。 还请解惑。作者回复: y一到三次独占模式,虽然只匹配到了两个,但还是满足了次数要求,这时候没失败,继续看下一个,后面的y匹配不上z才失败的
2020-06-153 简简单单老师我有个疑问求解答: 正则: \w+|“.+?” 字符串 : we found “the little cat” is in the hat, we like “the little cat” 结果的确是把每个单词单独匹配到了, 并且 引号的也当成一个单词了, 那么请问 为什么 \w+ 不会把 引号内的单词匹配到呢, 为什么不会出现 the 与 “the little cat” 共存呢 正则匹配的过程是怎么样的 ?
简简单单老师我有个疑问求解答: 正则: \w+|“.+?” 字符串 : we found “the little cat” is in the hat, we like “the little cat” 结果的确是把每个单词单独匹配到了, 并且 引号的也当成一个单词了, 那么请问 为什么 \w+ 不会把 引号内的单词匹配到呢, 为什么不会出现 the 与 “the little cat” 共存呢 正则匹配的过程是怎么样的 ?作者回复: 引号也匹配上可以用断言解决。 不会共存可以看看后面的匹配原理部分,一个分支能匹配上就不会看另在一个分支,如果失败了看另外一个分支
2020-07-2132